 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Multiple Sequence Decoding
Paper and Code

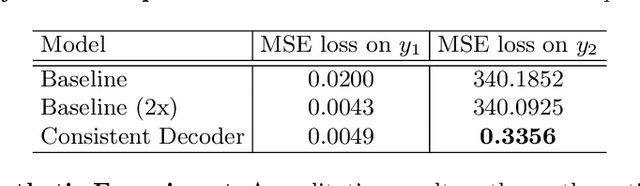
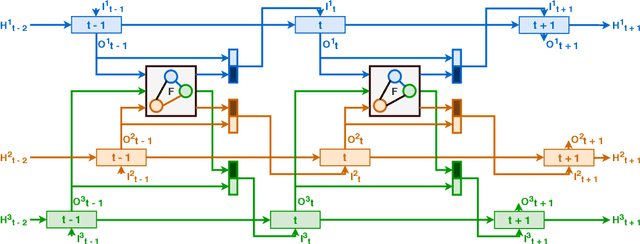

Sequence decoding is one of the core components of most visual-lingual models. However, typical neural decoders when faced with decoding multiple, possibly correlated, sequences of tokens resort to simple independent decoding schemes. In this paper, we introduce a consistent multiple sequence decoding architecture, which is while relatively simple, is general and allows for consistent and simultaneous decoding of an arbitrary number of sequences. Our formulation utilizes a consistency fusion mechanism, implemented using message passing in a Graph Neural Network (GNN), to aggregate context from related decoders. This context is then utilized as a secondary input, in addition to previously generated output, to make a prediction at a given step of decoding. Self-attention, in the GNN, is used to modulate the fusion mechanism locally at each node and each step in the decoding process. We show the efficacy of our consistent multiple sequence decoder on the task of dense relational image captioning and illustrate state-of-the-art performance (+ 5.2% in mAP) on the task. More importantly, we illustrate that the decoded sentences, for the same regions, are more consistent (improvement of 9.5%), while across images and regions maintain diversity.