 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning
Jun 12, 2024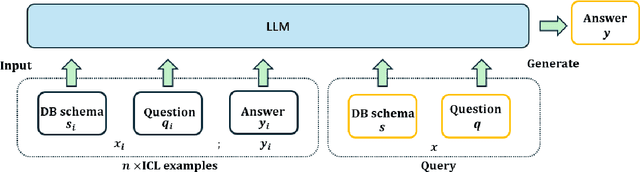

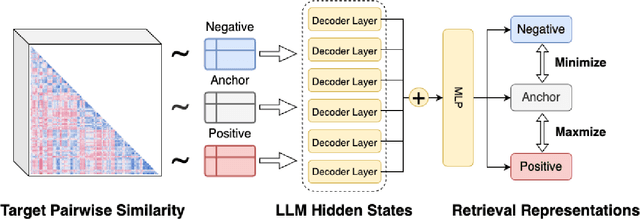

While in-context Learning (ICL) has proven to be an effective technique to improve the performance of Large Language Models (LLMs) in a variety of complex tasks, notably in translating natural language questions into Structured Query Language (NL2SQL), the question of how to select the most beneficial demonstration examples remains an open research problem. While prior works often adapted off-the-shelf encoders to retrieve examples dynamically, an inherent discrepancy exists in the representational capacities between the external retrievers and the LLMs. Further, optimizing the selection of examples is a non-trivial task, since there are no straightforward methods to assess the relative benefits of examples without performing pairwise inference. To address these shortcomings, we propose DeTriever, a novel demonstration retrieval framework that learns a weighted combination of LLM hidden states, where rich semantic information is encoded. To train the model, we propose a proxy score that estimates the relative benefits of examples based on the similarities between output queries. Experiments on two popular NL2SQL benchmarks demonstrate that our method significantly outperforms the state-of-the-art baselines on one-shot NL2SQL tasks.
SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder
Mar 24, 2024
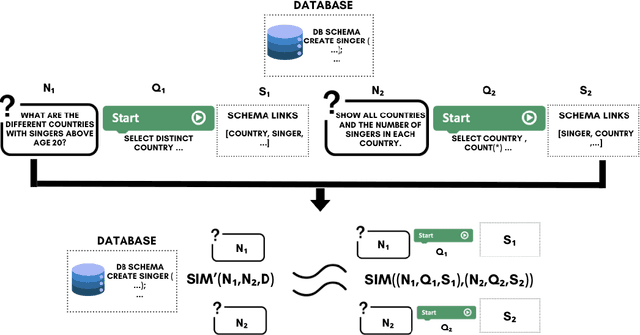
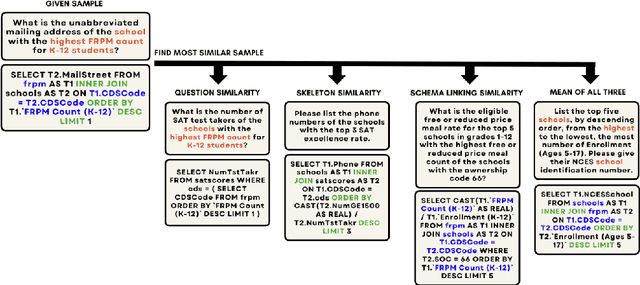

Detecting structural similarity between queries is essential for selecting examples in in-context learning models. However, assessing structural similarity based solely on the natural language expressions of queries, without considering SQL queries, presents a significant challenge. This paper explores the significance of this similarity metric and proposes a model for accurately estimating it. To achieve this, we leverage a dataset comprising 170k question pairs, meticulously curated to train a similarity prediction model. Our comprehensive evaluation demonstrates that the proposed model adeptly captures the structural similarity between questions, as evidenced by improvements in Kendall-Tau distance and precision@k metrics. Notably, our model outperforms strong competitive embedding models from OpenAI and Cohere. Furthermore, compared to these competitive models, our proposed encoder enhances the downstream performance of NL2SQL models in 1-shot in-context learning scenarios by 1-2\% for GPT-3.5-turbo, 4-8\% for CodeLlama-7B, and 2-3\% for CodeLlama-13B.
