 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMTM: A Multi-Turn Multimodal Benchmark for Financial Reasoning and Agent Evaluation
Feb 03, 2026The financial domain poses substantial challenges for vision-language models (VLMs) due to specialized chart formats and knowledge-intensive reasoning requirements. However, existing financial benchmarks are largely single-turn and rely on a narrow set of question formats, limiting comprehensive evaluation in realistic application scenarios. To address this gap, we propose FinMTM, a multi-turn multimodal benchmark that expands diversity along both data and task dimensions. On the data side, we curate and annotate 11{,}133 bilingual (Chinese and English) financial QA pairs grounded in financial visuals, including candlestick charts, statistical plots, and report figures. On the task side, FinMTM covers single- and multiple-choice questions, multi-turn open-ended dialogues, and agent-based tasks. We further design task-specific evaluation protocols, including a set-overlap scoring rule for multiple-choice questions, a weighted combination of turn-level and session-level scores for multi-turn dialogues, and a composite metric that integrates planning quality with final outcomes for agent tasks. Extensive experimental evaluation of 22 VLMs reveal their limitations in fine-grained visual perception, long-context reasoning, and complex agent workflows.
VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning
May 29, 2025Video Anomaly Understanding (VAU) is essential for applications such as smart cities, security surveillance, and disaster alert systems, yet remains challenging due to its demand for fine-grained spatio-temporal perception and robust reasoning under ambiguity. Despite advances in anomaly detection, existing methods often lack interpretability and struggle to capture the causal and contextual aspects of abnormal events. This limitation is further compounded by the absence of comprehensive benchmarks for evaluating reasoning ability in anomaly scenarios. To address both challenges, we introduce VAU-R1, a data-efficient framework built upon Multimodal Large Language Models (MLLMs), which enhances anomaly reasoning through Reinforcement Fine-Tuning (RFT). Besides, we propose VAU-Bench, the first Chain-of-Thought benchmark tailored for video anomaly reasoning, featuring multiple-choice QA, detailed rationales, temporal annotations, and descriptive captions. Empirical results show that VAU-R1 significantly improves question answering accuracy, temporal grounding, and reasoning coherence across diverse contexts. Together, our method and benchmark establish a strong foundation for interpretable and reasoning-aware video anomaly understanding. Our code is available at https://github.com/GVCLab/VAU-R1.
LEGO: Learnable Expansion of Graph Operators for Multi-Modal Feature Fusion
Oct 02, 2024


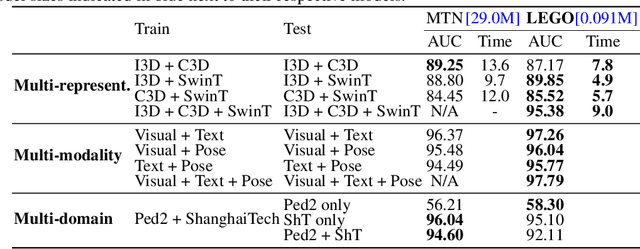
In computer vision tasks, features often come from diverse representations, domains, and modalities, such as text, images, and videos. Effectively fusing these features is essential for robust performance, especially with the availability of powerful pre-trained models like vision-language models. However, common fusion methods, such as concatenation, element-wise operations, and non-linear techniques, often fail to capture structural relationships, deep feature interactions, and suffer from inefficiency or misalignment of features across domains. In this paper, we shift from high-dimensional feature space to a lower-dimensional, interpretable graph space by constructing similarity graphs that encode feature relationships at different levels, e.g., clip, frame, patch, token, etc. To capture deeper interactions, we use graph power expansions and introduce a learnable graph fusion operator to combine these graph powers for more effective fusion. Our approach is relationship-centric, operates in a homogeneous space, and is mathematically principled, resembling element-wise similarity score aggregation via multilinear polynomials. We demonstrate the effectiveness of our graph-based fusion method on video anomaly detection, showing strong performance across multi-representational, multi-modal, and multi-domain feature fusion tasks.
Advancing Anomaly Detection: An Adaptation Model and a New Dataset
Feb 07, 2024



Industry surveillance is widely applicable in sectors like retail, manufacturing, education, and smart cities, each presenting unique anomalies requiring specialized detection. However, adapting anomaly detection models to novel viewpoints within the same scenario poses challenges. Extending these models to entirely new scenarios necessitates retraining or fine-tuning, a process that can be time consuming. To address these challenges, we propose the Scenario-Adaptive Anomaly Detection (SA2D) method, leveraging the few-shot learning framework for faster adaptation of pre-trained models to new concepts. Despite this approach, a significant challenge emerges from the absence of a comprehensive dataset with diverse scenarios and camera views. In response, we introduce the Multi-Scenario Anomaly Detection (MSAD) dataset, encompassing 14 distinct scenarios captured from various camera views. This real-world dataset is the first high-resolution anomaly detection dataset, offering a solid foundation for training superior models. MSAD includes diverse normal motion patterns, incorporating challenging variations like different lighting and weather conditions. Through experimentation, we validate the efficacy of SA2D, particularly when trained on the MSAD dataset. Our results show that SA2D not only excels under novel viewpoints within the same scenario but also demonstrates competitive performance when faced with entirely new scenarios. This highlights our method's potential in addressing challenges in detecting anomalies across diverse and evolving surveillance scenarios.