 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShap-Select: Lightweight Feature Selection Using SHAP Values and Regression
Oct 09, 2024

Feature selection is an essential process in machine learning, especially when dealing with high-dimensional datasets. It helps reduce the complexity of machine learning models, improve performance, mitigate overfitting, and decrease computation time. This paper presents a novel feature selection framework, shap-select. The framework conducts a linear or logistic regression of the target on the Shapley values of the features, on the validation set, and uses the signs and significance levels of the regression coefficients to implement an efficient heuristic for feature selection in tabular regression and classification tasks. We evaluate shap-select on the Kaggle credit card fraud dataset, demonstrating its effectiveness compared to established methods such as Recursive Feature Elimination (RFE), HISEL (a mutual information-based feature selection method), Boruta and a simpler Shapley value-based method. Our findings show that shap-select combines interpretability, computational efficiency, and performance, offering a robust solution for feature selection.
OTLP: Output Thresholding Using Mixed Integer Linear Programming
May 18, 2024



Output thresholding is the technique to search for the best threshold to be used during inference for any classifiers that can produce probability estimates on train and testing datasets. It is particularly useful in high imbalance classification problems where the default threshold is not able to refer to imbalance in class distributions and fail to give the best performance. This paper proposes OTLP, a thresholding framework using mixed integer linear programming which is model agnostic, can support different objective functions and different set of constraints for a diverse set of problems including both balanced and imbalanced classification problems. It is particularly useful in real world applications where the theoretical thresholding techniques are not able to address to product related requirements and complexity of the applications which utilize machine learning models. Through the use of Credit Card Fraud Detection Dataset, we evaluate the usefulness of the framework.
Out-of-sample scoring and automatic selection of causal estimators
Dec 20, 2022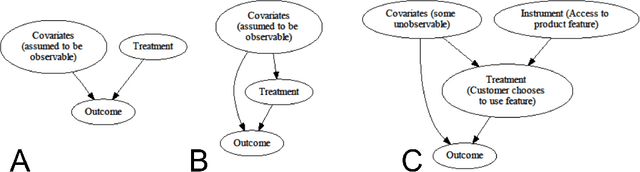
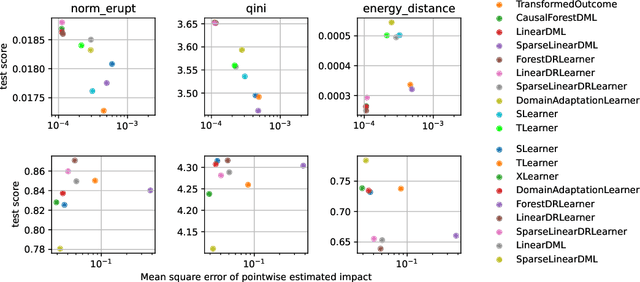
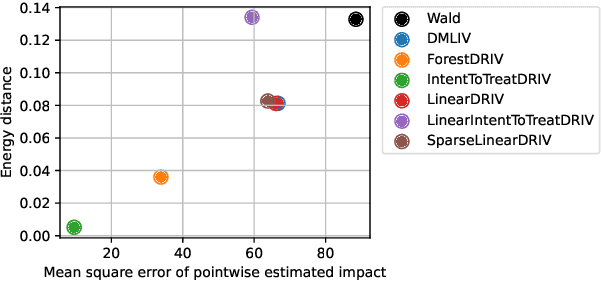
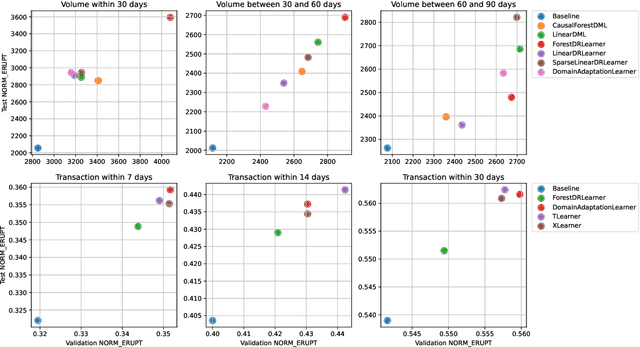
Recently, many causal estimators for Conditional Average Treatment Effect (CATE) and instrumental variable (IV) problems have been published and open sourced, allowing to estimate granular impact of both randomized treatments (such as A/B tests) and of user choices on the outcomes of interest. However, the practical application of such models has ben hampered by the lack of a valid way to score the performance of such models out of sample, in order to select the best one for a given application. We address that gap by proposing novel scoring approaches for both the CATE case and an important subset of instrumental variable problems, namely those where the instrumental variable is customer acces to a product feature, and the treatment is the customer's choice to use that feature. Being able to score model performance out of sample allows us to