 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Sign Recognition in Autonomous Driving: Dataset, Benchmark, and Field Experiment
Mar 24, 2026Traffic Sign Recognition (TSR) is a core perception capability for autonomous driving, where robustness to cross-region variation, long-tailed categories, and semantic ambiguity is essential for reliable real-world deployment. Despite steady progress in recognition accuracy, existing traffic sign datasets and benchmarks offer limited diagnostic insight into how different modeling paradigms behave under these practical challenges. We present TS-1M, a large-scale and globally diverse traffic sign dataset comprising over one million real-world images across 454 standardized categories, together with a diagnostic benchmark designed to analyze model capability boundaries. Beyond standard train-test evaluation, we provide a suite of challenge-oriented settings, including cross-region recognition, rare-class identification, low-clarity robustness, and semantic text understanding, enabling systematic and fine-grained assessment of modern TSR models. Using TS-1M, we conduct a unified benchmark across three representative learning paradigms: classical supervised models, self-supervised pretrained models, and multimodal vision-language models (VLMs). Our analysis reveals consistent paradigm-dependent behaviors, showing that semantic alignment is a key factor for cross-region generalization and rare-category recognition, while purely visual models remain sensitive to appearance shift and data imbalance. Finally, we validate the practical relevance of TS-1M through real-scene autonomous driving experiments, where traffic sign recognition is integrated with semantic reasoning and spatial localization to support map-level decision constraints. Overall, TS-1M establishes a reference-level diagnostic benchmark for TSR and provides principled insights into robust and semantic-aware traffic sign perception. Project page: https://guoyangzhao.github.io/projects/ts1m.
Beyond a Single Light: A Large-Scale Aerial Dataset for Urban Scene Reconstruction Under Varying Illumination
Dec 16, 2025Recent advances in Neural Radiance Fields and 3D Gaussian Splatting have demonstrated strong potential for large-scale UAV-based 3D reconstruction tasks by fitting the appearance of images. However, real-world large-scale captures are often based on multi-temporal data capture, where illumination inconsistencies across different times of day can significantly lead to color artifacts, geometric inaccuracies, and inconsistent appearance. Due to the lack of UAV datasets that systematically capture the same areas under varying illumination conditions, this challenge remains largely underexplored. To fill this gap, we introduceSkyLume, a large-scale, real-world UAV dataset specifically designed for studying illumination robust 3D reconstruction in urban scene modeling: (1) We collect data from 10 urban regions data comprising more than 100k high resolution UAV images (four oblique views and nadir), where each region is captured at three periods of the day to systematically isolate illumination changes. (2) To support precise evaluation of geometry and appearance, we provide per-scene LiDAR scans and accurate 3D ground-truth for assessing depth, surface normals, and reconstruction quality under varying illumination. (3) For the inverse rendering task, we introduce the Temporal Consistency Coefficient (TCC), a metric that measuress cross-time albedo stability and directly evaluates the robustness of the disentanglement of light and material. We aim for this resource to serve as a foundation that advances research and real-world evaluation in large-scale inverse rendering, geometry reconstruction, and novel view synthesis.
Task-Oriented Pre-Training for Drivable Area Detection
Sep 30, 2024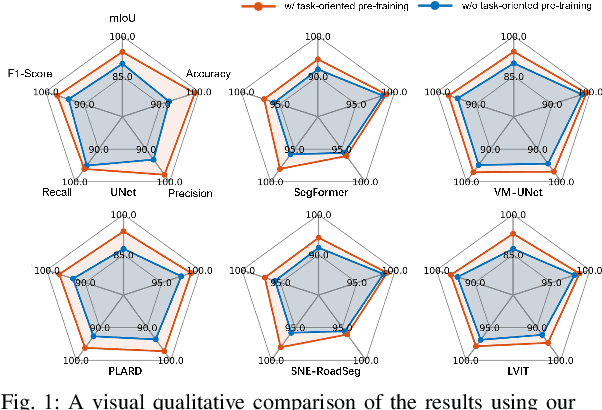
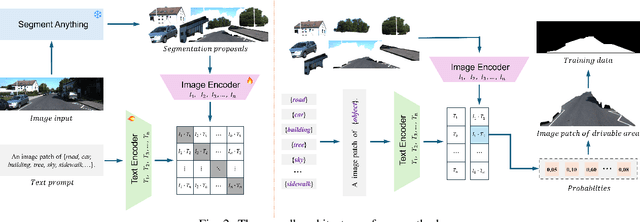


Pre-training techniques play a crucial role in deep learning, enhancing models' performance across a variety of tasks. By initially training on large datasets and subsequently fine-tuning on task-specific data, pre-training provides a solid foundation for models, improving generalization abilities and accelerating convergence rates. This approach has seen significant success in the fields of natural language processing and computer vision. However, traditional pre-training methods necessitate large datasets and substantial computational resources, and they can only learn shared features through prolonged training and struggle to capture deeper, task-specific features. In this paper, we propose a task-oriented pre-training method that begins with generating redundant segmentation proposals using the Segment Anything (SAM) model. We then introduce a Specific Category Enhancement Fine-tuning (SCEF) strategy for fine-tuning the Contrastive Language-Image Pre-training (CLIP) model to select proposals most closely related to the drivable area from those generated by SAM. This approach can generate a lot of coarse training data for pre-training models, which are further fine-tuned using manually annotated data, thereby improving model's performance. Comprehensive experiments conducted on the KITTI road dataset demonstrate that our task-oriented pre-training method achieves an all-around performance improvement compared to models without pre-training. Moreover, our pre-training method not only surpasses traditional pre-training approach but also achieves the best performance compared to state-of-the-art self-training methods.
