 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Neural Network: a low power solution for physical layer authentication
May 19, 2025Deep learning (DL) is a powerful tool that can solve complex problems, and thus, it seems natural to assume that DL can be used to enhance the security of wireless communication. However, deploying DL models to edge devices in wireless networks is challenging, as they require significant amounts of computing and power resources. Notably, Spiking Neural Networks (SNNs) are known to be efficient in terms of power consumption, meaning they can be an alternative platform for DL models for edge devices. In this study, we ask if SNNs can be used in physical layer authentication. Our evaluation suggests that SNNs can learn unique physical properties (i.e., `fingerprints') of RF transmitters and use them to identify individual devices. Furthermore, we find that SNNs are also vulnerable to adversarial attacks and that an autoencoder can be used clean out adversarial perturbations to harden SNNs against them.
Two out of Three (ToT): using self-consistency to make robust predictions
May 19, 2025Deep learning (DL) can automatically construct intelligent agents, deep neural networks (alternatively, DL models), that can outperform humans in certain tasks. However, the operating principles of DL remain poorly understood, making its decisions incomprehensible. As a result, it poses a great risk to deploy DL in high-stakes domains in which mistakes or errors may lead to critical consequences. Here, we aim to develop an algorithm that can help DL models make more robust decisions by allowing them to abstain from answering when they are uncertain. Our algorithm, named `Two out of Three (ToT)', is inspired by the sensitivity of the human brain to conflicting information. ToT creates two alternative predictions in addition to the original model prediction and uses the alternative predictions to decide whether it should provide an answer or not.
Knowledge Distillation for Feature Extraction in Underwater VSLAM
Mar 31, 2023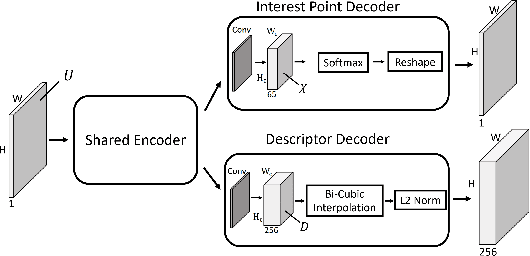
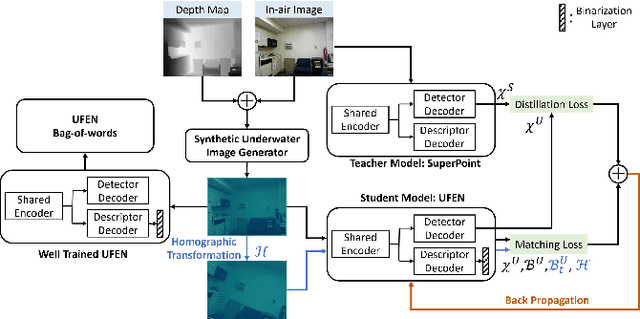
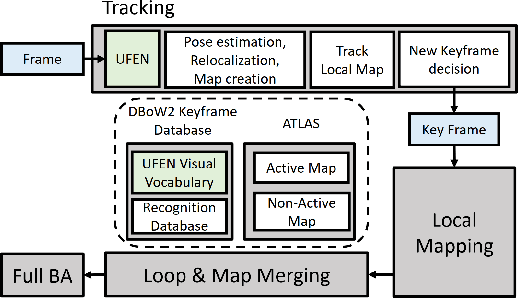
In recent years, learning-based feature detection and matching have outperformed manually-designed methods in in-air cases. However, it is challenging to learn the features in the underwater scenario due to the absence of annotated underwater datasets. This paper proposes a cross-modal knowledge distillation framework for training an underwater feature detection and matching network (UFEN). In particular, we use in-air RGBD data to generate synthetic underwater images based on a physical underwater imaging formation model and employ these as the medium to distil knowledge from a teacher model SuperPoint pretrained on in-air images. We embed UFEN into the ORB-SLAM3 framework to replace the ORB feature by introducing an additional binarization layer. To test the effectiveness of our method, we built a new underwater dataset with groundtruth measurements named EASI (https://github.com/Jinghe-mel/UFEN-SLAM), recorded in an indoor water tank for different turbidity levels. The experimental results on the existing dataset and our new dataset demonstrate the effectiveness of our method.