apply hyperparameter optimization methods to causal model selection and tuning. We implement that in an open source package that relies on DoWhy and EconML libraries for implementation of causal inference models (and also includes a Transformed Outcome model implementation), and on FLAML for hyperparameter optimization and for component models used in the causal models. We demonstrate on synthetic data that optimizing the proposed scores is a reliable method for choosing the model and its hyperparameter values, whose estimates are close to the true impact, in the randomized CATE and IV cases. Further, we provide examles of applying these methods to real customer data from Wise.
Probabilistic hypergraph grammars for efficient molecular optimization
Jun 05, 2019
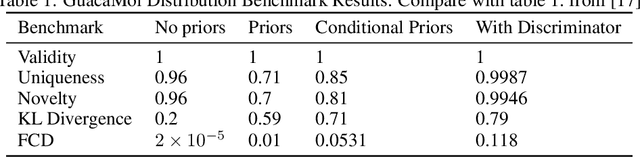
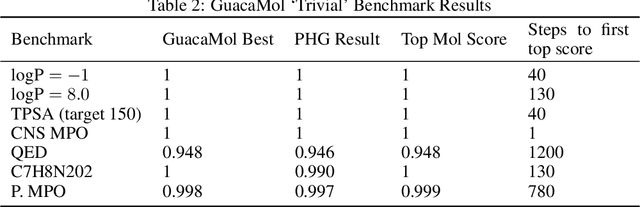
We present an approach to make molecular optimization more efficient. We infer a hypergraph replacement grammar from the ChEMBL database, count the frequencies of particular rules being used to expand particular nonterminals in other rules, and use these as conditional priors for the policy model. Simulating random molecules from the resulting probabilistic grammar, we show that conditional priors result in a molecular distribution closer to the training set than using equal rule probabilities or unconditional priors. We then treat molecular optimization as a reinforcement learning problem, using a novel modification of the policy gradient algorithm - batch-advantage: using individual rewards minus the batch average reward to weight the log probability loss. The reinforcement learning agent is tasked with building molecules using this grammar, with the goal of maximizing benchmark scores available from the literature. To do so, the agent has policies both to choose the next node in the graph to expand and to select the next grammar rule to apply. The policies are implemented using the Transformer architecture with the partially expanded graph as the input at each step. We show that using the empirical priors as the starting point for a policy eliminates the need for pre-training, and allows us to reach optima faster. We achieve competitive performance on common benchmarks from the literature, such as penalized logP and QED, with only hundreds of training steps on a budget GPU instance.
Grammars and reinforcement learning for molecule optimization
Nov 27, 2018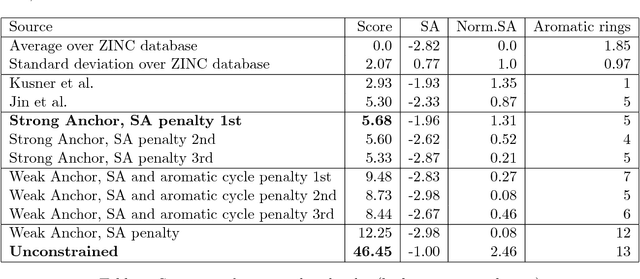



We seek to automate the design of molecules based on specific chemical properties. Our primary contributions are a simpler method for generating SMILES strings guaranteed to be chemically valid, using a combination of a new context-free grammar for SMILES and additional masking logic; and casting the molecular property optimization as a reinforcement learning problem, specifically best-of-batch policy gradient applied to a Transformer model architecture. This approach uses substantially fewer model steps per atom than earlier approaches, thus enabling generation of larger molecules, and beats previous state-of-the art baselines by a significant margin. Applying reinforcement learning to a combination of a custom context-free grammar with additional masking to enforce non-local constraints is applicable to any optimization of a graph structure under a mixture of local and nonlocal constraints.