 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGPO: Discovering Multiple Strategies with Diversity-Guided Policy Optimization
Paper and Code
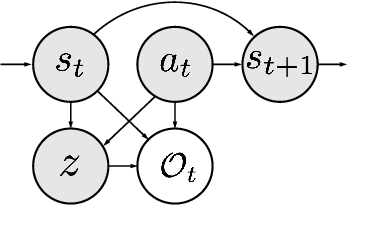

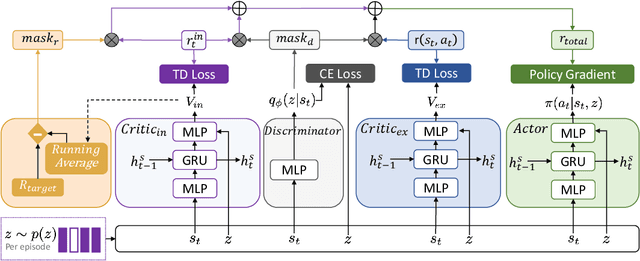
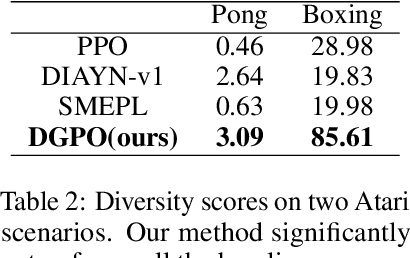
Recent algorithms designed for reinforcement learning tasks focus on finding a single optimal solution. However, in many practical applications, it is important to develop reasonable agents with diverse strategies. In this paper, we propose Diversity-Guided Policy Optimization (DGPO), an on-policy framework for discovering multiple strategies for the same task. Our algorithm uses diversity objectives to guide a latent code conditioned policy to learn a set of diverse strategies in a single training procedure. Specifically, we formalize our algorithm as the combination of a diversity-constrained optimization problem and an extrinsic-reward constrained optimization problem. And we solve the constrained optimization as a probabilistic inference task and use policy iteration to maximize the derived lower bound. Experimental results show that our method efficiently finds diverse strategies in a wide variety of reinforcement learning tasks. We further show that DGPO achieves a higher diversity score and has similar sample complexity and performance compared to other baselines.