 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE2: SubWord Enriched and Significant Word Emphasized Framework for Hate Speech Detection
Sep 25, 2024



Hate speech detection on online social networks has become one of the emerging hot topics in recent years. With the broad spread and fast propagation speed across online social networks, hate speech makes significant impacts on society by increasing prejudice and hurting people. Therefore, there are aroused attention and concern from both industry and academia. In this paper, we address the hate speech problem and propose a novel hate speech detection framework called SWE2, which only relies on the content of messages and automatically identifies hate speech. In particular, our framework exploits both word-level semantic information and sub-word knowledge. It is intuitively persuasive and also practically performs well under a situation with/without character-level adversarial attack. Experimental results show that our proposed model achieves 0.975 accuracy and 0.953 macro F1, outperforming 7 state-of-the-art baselines under no adversarial attack. Our model robustly and significantly performed well under extreme adversarial attack (manipulation of 50% messages), achieving 0.967 accuracy and 0.934 macro F1.
* Published in CIKM 2020
Recursively Conditional Gaussian for Ordinal Unsupervised Domain Adaptation
Aug 17, 2021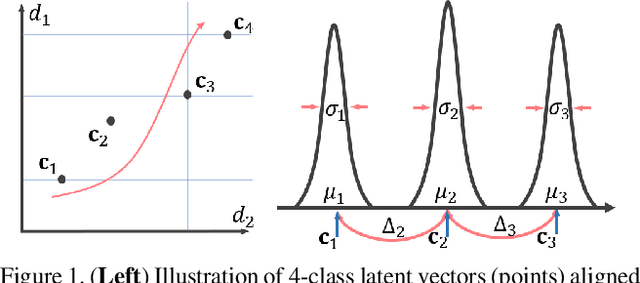
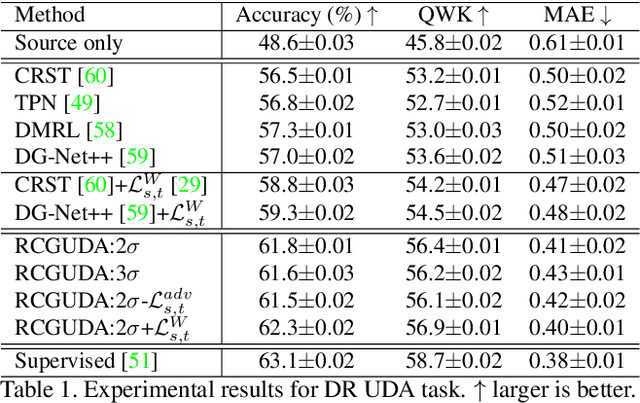
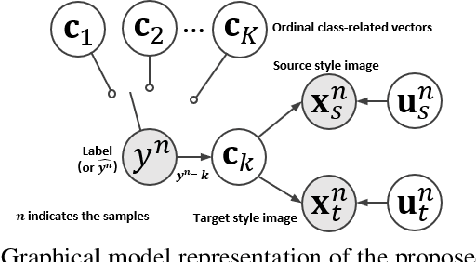
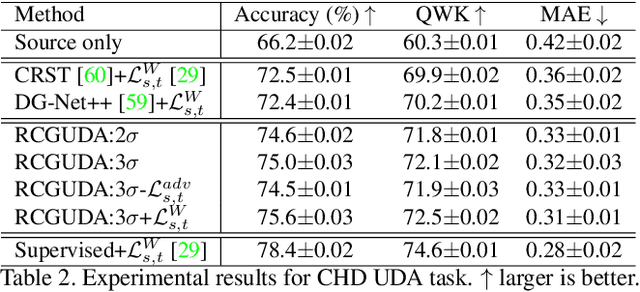
The unsupervised domain adaptation (UDA) has been widely adopted to alleviate the data scalability issue, while the existing works usually focus on classifying independently discrete labels. However, in many tasks (e.g., medical diagnosis), the labels are discrete and successively distributed. The UDA for ordinal classification requires inducing non-trivial ordinal distribution prior to the latent space. Target for this, the partially ordered set (poset) is defined for constraining the latent vector. Instead of the typically i.i.d. Gaussian latent prior, in this work, a recursively conditional Gaussian (RCG) set is adapted for ordered constraint modeling, which admits a tractable joint distribution prior. Furthermore, we are able to control the density of content vector that violates the poset constraints by a simple "three-sigma rule". We explicitly disentangle the cross-domain images into a shared ordinal prior induced ordinal content space and two separate source/target ordinal-unrelated spaces, and the self-training is worked on the shared space exclusively for ordinal-aware domain alignment. Extensive experiments on UDA medical diagnoses and facial age estimation demonstrate its effectiveness.