 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicinal Feature Statistics Augmentation for Federated 3D Medical Volume Segmentation
Oct 23, 2023Federated learning (FL) enables multiple client medical institutes collaboratively train a deep learning (DL) model with privacy protection. However, the performance of FL can be constrained by the limited availability of labeled data in small institutes and the heterogeneous (i.e., non-i.i.d.) data distribution across institutes. Though data augmentation has been a proven technique to boost the generalization capabilities of conventional centralized DL as a "free lunch", its application in FL is largely underexplored. Notably, constrained by costly labeling, 3D medical segmentation generally relies on data augmentation. In this work, we aim to develop a vicinal feature-level data augmentation (VFDA) scheme to efficiently alleviate the local feature shift and facilitate collaborative training for privacy-aware FL segmentation. We take both the inner- and inter-institute divergence into consideration, without the need for cross-institute transfer of raw data or their mixup. Specifically, we exploit the batch-wise feature statistics (e.g., mean and standard deviation) in each institute to abstractly represent the discrepancy of data, and model each feature statistic probabilistically via a Gaussian prototype, with the mean corresponding to the original statistic and the variance quantifying the augmentation scope. From the vicinal risk minimization perspective, novel feature statistics can be drawn from the Gaussian distribution to fulfill augmentation. The variance is explicitly derived by the data bias in each individual institute and the underlying feature statistics characterized by all participating institutes. The added-on VFDA consistently yielded marked improvements over six advanced FL methods on both 3D brain tumor and cardiac segmentation.
* 28th biennial international conference on Information Processing in Medical Imaging (IPMI 2023): Oral Paper
3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds
Nov 17, 2021
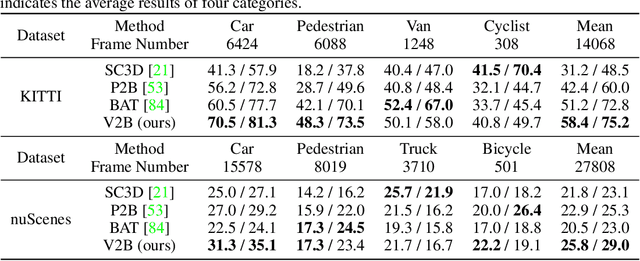
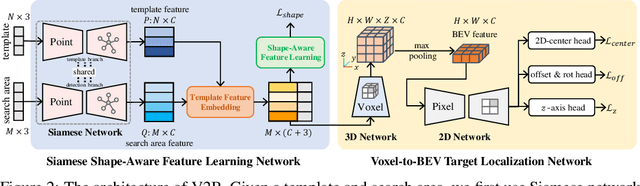
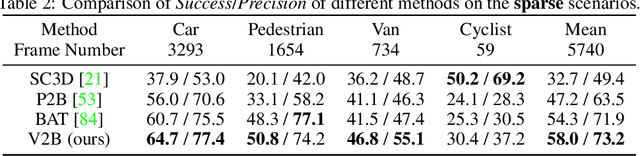
3D object tracking in point clouds is still a challenging problem due to the sparsity of LiDAR points in dynamic environments. In this work, we propose a Siamese voxel-to-BEV tracker, which can significantly improve the tracking performance in sparse 3D point clouds. Specifically, it consists of a Siamese shape-aware feature learning network and a voxel-to-BEV target localization network. The Siamese shape-aware feature learning network can capture 3D shape information of the object to learn the discriminative features of the object so that the potential target from the background in sparse point clouds can be identified. To this end, we first perform template feature embedding to embed the template's feature into the potential target and then generate a dense 3D shape to characterize the shape information of the potential target. For localizing the tracked target, the voxel-to-BEV target localization network regresses the target's 2D center and the $z$-axis center from the dense bird's eye view (BEV) feature map in an anchor-free manner. Concretely, we compress the voxelized point cloud along $z$-axis through max pooling to obtain a dense BEV feature map, where the regression of the 2D center and the $z$-axis center can be performed more effectively. Extensive evaluation on the KITTI and nuScenes datasets shows that our method significantly outperforms the current state-of-the-art methods by a large margin.
