 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Asynchronous Cooperation with Hierarchical Reinforcement Learning
Paper and Code
Mar 29, 2022


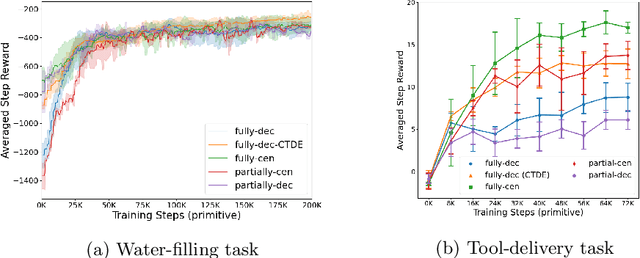
Hierarchical multi-agent reinforcement learning (MARL) has shown a significant learning efficiency by searching policy over higher-level, temporally extended actions (options). However, standard policy gradient-based MARL methods have a difficulty generalizing to option-based scenarios due to the asynchronous executions of multi-agent options. In this work, we propose a mathematical framework to enable policy gradient optimization over asynchronous multi-agent options by adjusting option-based policy distribution as well as trajectory probability. We study our method under a set of multi-agent cooperative setups with varying inter-dependency levels, and evaluate the effectiveness of our method on typical option-based multi-agent cooperation tasks.