Analysis of functional neural codes of deep learning models
May 22, 2022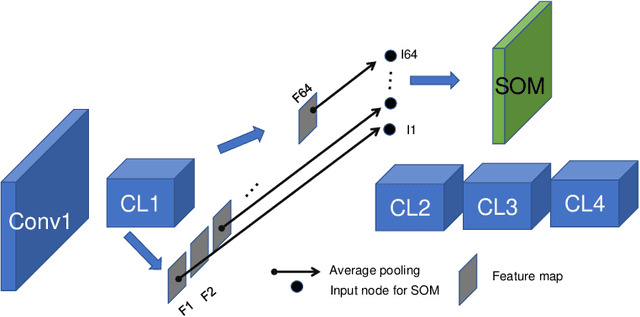
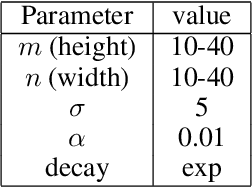
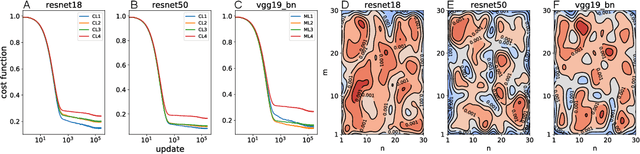
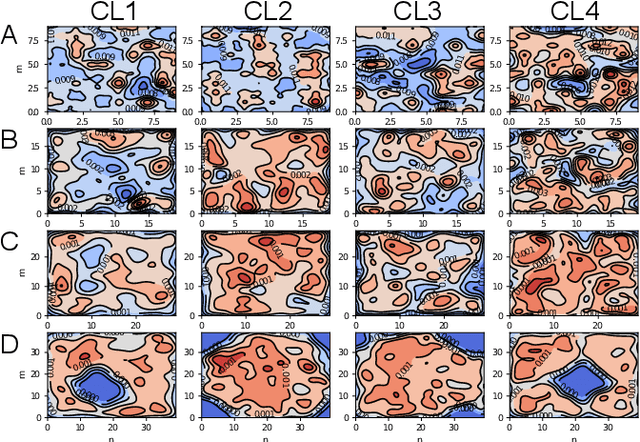
Deep neural networks (DNNs), the agents of deep learning (DL), require a massive number of parallel/sequential operations. This makes it extremely challenging to comprehend DNNs' operations and hinders proper diagnosis. Consequently, DNNs cannot be readily used in high-stakes domains, in which incorrect decisions can lead to catastrophic failures. Therefore, to build more reliable DNNs/DL to be deployed in high-stakes real-world problems, it is imperative that we develop proper analysis tools that will allow us to better understand DNNs' internal operations underlying their decision-making. Here, we used the self-organizing map (SOM) to analyze internal codes of DL models associated with their decision-making. Our analyses suggest that hidden layer activation patterns can be mapped onto a finite number of patterns and are correlated with DL predictions, raising the possibility that they could serve as functional codes of DL models. Encouraged by this observation, we further used SOM to estimate input features coded in hidden layers, analyzed the effects of adversarial inputs to better understand characterized internal representations' evolution and adversarial perturbations' propagation in DL models.
Library network, a possible path to explainable neural networks
Nov 12, 2019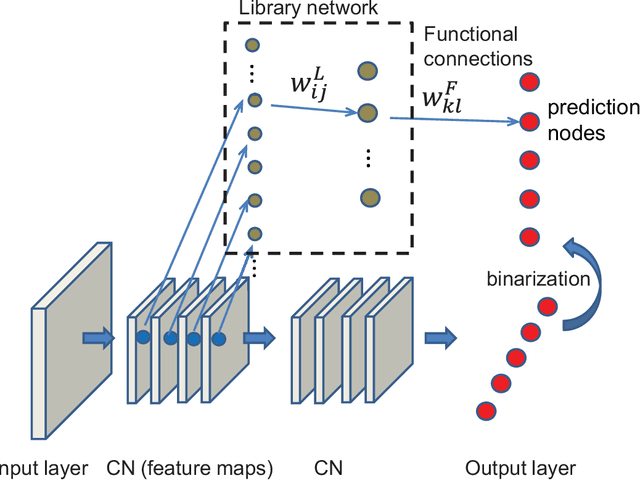

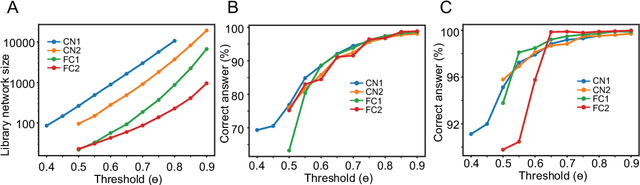
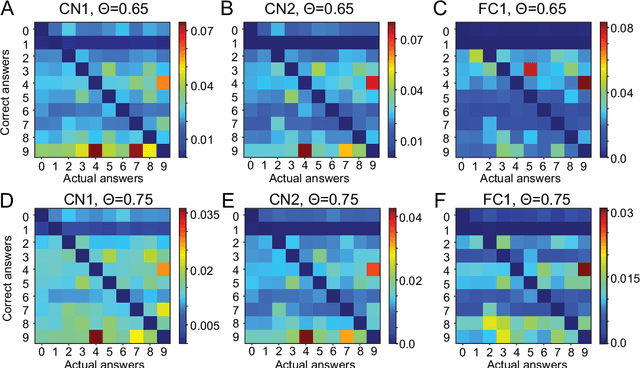
