 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRI-MAE: Rotation-Invariant Masked AutoEncoders for Self-Supervised Point Cloud Representation Learning
Paper and Code
Aug 31, 2024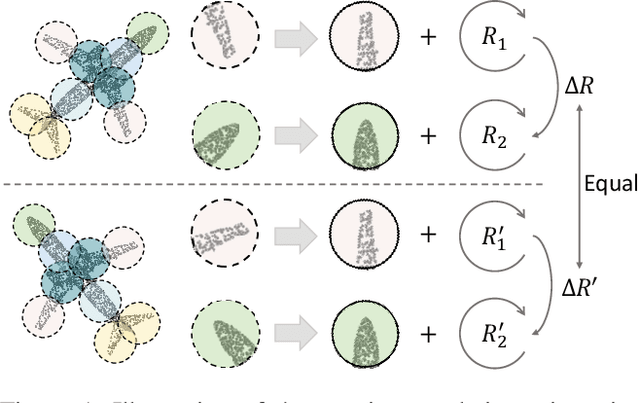
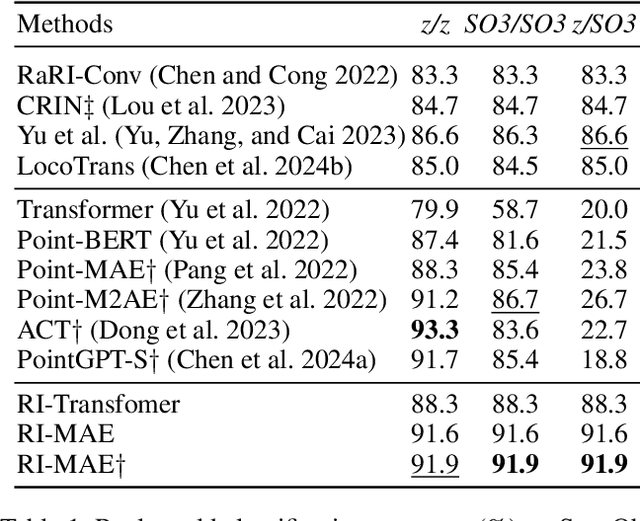
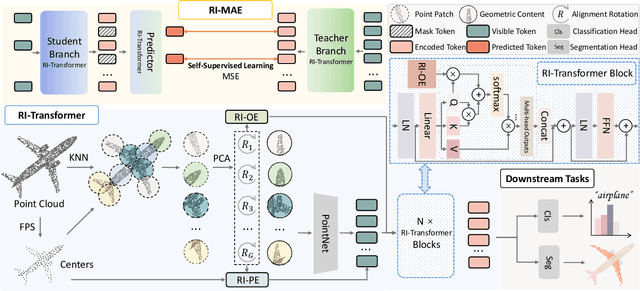
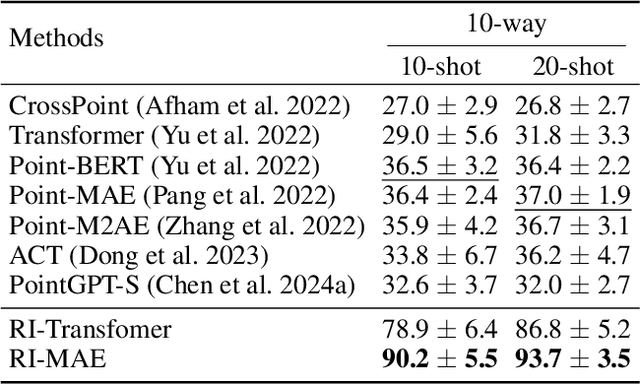
Masked point modeling methods have recently achieved great success in self-supervised learning for point cloud data. However, these methods are sensitive to rotations and often exhibit sharp performance drops when encountering rotational variations. In this paper, we propose a novel Rotation-Invariant Masked AutoEncoders (RI-MAE) to address two major challenges: 1) achieving rotation-invariant latent representations, and 2) facilitating self-supervised reconstruction in a rotation-invariant manner. For the first challenge, we introduce RI-Transformer, which features disentangled geometry content, rotation-invariant relative orientation and position embedding mechanisms for constructing rotation-invariant point cloud latent space. For the second challenge, a novel dual-branch student-teacher architecture is devised. It enables the self-supervised learning via the reconstruction of masked patches within the learned rotation-invariant latent space. Each branch is based on an RI-Transformer, and they are connected with an additional RI-Transformer predictor. The teacher encodes all point patches, while the student solely encodes unmasked ones. Finally, the predictor predicts the latent features of the masked patches using the output latent embeddings from the student, supervised by the outputs from the teacher. Extensive experiments demonstrate that our method is robust to rotations, achieving the state-of-the-art performance on various downstream tasks.