KEST: Kernel Distance Based Efficient Self-Training for Improving Controllable Text Generation
Jun 17, 2023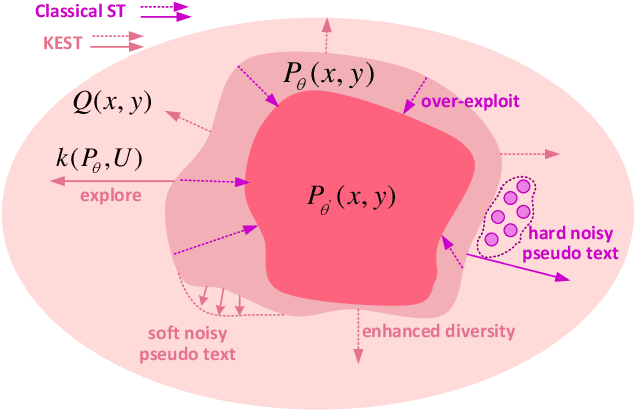
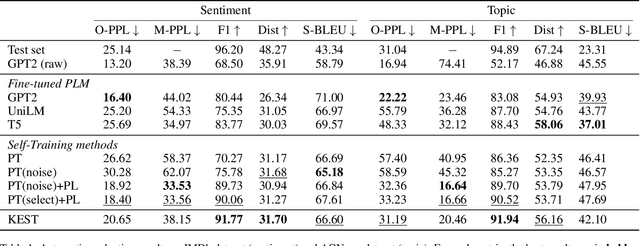
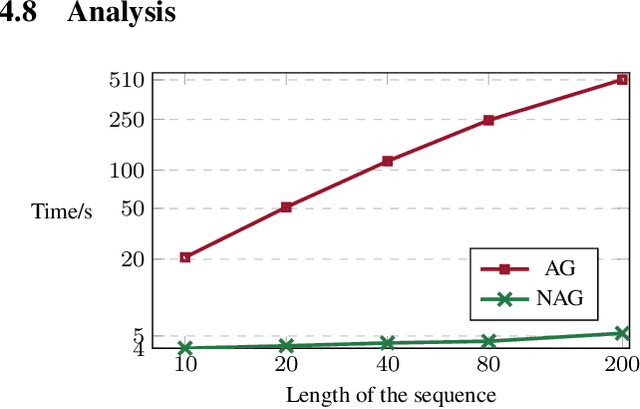
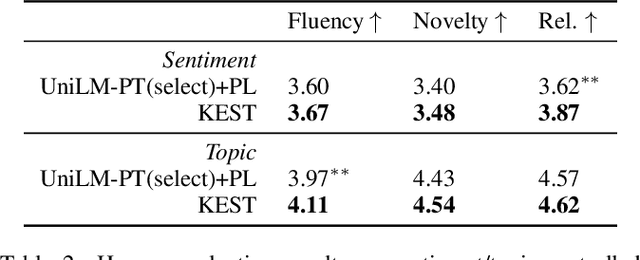
Self-training (ST) has come to fruition in language understanding tasks by producing pseudo labels, which reduces the labeling bottleneck of language model fine-tuning. Nevertheless, in facilitating semi-supervised controllable language generation, ST faces two key challenges. First, augmented by self-generated pseudo text, generation models tend to over-exploit the previously learned text distribution, suffering from mode collapse and poor generation diversity. Second, generating pseudo text in each iteration is time-consuming, severely decelerating the training process. In this work, we propose KEST, a novel and efficient self-training framework to handle these problems. KEST utilizes a kernel-based loss, rather than standard cross entropy, to learn from the soft pseudo text produced by a shared non-autoregressive generator. We demonstrate both theoretically and empirically that KEST can benefit from more diverse pseudo text in an efficient manner, which allows not only refining and exploiting the previously fitted distribution but also enhanced exploration towards a larger potential text space, providing a guarantee of improved performance. Experiments on three controllable generation tasks demonstrate that KEST significantly improves control accuracy while maintaining comparable text fluency and generation diversity against several strong baselines.