Erase, then Redraw: A Novel Data Augmentation Approach for Free Space Detection Using Diffusion Model
Sep 30, 2024
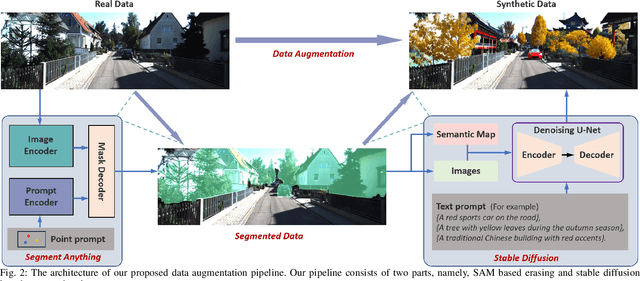
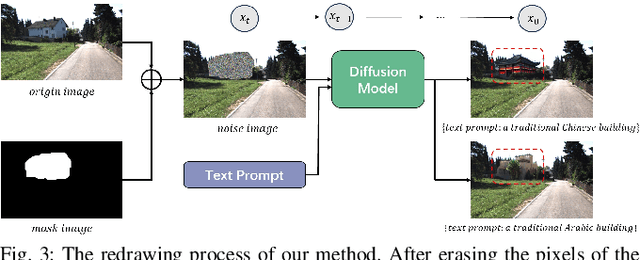

Data augmentation is one of the most common tools in deep learning, underpinning many recent advances including tasks such as classification, detection, and semantic segmentation. The standard approach to data augmentation involves simple transformations like rotation and flipping to generate new images. However, these new images often lack diversity along the main semantic dimensions within the data. Traditional data augmentation methods cannot alter high-level semantic attributes such as the presence of vehicles, trees, and buildings in a scene to enhance data diversity. In recent years, the rapid development of generative models has injected new vitality into the field of data augmentation. In this paper, we address the lack of diversity in data augmentation for road detection task by using a pre-trained text-to-image diffusion model to parameterize image-to-image transformations. Our method involves editing images using these diffusion models to change their semantics. In essence, we achieve this goal by erasing instances of real objects from the original dataset and generating new instances with similar semantics in the erased regions using the diffusion model, thereby expanding the original dataset. We evaluate our approach on the KITTI road dataset and achieve the best results compared to other data augmentation methods, which demonstrates the effectiveness of our proposed development.