Deep neural networks (DNNs) may outperform human brains in complex tasks, but the lack of transparency in their decision-making processes makes us question whether we could fully trust DNNs with high stakes problems. As DNNs' operations rely on a massive number of both parallel and sequential linear/nonlinear computations, predicting their mistakes is nearly impossible. Also, a line of studies suggests that DNNs can be easily deceived by adversarial attacks, indicating that DNNs' decisions can easily be corrupted by unexpected factors. Such vulnerability must be overcome if we intend to take advantage of DNNs' efficiency in high stakes problems. Here, we propose an algorithm that can help us better understand DNNs' decision-making processes. Our empirical estimates suggest that this algorithm can effectively trace DNNs' decision processes from one layer to another and detect adversarial attacks.
Complementary reinforcement learning toward explainable agents
Jan 01, 2019


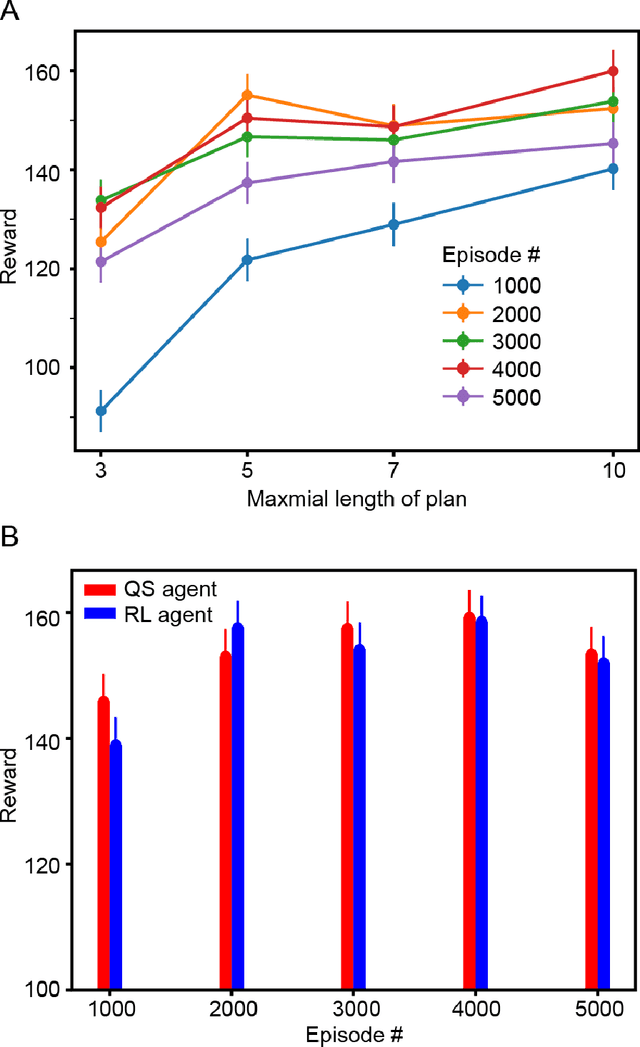
Reinforcement learning (RL) algorithms allow agents to learn skills and strategies to perform complex tasks without detailed instructions or expensive labelled training examples. That is, RL agents can learn, as we learn. Given the importance of learning in our intelligence, RL has been thought to be one of key components to general artificial intelligence, and recent breakthroughs in deep reinforcement learning suggest that neural networks (NN) are natural platforms for RL agents. However, despite the efficiency and versatility of NN-based RL agents, their decision-making remains incomprehensible, reducing their utilities. To deploy RL into a wider range of applications, it is imperative to develop explainable NN-based RL agents. Here, we propose a method to derive a secondary comprehensible agent from a NN-based RL agent, whose decision-makings are based on simple rules. Our empirical evaluation of this secondary agent's performance supports the possibility of building a comprehensible and transparent agent using a NN-based RL agent.