 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge34 Examples of LLM Applications in Materials Science and Chemistry: Towards Automation, Assistants, Agents, and Accelerated Scientific Discovery
May 05, 2025
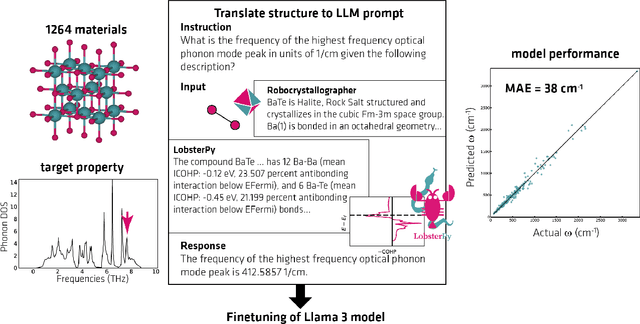
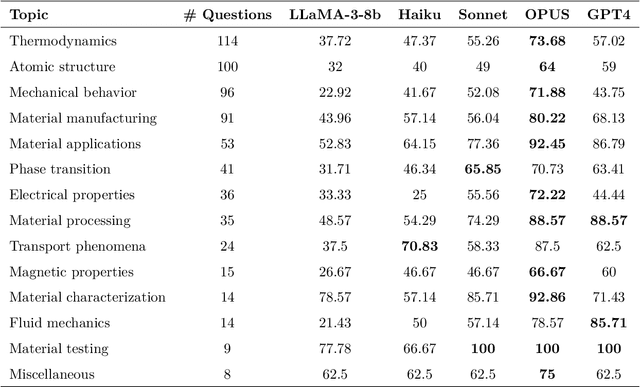
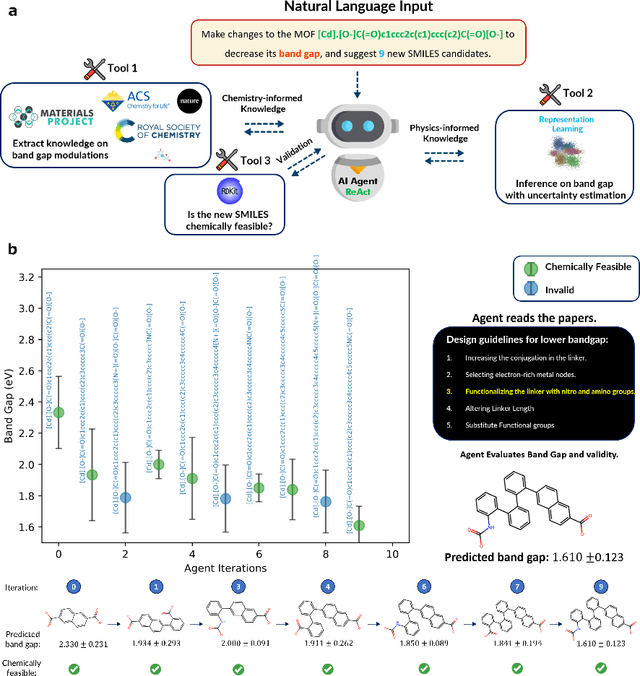
Large Language Models (LLMs) are reshaping many aspects of materials science and chemistry research, enabling advances in molecular property prediction, materials design, scientific automation, knowledge extraction, and more. Recent developments demonstrate that the latest class of models are able to integrate structured and unstructured data, assist in hypothesis generation, and streamline research workflows. To explore the frontier of LLM capabilities across the research lifecycle, we review applications of LLMs through 34 total projects developed during the second annual Large Language Model Hackathon for Applications in Materials Science and Chemistry, a global hybrid event. These projects spanned seven key research areas: (1) molecular and material property prediction, (2) molecular and material design, (3) automation and novel interfaces, (4) scientific communication and education, (5) research data management and automation, (6) hypothesis generation and evaluation, and (7) knowledge extraction and reasoning from the scientific literature. Collectively, these applications illustrate how LLMs serve as versatile predictive models, platforms for rapid prototyping of domain-specific tools, and much more. In particular, improvements in both open source and proprietary LLM performance through the addition of reasoning, additional training data, and new techniques have expanded effectiveness, particularly in low-data environments and interdisciplinary research. As LLMs continue to improve, their integration into scientific workflows presents both new opportunities and new challenges, requiring ongoing exploration, continued refinement, and further research to address reliability, interpretability, and reproducibility.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
LLaMP: Large Language Model Made Powerful for High-fidelity Materials Knowledge Retrieval and Distillation
Jan 30, 2024