CLRKDNet: Speeding up Lane Detection with Knowledge Distillation
May 21, 2024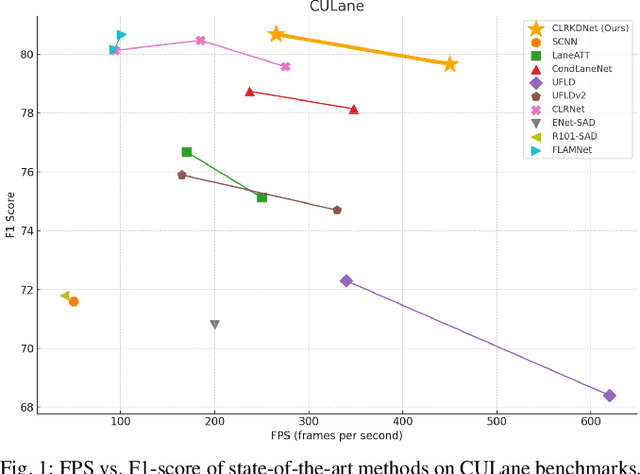
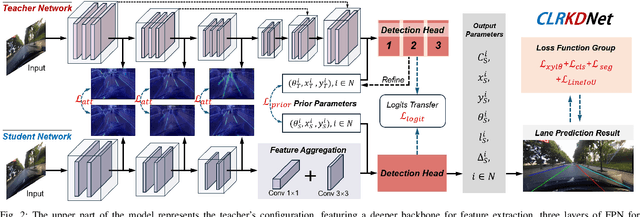
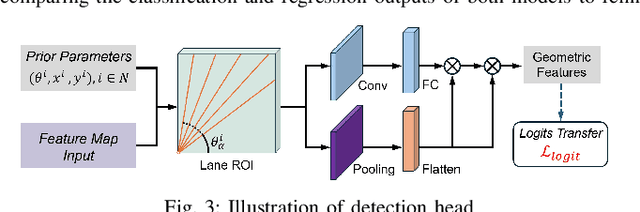
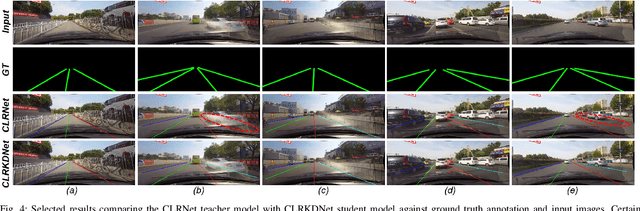
Road lanes are integral components of the visual perception systems in intelligent vehicles, playing a pivotal role in safe navigation. In lane detection tasks, balancing accuracy with real-time performance is essential, yet existing methods often sacrifice one for the other. To address this trade-off, we introduce CLRKDNet, a streamlined model that balances detection accuracy with real-time performance. The state-of-the-art model CLRNet has demonstrated exceptional performance across various datasets, yet its computational overhead is substantial due to its Feature Pyramid Network (FPN) and muti-layer detection head architecture. Our method simplifies both the FPN structure and detection heads, redesigning them to incorporate a novel teacher-student distillation process alongside a newly introduced series of distillation losses. This combination reduces inference time by up to 60% while maintaining detection accuracy comparable to CLRNet. This strategic balance of accuracy and speed makes CLRKDNet a viable solution for real-time lane detection tasks in autonomous driving applications.
Monocular 3D lane detection for Autonomous Driving: Recent Achievements, Challenges, and Outlooks
Apr 10, 2024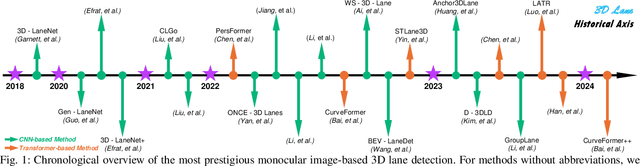
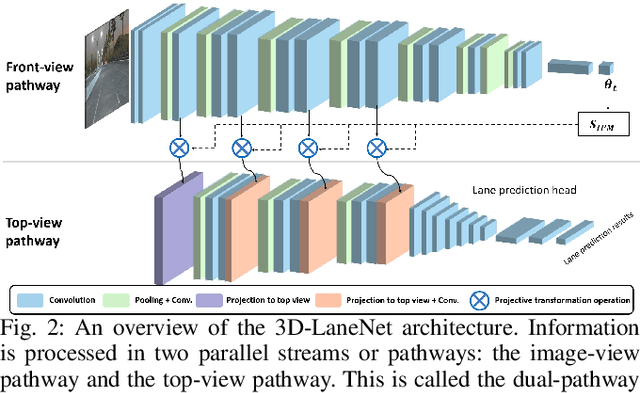
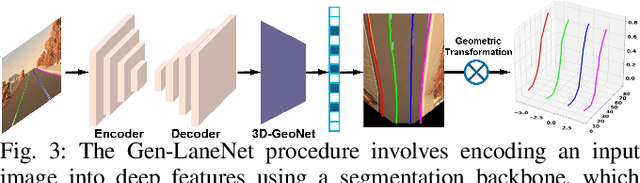
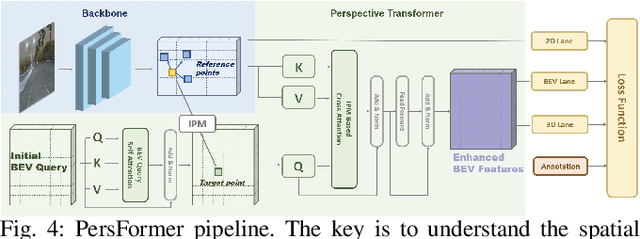
3D lane detection plays a crucial role in autonomous driving by extracting structural and traffic information from the road in 3D space to assist the self-driving car in rational, safe, and comfortable path planning and motion control. Due to the consideration of sensor costs and the advantages of visual data in color information, in practical applications, 3D lane detection based on monocular vision is one of the important research directions in the field of autonomous driving, which has attracted more and more attention in both industry and academia. Unfortunately, recent progress in visual perception seems insufficient to develop completely reliable 3D lane detection algorithms, which also hinders the development of vision-based fully autonomous self-driving cars, i.e., achieving level 5 autonomous driving, driving like human-controlled cars. This is one of the conclusions drawn from this review paper: there is still a lot of room for improvement and significant improvements are still needed in the 3D lane detection algorithm for autonomous driving cars using visual sensors. Motivated by this, this review defines, analyzes, and reviews the current achievements in the field of 3D lane detection research, and the vast majority of the current progress relies heavily on computationally complex deep learning models. In addition, this review covers the 3D lane detection pipeline, investigates the performance of state-of-the-art algorithms, analyzes the time complexity of cutting-edge modeling choices, and highlights the main achievements and limitations of current research efforts. The survey also includes a comprehensive discussion of available 3D lane detection datasets and the challenges that researchers have faced but have not yet resolved. Finally, our work outlines future research directions and welcomes researchers and practitioners to enter this exciting field.
