 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling continual learning in humans with Hebbian context gating and exponentially decaying task signals
Paper and Code
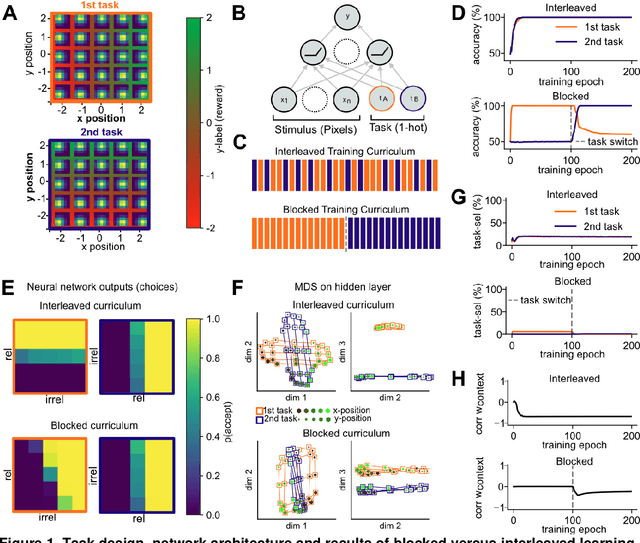
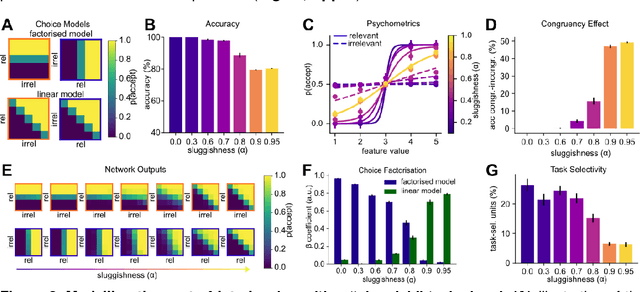
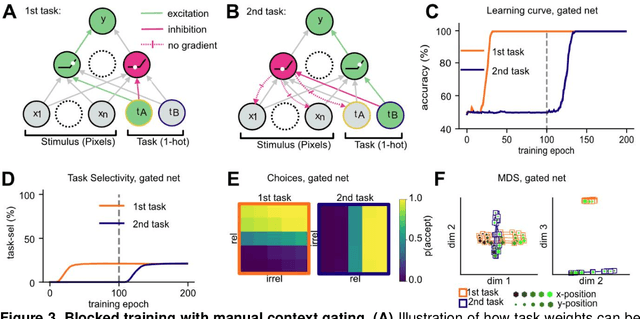

Humans can learn several tasks in succession with minimal mutual interference but perform more poorly when trained on multiple tasks at once. The opposite is true for standard deep neural networks. Here, we propose novel computational constraints for artificial neural networks, inspired by earlier work on gating in the primate prefrontal cortex, that capture the cost of interleaved training and allow the network to learn two tasks in sequence without forgetting. We augment standard stochastic gradient descent with two algorithmic motifs, so-called "sluggish" task units and a Hebbian training step that strengthens connections between task units and hidden units that encode task-relevant information. We found that the "sluggish" units introduce a switch-cost during training, which biases representations under interleaved training towards a joint representation that ignores the contextual cue, while the Hebbian step promotes the formation of a gating scheme from task units to the hidden layer that produces orthogonal representations which are perfectly guarded against interference. Validating the model on previously published human behavioural data revealed that it matches performance of participants who had been trained on blocked or interleaved curricula, and that these performance differences were driven by misestimation of the true category boundary.