 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Visual Surrogate Compression for Alzheimer's Disease Classification
Jan 29, 2026High-dimensional structural MRI (sMRI) images are widely used for Alzheimer's Disease (AD) diagnosis. Most existing methods for sMRI representation learning rely on 3D architectures (e.g., 3D CNNs), slice-wise feature extraction with late aggregation, or apply training-free feature extractions using 2D foundation models (e.g., DINO). However, these three paradigms suffer from high computational cost, loss of cross-slice relations, and limited ability to extract discriminative features, respectively. To address these challenges, we propose Multimodal Visual Surrogate Compression (MVSC). It learns to compress and adapt large 3D sMRI volumes into compact 2D features, termed as visual surrogates, which are better aligned with frozen 2D foundation models to extract powerful representations for final AD classification. MVSC has two key components: a Volume Context Encoder that captures global cross-slice context under textual guidance, and an Adaptive Slice Fusion module that aggregates slice-level information in a text-enhanced, patch-wise manner. Extensive experiments on three large-scale Alzheimer's disease benchmarks demonstrate our MVSC performs favourably on both binary and multi-class classification tasks compared against state-of-the-art methods.
LEGO: Learnable Expansion of Graph Operators for Multi-Modal Feature Fusion
Oct 02, 2024


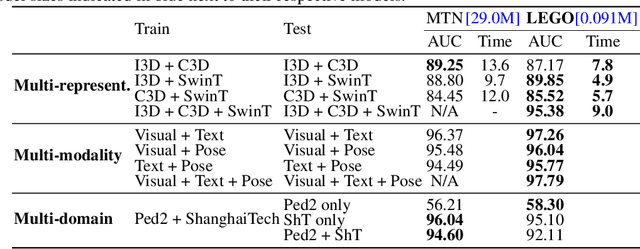
In computer vision tasks, features often come from diverse representations, domains, and modalities, such as text, images, and videos. Effectively fusing these features is essential for robust performance, especially with the availability of powerful pre-trained models like vision-language models. However, common fusion methods, such as concatenation, element-wise operations, and non-linear techniques, often fail to capture structural relationships, deep feature interactions, and suffer from inefficiency or misalignment of features across domains. In this paper, we shift from high-dimensional feature space to a lower-dimensional, interpretable graph space by constructing similarity graphs that encode feature relationships at different levels, e.g., clip, frame, patch, token, etc. To capture deeper interactions, we use graph power expansions and introduce a learnable graph fusion operator to combine these graph powers for more effective fusion. Our approach is relationship-centric, operates in a homogeneous space, and is mathematically principled, resembling element-wise similarity score aggregation via multilinear polynomials. We demonstrate the effectiveness of our graph-based fusion method on video anomaly detection, showing strong performance across multi-representational, multi-modal, and multi-domain feature fusion tasks.