 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Pre-Training for Drivable Area Detection
Paper and Code
Sep 30, 2024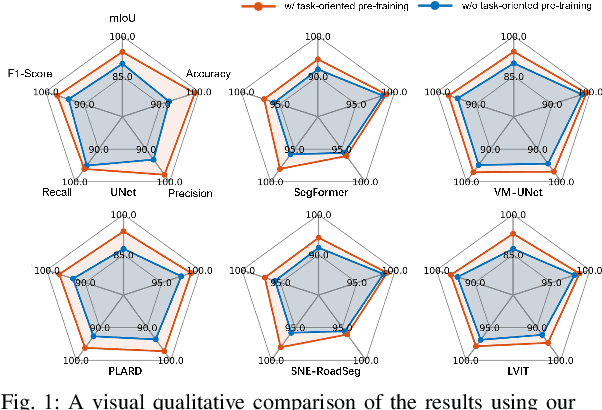
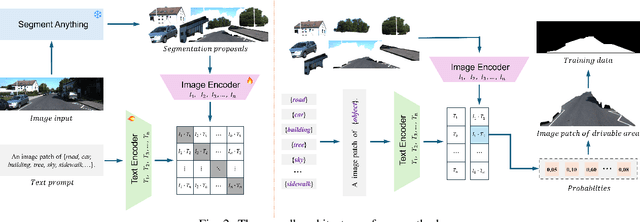


Pre-training techniques play a crucial role in deep learning, enhancing models' performance across a variety of tasks. By initially training on large datasets and subsequently fine-tuning on task-specific data, pre-training provides a solid foundation for models, improving generalization abilities and accelerating convergence rates. This approach has seen significant success in the fields of natural language processing and computer vision. However, traditional pre-training methods necessitate large datasets and substantial computational resources, and they can only learn shared features through prolonged training and struggle to capture deeper, task-specific features. In this paper, we propose a task-oriented pre-training method that begins with generating redundant segmentation proposals using the Segment Anything (SAM) model. We then introduce a Specific Category Enhancement Fine-tuning (SCEF) strategy for fine-tuning the Contrastive Language-Image Pre-training (CLIP) model to select proposals most closely related to the drivable area from those generated by SAM. This approach can generate a lot of coarse training data for pre-training models, which are further fine-tuned using manually annotated data, thereby improving model's performance. Comprehensive experiments conducted on the KITTI road dataset demonstrate that our task-oriented pre-training method achieves an all-around performance improvement compared to models without pre-training. Moreover, our pre-training method not only surpasses traditional pre-training approach but also achieves the best performance compared to state-of-the-art self-training methods.