 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBVI: Model-Based Value Initialization for Reinforcement Learning
Paper and Code
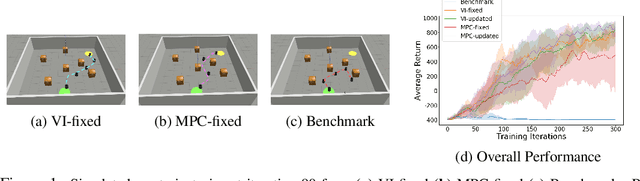
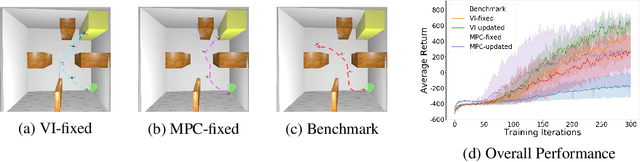
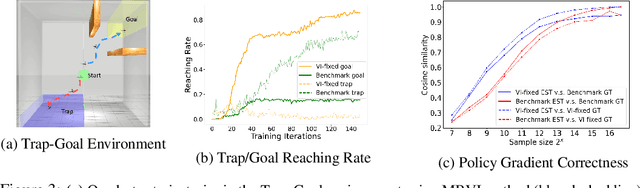
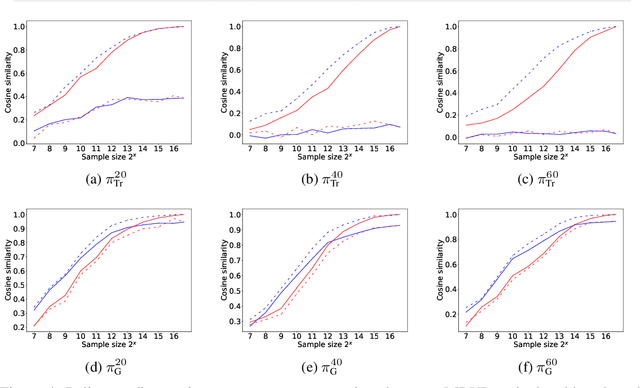
Model-free reinforcement learning (RL) is capable of learning control policies for high-dimensional, complex robotic tasks, but tends to be data inefficient. Model-based RL and optimal control have been proven to be much more data-efficient if an accurate model of the system and environment is known, but can be difficult to scale to expressive models for high-dimensional problems. In this paper, we propose a novel approach to alleviate data inefficiency of model-free RL by warm-starting the learning process using model-based solutions. We do so by initializing a high-dimensional value function via supervision from a low-dimensional value function obtained by applying model-based techniques on a low-dimensional problem featuring an approximate system model. Therefore, our approach exploits the model priors from a simplified problem space implicitly and avoids the direct use of high-dimensional, expressive models. We demonstrate our approach on two representative robotic learning tasks and observe significant improvements in performance and efficiency, and analyze our method empirically with a third task.