CurbNet: Curb Detection Framework Based on LiDAR Point Cloud Segmentation
Mar 25, 2024

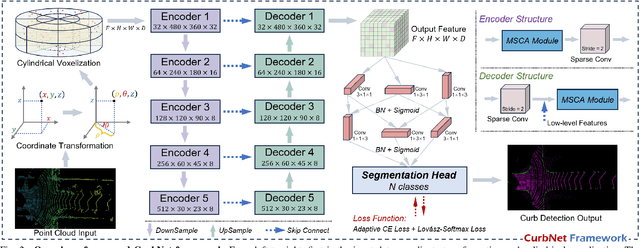
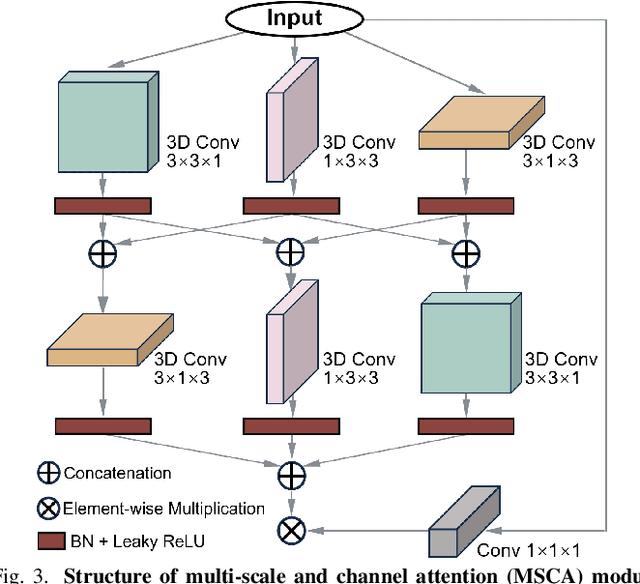
Curb detection is an important function in intelligent driving and can be used to determine drivable areas of the road. However, curbs are difficult to detect due to the complex road environment. This paper introduces CurbNet, a novel framework for curb detection, leveraging point cloud segmentation. Addressing the dearth of comprehensive curb datasets and the absence of 3D annotations, we have developed the 3D-Curb dataset, encompassing 7,100 frames, which represents the largest and most categorically diverse collection of curb point clouds currently available. Recognizing that curbs are primarily characterized by height variations, our approach harnesses spatially-rich 3D point clouds for training. To tackle the challenges presented by the uneven distribution of curb features on the xy-plane and their reliance on z-axis high-frequency features, we introduce the multi-scale and channel attention (MSCA) module, a bespoke solution designed to optimize detection performance. Moreover, we propose an adaptive weighted loss function group, specifically formulated to counteract the imbalance in the distribution of curb point clouds relative to other categories. Our extensive experimentation on 2 major datasets has yielded results that surpass existing benchmarks set by leading curb detection and point cloud segmentation models. By integrating multi-clustering and curve fitting techniques in our post-processing stage, we have substantially reduced noise in curb detection, thereby enhancing precision to 0.8744. Notably, CurbNet has achieved an exceptional average metrics of over 0.95 at a tolerance of just 0.15m, thereby establishing a new benchmark. Furthermore, corroborative real-world experiments and dataset analyzes mutually validate each other, solidifying CurbNet's superior detection proficiency and its robust generalizability.