SSPC-Net: Semi-supervised Semantic 3D Point Cloud Segmentation Network
Apr 19, 2021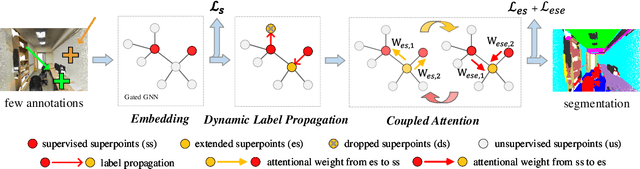
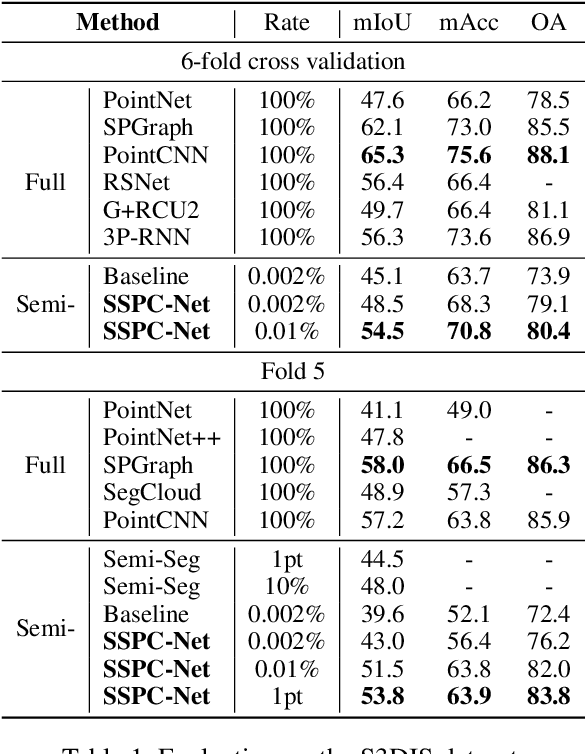
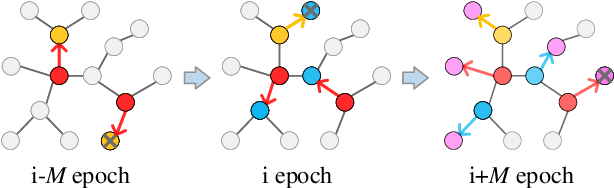
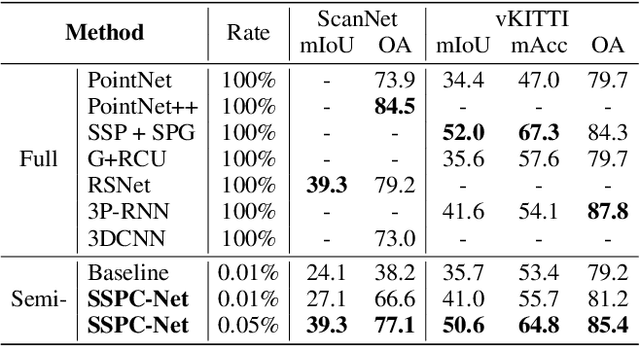
Point cloud semantic segmentation is a crucial task in 3D scene understanding. Existing methods mainly focus on employing a large number of annotated labels for supervised semantic segmentation. Nonetheless, manually labeling such large point clouds for the supervised segmentation task is time-consuming. In order to reduce the number of annotated labels, we propose a semi-supervised semantic point cloud segmentation network, named SSPC-Net, where we train the semantic segmentation network by inferring the labels of unlabeled points from the few annotated 3D points. In our method, we first partition the whole point cloud into superpoints and build superpoint graphs to mine the long-range dependencies in point clouds. Based on the constructed superpoint graph, we then develop a dynamic label propagation method to generate the pseudo labels for the unsupervised superpoints. Particularly, we adopt a superpoint dropout strategy to dynamically select the generated pseudo labels. In order to fully exploit the generated pseudo labels of the unsupervised superpoints, we furthermore propose a coupled attention mechanism for superpoint feature embedding. Finally, we employ the cross-entropy loss to train the semantic segmentation network with the labels of the supervised superpoints and the pseudo labels of the unsupervised superpoints. Experiments on various datasets demonstrate that our semi-supervised segmentation method can achieve better performance than the current semi-supervised segmentation method with fewer annotated 3D points. Our code is available at https://github.com/MMCheng/SSPC-Net.
Efficient 3D Point Cloud Feature Learning for Large-Scale Place Recognition
Jan 07, 2021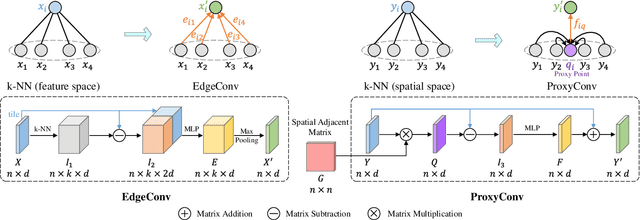
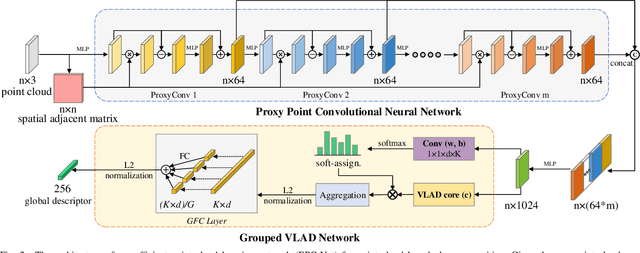
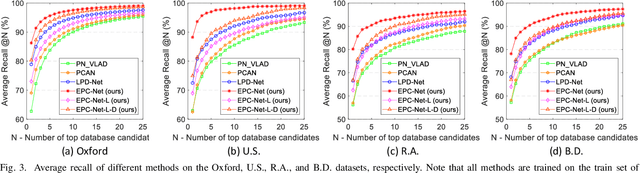
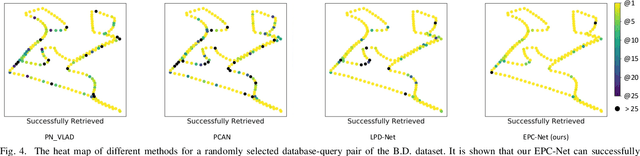
Point cloud based retrieval for place recognition is still a challenging problem due to drastic appearance and illumination changes of scenes in changing environments. Existing deep learning based global descriptors for the retrieval task usually consume a large amount of computation resources (e.g., memory), which may not be suitable for the cases of limited hardware resources. In this paper, we develop an efficient point cloud learning network (EPC-Net) to form a global descriptor for visual place recognition, which can obtain good performance and reduce computation memory