DuNST: Dual Noisy Self Training for Semi-Supervised Controllable Text Generation
Dec 16, 2022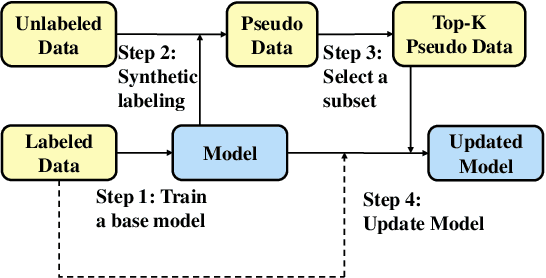
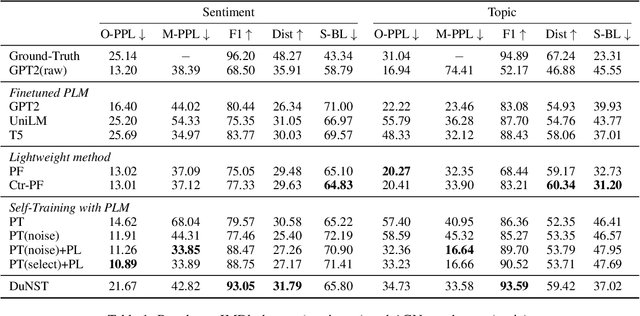
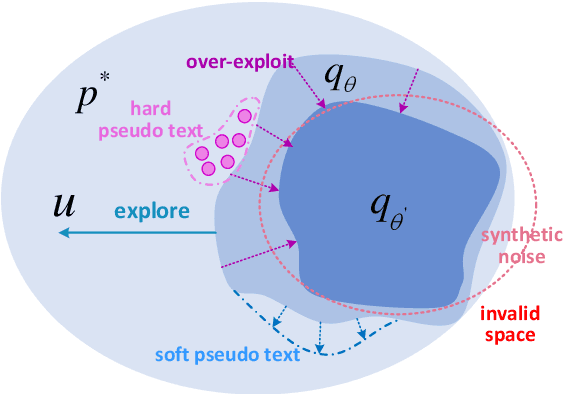
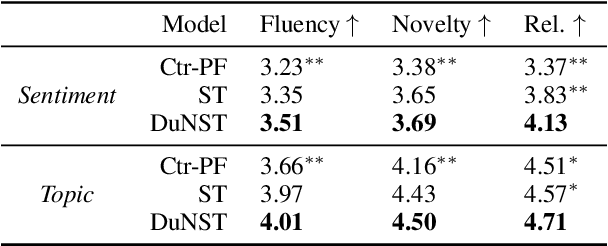
Self-training (ST) has prospered again in language understanding by augmenting the fine-tuning of pre-trained language models when labeled data is insufficient. However, it remains challenging to incorporate ST into attribute-controllable language generation. Augmented by only self-generated pseudo text, generation models over-emphasize exploitation of the previously learned space, suffering from a constrained generalization boundary. We revisit ST and propose a novel method, DuNST to alleviate this problem. DuNST jointly models text generation and classification with a shared Variational AutoEncoder and corrupts the generated pseudo text by two kinds of flexible noise to disturb the space. In this way, our model could construct and utilize both pseudo text from given labels and pseudo labels from available unlabeled text, which are gradually refined during the ST process. We theoretically demonstrate that DuNST can be regarded as enhancing exploration towards the potential real text space, providing a guarantee of improved performance. Experiments on three controllable generation tasks show that DuNST could significantly boost control accuracy while maintaining comparable generation fluency and diversity against several strong baselines.