 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErase, then Redraw: A Novel Data Augmentation Approach for Free Space Detection Using Diffusion Model
Paper and Code
Sep 30, 2024
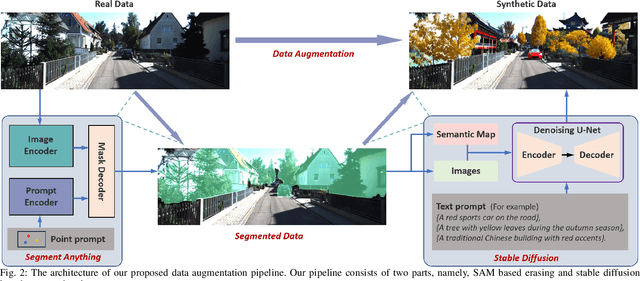
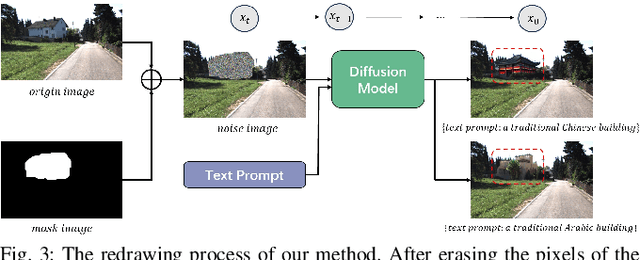

Data augmentation is one of the most common tools in deep learning, underpinning many recent advances including tasks such as classification, detection, and semantic segmentation. The standard approach to data augmentation involves simple transformations like rotation and flipping to generate new images. However, these new images often lack diversity along the main semantic dimensions within the data. Traditional data augmentation methods cannot alter high-level semantic attributes such as the presence of vehicles, trees, and buildings in a scene to enhance data diversity. In recent years, the rapid development of generative models has injected new vitality into the field of data augmentation. In this paper, we address the lack of diversity in data augmentation for road detection task by using a pre-trained text-to-image diffusion model to parameterize image-to-image transformations. Our method involves editing images using these diffusion models to change their semantics. In essence, we achieve this goal by erasing instances of real objects from the original dataset and generating new instances with similar semantics in the erased regions using the diffusion model, thereby expanding the original dataset. We evaluate our approach on the KITTI road dataset and achieve the best results compared to other data augmentation methods, which demonstrates the effectiveness of our proposed development.