Reducing hallucination of Large Language Models (LLMs) is imperative for use in the sciences where reproducibility is crucial. However, LLMs inherently lack long-term memory, making it a nontrivial, ad hoc, and inevitably biased task to fine-tune them on domain-specific literature and data. Here we introduce LLaMP, a multimodal retrieval-augmented generation (RAG) framework of multiple data-aware reasoning-and-acting (ReAct) agents that dynamically interact with computational and experimental data on Materials Project (MP). Without fine-tuning, LLaMP demonstrates an ability to comprehend and integrate various modalities of materials science concepts, fetch relevant data stores on the fly, process higher-order data (such as crystal structures and elastic tensors), and summarize multi-step procedures for solid-state synthesis. We show that LLaMP effectively corrects errors in GPT-3.5's intrinsic knowledge, reducing a 5.21% MAPE on frequently-documented bandgaps and a significant 1103.54% MAPE on formation energies -- errors that GPT-3.5 seems to derive from mixed data sources. Additionally, LLaMP substantially reduces the hallucinated volumetric strain in a diamond cubic silicon structure from 66.3% to 0. The proposed framework offers an intuitive and nearly hallucination-free approach to exploring materials informatics and establishes a pathway for knowledge distillation and fine-tuning other language models. We envision the framework as a valuable component for scientific hypotheses and a foundation for future autonomous laboratories where multiple LLM agents communicate and cooperate with robotics to drive material synthesis and chemical reactions without hard-coded human logic and intervention.
DGPO: Discovering Multiple Strategies with Diversity-Guided Policy Optimization
Jul 12, 2022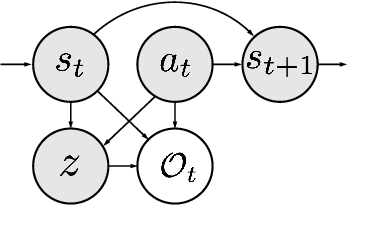

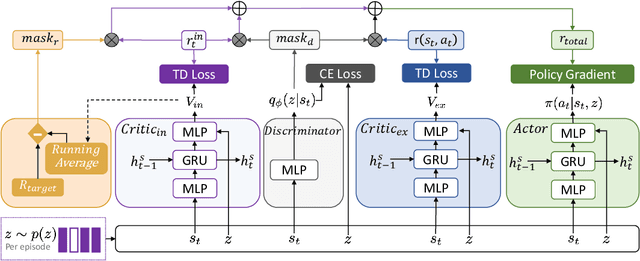
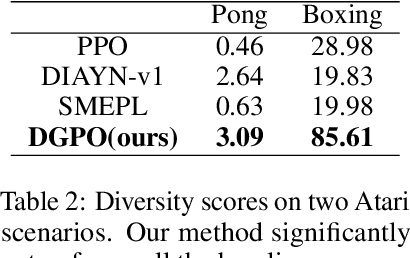
Recent algorithms designed for reinforcement learning tasks focus on finding a single optimal solution. However, in many practical applications, it is important to develop reasonable agents with diverse strategies. In this paper, we propose Diversity-Guided Policy Optimization (DGPO), an on-policy framework for discovering multiple strategies for the same task. Our algorithm uses diversity objectives to guide a latent code conditioned policy to learn a set of diverse strategies in a single training procedure. Specifically, we formalize our algorithm as the combination of a diversity-constrained optimization problem and an extrinsic-reward constrained optimization problem. And we solve the constrained optimization as a probabilistic inference task and use policy iteration to maximize the derived lower bound. Experimental results show that our method efficiently finds diverse strategies in a wide variety of reinforcement learning tasks. We further show that DGPO achieves a higher diversity score and has similar sample complexity and performance compared to other baselines.
Encoding protein dynamic information in graph representation for functional residue identification
Dec 15, 2021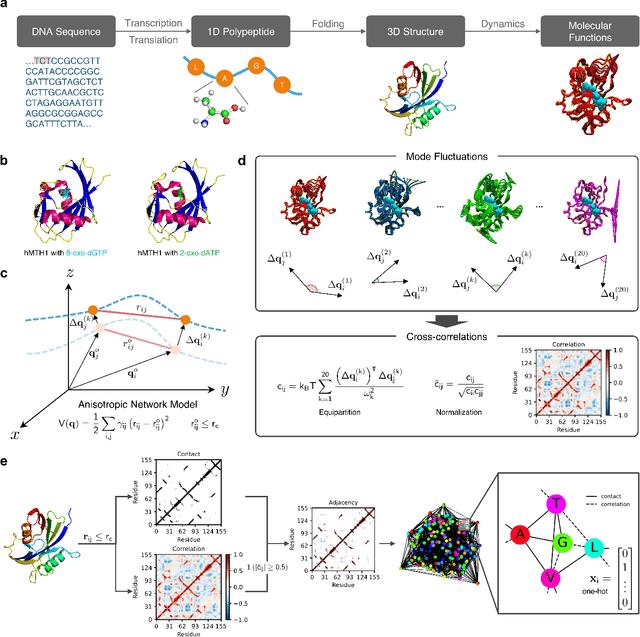



Recent advances in protein function prediction exploit graph-based deep learning approaches to correlate the structural and topological features of proteins with their molecular functions. However, proteins in vivo are not static but dynamic molecules that alter conformation for functional purposes. Here we apply normal mode analysis to native protein conformations and augment protein graphs by connecting edges between dynamically correlated residue pairs. In the multilabel function classification task, our method demonstrates a remarkable performance gain based on this dynamics-informed representation. The proposed graph neural network, ProDAR, increases the interpretability and generalizability of residue-level annotations and robustly reflects structural nuance in proteins. We elucidate the importance of dynamic information in graph representation by comparing class activation maps for the hMTH1, nitrophorin, and SARS-CoV-2 receptor binding domain. Our model successfully learns the dynamic fingerprints of proteins and provides molecular insights into protein functions, with vast untapped potential for broad biotechnology and pharmaceutical applications.