 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Insight: Large Language Models for Materials Science Data Extraction
Jul 23, 2024



The vast majority of materials science knowledge exists in unstructured natural language, yet structured data is crucial for innovative and systematic materials design. Traditionally, the field has relied on manual curation and partial automation for data extraction for specific use cases. The advent of large language models (LLMs) represents a significant shift, potentially enabling efficient extraction of structured, actionable data from unstructured text by non-experts. While applying LLMs to materials science data extraction presents unique challenges, domain knowledge offers opportunities to guide and validate LLM outputs. This review provides a comprehensive overview of LLM-based structured data extraction in materials science, synthesizing current knowledge and outlining future directions. We address the lack of standardized guidelines and present frameworks for leveraging the synergy between LLMs and materials science expertise. This work serves as a foundational resource for researchers aiming to harness LLMs for data-driven materials research. The insights presented here could significantly enhance how researchers across disciplines access and utilize scientific information, potentially accelerating the development of novel materials for critical societal needs.
Deep Reinforcement Learning for Data-Driven Adaptive Scanning in Ptychography
Mar 29, 2022

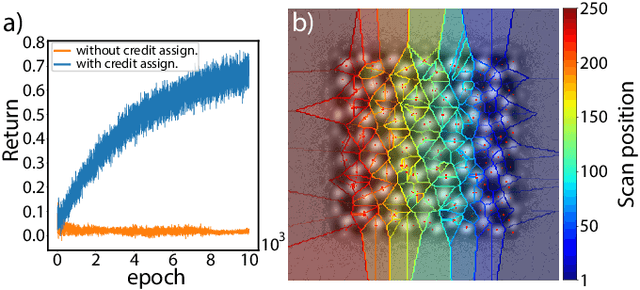

We present a method that lowers the dose required for a ptychographic reconstruction by adaptively scanning the specimen, thereby providing the required spatial information redundancy in the regions of highest importance. The proposed method is built upon a deep learning model that is trained by reinforcement learning (RL), using prior knowledge of the specimen structure from training data sets. We show that equivalent low-dose experiments using adaptive scanning outperform conventional ptychography experiments in terms of reconstruction resolution.