and inference time. First, we propose a lightweight but effective neural network module, called ProxyConv, to aggregate the local geometric features of point clouds. We leverage the spatial adjacent matrix and proxy points to simplify the original edge convolution for lower memory consumption. Then, we design a lightweight grouped VLAD network (G-VLAD) to form global descriptors for retrieval. Compared with the original VLAD network, we propose a grouped fully connected (GFC) layer to decompose the high-dimensional vectors into a group of low-dimensional vectors, which can reduce the number of parameters of the network and maintain the discrimination of the feature vector. Finally, to further reduce the inference time, we develop a simple version of EPC-Net, called EPC-Net-L, which consists of two ProxyConv modules and one max pooling layer to aggregate global descriptors. By distilling the knowledge from EPC-Net, EPC-Net-L can obtain discriminative global descriptors for retrieval. Extensive experiments on the Oxford dataset and three in-house datasets demonstrate that our proposed method can achieve state-of-the-art performance with lower parameters, FLOPs, and runtime per frame.
Cascaded Non-local Neural Network for Point Cloud Semantic Segmentation
Jul 30, 2020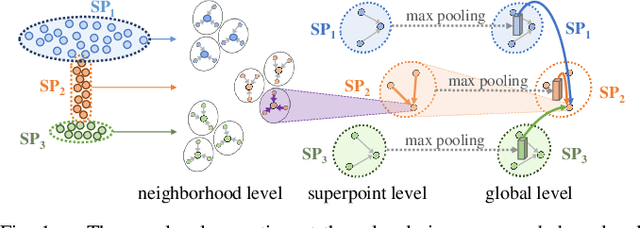
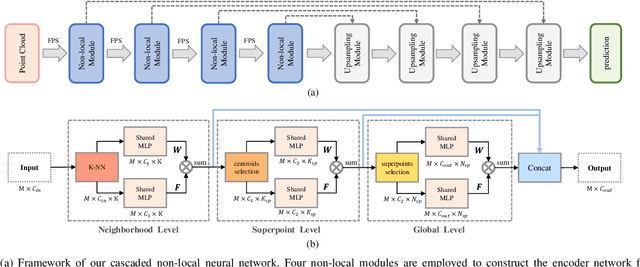
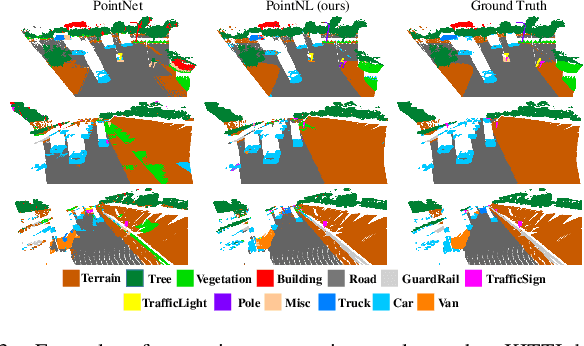
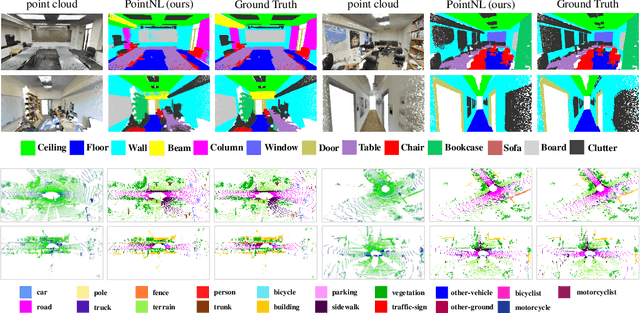
In this paper, we propose a cascaded non-local neural network for point cloud segmentation. The proposed network aims to build the long-range dependencies of point clouds for the accurate segmentation. Specifically, we develop a novel cascaded non-local module, which consists of the neighborhood-level, superpoint-level and global-level non-local blocks. First, in the neighborhood-level block, we extract the local features of the centroid points of point clouds by assigning different weights to the neighboring points. The extracted local features of the centroid points are then used to encode the superpoint-level block with the non-local operation. Finally, the global-level block aggregates the non-local features of the superpoints for semantic segmentation in an encoder-decoder framework. Benefiting from the cascaded structure, geometric structure information of different neighborhoods with the same label can be propagated. In addition, the cascaded structure can largely reduce the computational cost of the original non-local operation on point clouds. Experiments on different indoor and outdoor datasets show that our method achieves state-of-the-art performance and effectively reduces the time consumption and memory occupation.