 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-sample scoring and automatic selection of causal estimators
Dec 20, 2022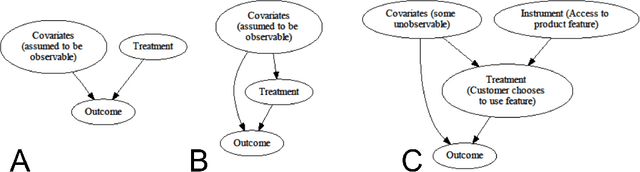
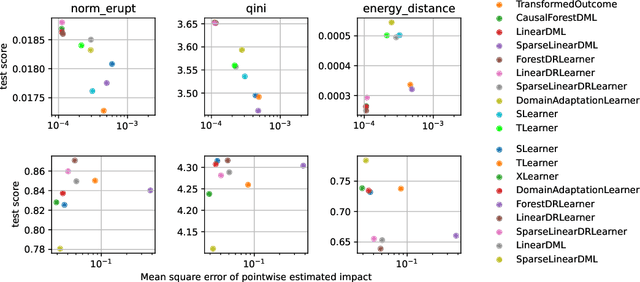
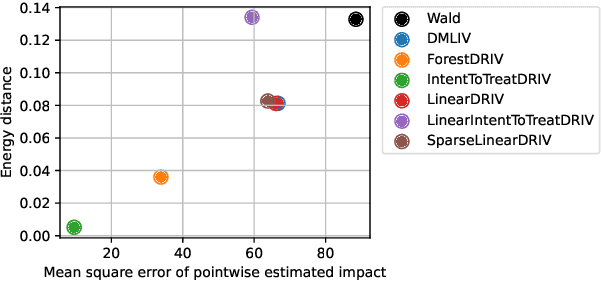
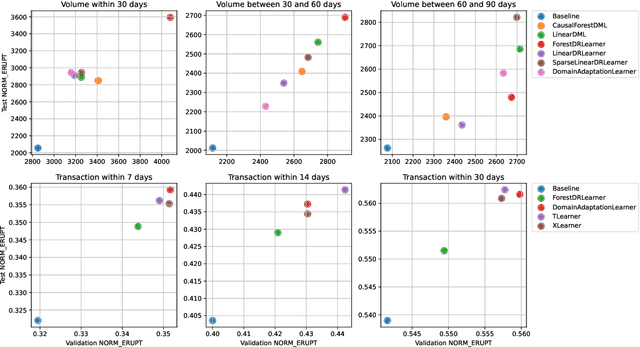
Recently, many causal estimators for Conditional Average Treatment Effect (CATE) and instrumental variable (IV) problems have been published and open sourced, allowing to estimate granular impact of both randomized treatments (such as A/B tests) and of user choices on the outcomes of interest. However, the practical application of such models has ben hampered by the lack of a valid way to score the performance of such models out of sample, in order to select the best one for a given application. We address that gap by proposing novel scoring approaches for both the CATE case and an important subset of instrumental variable problems, namely those where the instrumental variable is customer acces to a product feature, and the treatment is the customer's choice to use that feature. Being able to score model performance out of sample allows us to apply hyperparameter optimization methods to causal model selection and tuning. We implement that in an open source package that relies on DoWhy and EconML libraries for implementation of causal inference models (and also includes a Transformed Outcome model implementation), and on FLAML for hyperparameter optimization and for component models used in the causal models. We demonstrate on synthetic data that optimizing the proposed scores is a reliable method for choosing the model and its hyperparameter values, whose estimates are close to the true impact, in the randomized CATE and IV cases. Further, we provide examles of applying these methods to real customer data from Wise.
Continual task learning in natural and artificial agents
Oct 10, 2022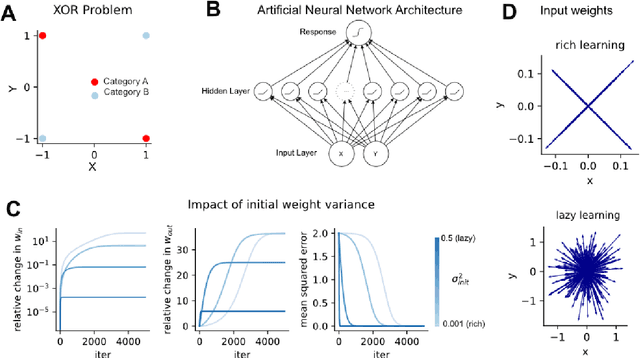
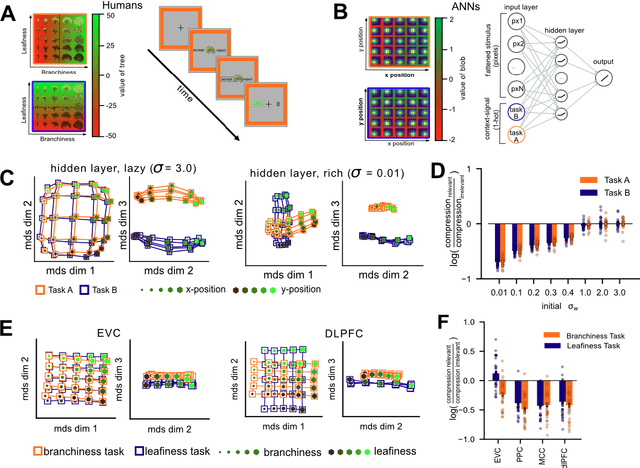
How do humans and other animals learn new tasks? A wave of brain recording studies has investigated how neural representations change during task learning, with a focus on how tasks can be acquired and coded in ways that minimise mutual interference. We review recent work that has explored the geometry and dimensionality of neural task representations in neocortex, and computational models that have exploited these findings to understand how the brain may partition knowledge between tasks. We discuss how ideas from machine learning, including those that combine supervised and unsupervised learning, are helping neuroscientists understand how natural tasks are learned and coded in biological brains.
