 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGO: Learnable Expansion of Graph Operators for Multi-Modal Feature Fusion
Paper and Code
Oct 02, 2024


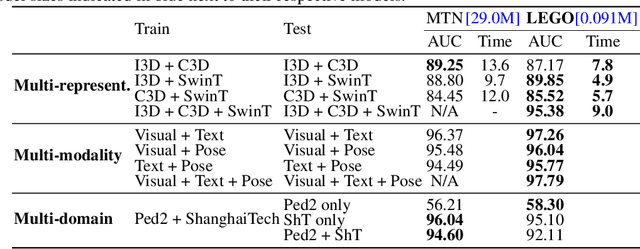
In computer vision tasks, features often come from diverse representations, domains, and modalities, such as text, images, and videos. Effectively fusing these features is essential for robust performance, especially with the availability of powerful pre-trained models like vision-language models. However, common fusion methods, such as concatenation, element-wise operations, and non-linear techniques, often fail to capture structural relationships, deep feature interactions, and suffer from inefficiency or misalignment of features across domains. In this paper, we shift from high-dimensional feature space to a lower-dimensional, interpretable graph space by constructing similarity graphs that encode feature relationships at different levels, e.g., clip, frame, patch, token, etc. To capture deeper interactions, we use graph power expansions and introduce a learnable graph fusion operator to combine these graph powers for more effective fusion. Our approach is relationship-centric, operates in a homogeneous space, and is mathematically principled, resembling element-wise similarity score aggregation via multilinear polynomials. We demonstrate the effectiveness of our graph-based fusion method on video anomaly detection, showing strong performance across multi-representational, multi-modal, and multi-domain feature fusion tasks.