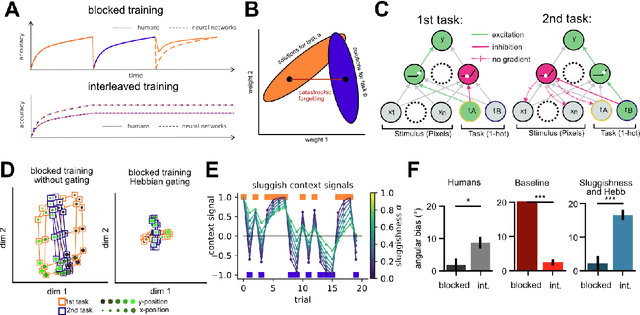
Modelling continual learning in humans with Hebbian context gating and exponentially decaying task signals
Mar 22, 2022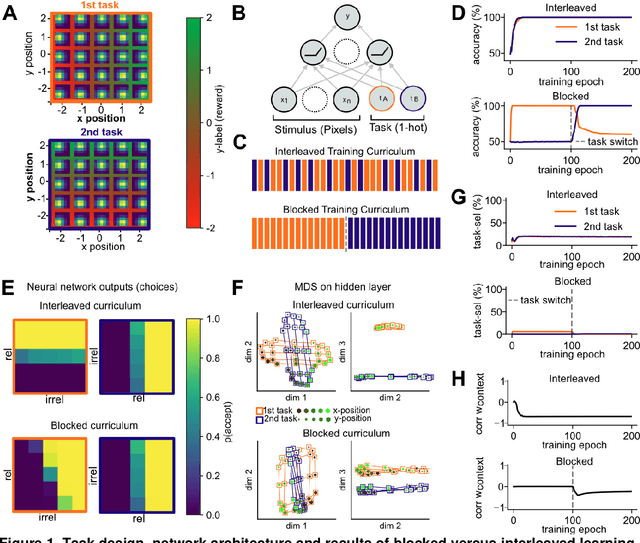
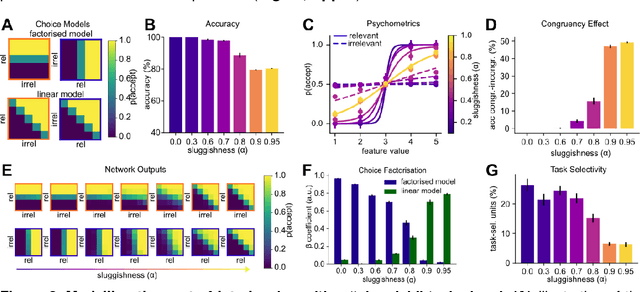
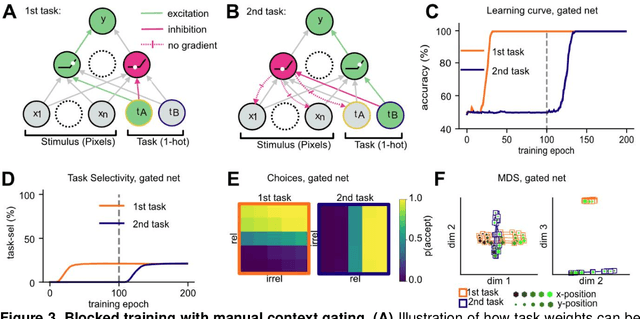

Humans can learn several tasks in succession with minimal mutual interference but perform more poorly when trained on multiple tasks at once. The opposite is true for standard deep neural networks. Here, we propose novel computational constraints for artificial neural networks, inspired by earlier work on gating in the primate prefrontal cortex, that capture the cost of interleaved training and allow the network to learn two tasks in sequence without forgetting. We augment standard stochastic gradient descent with two algorithmic motifs, so-called "sluggish" task units and a Hebbian training step that strengthens connections between task units and hidden units that encode task-relevant information. We found that the "sluggish" units introduce a switch-cost during training, which biases representations under interleaved training towards a joint representation that ignores the contextual cue, while the Hebbian step promotes the formation of a gating scheme from task units to the hidden layer that produces orthogonal representations which are perfectly guarded against interference. Validating the model on previously published human behavioural data revealed that it matches performance of participants who had been trained on blocked or interleaved curricula, and that these performance differences were driven by misestimation of the true category boundary.