 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-centric learning: from external reward maximization to internal knowledge curation
Jul 29, 2025The pursuit of general intelligence has traditionally centered on external objectives: an agent's control over its environments or mastery of specific tasks. This external focus, however, can produce specialized agents that lack adaptability. We propose representational empowerment, a new perspective towards a truly agent-centric learning paradigm by moving the locus of control inward. This objective measures an agent's ability to controllably maintain and diversify its own knowledge structures. We posit that the capacity -- to shape one's own understanding -- is an element for achieving better ``preparedness'' distinct from direct environmental influence. Focusing on internal representations as the main substrate for computing empowerment offers a new lens through which to design adaptable intelligent systems.
Analogy making as amortised model construction
Jul 22, 2025Humans flexibly construct internal models to navigate novel situations. To be useful, these internal models must be sufficiently faithful to the environment that resource-limited planning leads to adequate outcomes; equally, they must be tractable to construct in the first place. We argue that analogy plays a central role in these processes, enabling agents to reuse solution-relevant structure from past experiences and amortise the computational costs of both model construction (construal) and planning. Formalising analogies as partial homomorphisms between Markov decision processes, we sketch a framework in which abstract modules, derived from previous construals, serve as composable building blocks for new ones. This modular reuse allows for flexible adaptation of policies and representations across domains with shared structural essence.
Harmonizing Program Induction with Rate-Distortion Theory
May 08, 2024Many aspects of human learning have been proposed as a process of constructing mental programs: from acquiring symbolic number representations to intuitive theories about the world. In parallel, there is a long-tradition of using information processing to model human cognition through Rate Distortion Theory (RDT). Yet, it is still poorly understood how to apply RDT when mental representations take the form of programs. In this work, we adapt RDT by proposing a three way trade-off among rate (description length), distortion (error), and computational costs (search budget). We use simulations on a melody task to study the implications of this trade-off, and show that constructing a shared program library across tasks provides global benefits. However, this comes at the cost of sensitivity to curricula, which is also characteristic of human learners. Finally, we use methods from partial information decomposition to generate training curricula that induce more effective libraries and better generalization.
Modelling continual learning in humans with Hebbian context gating and exponentially decaying task signals
Mar 22, 2022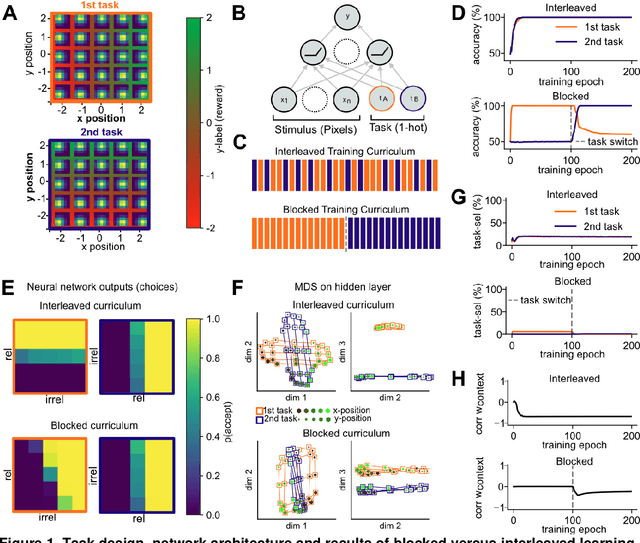
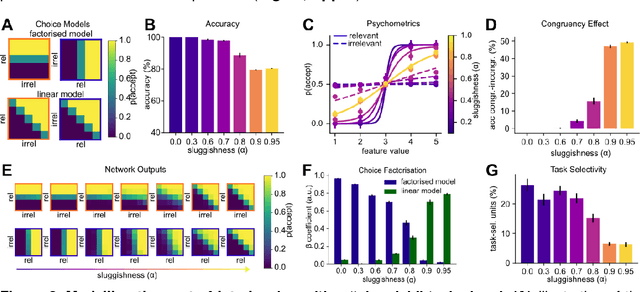
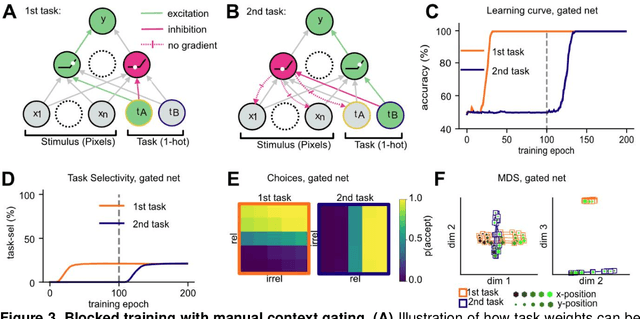

Humans can learn several tasks in succession with minimal mutual interference but perform more poorly when trained on multiple tasks at once. The opposite is true for standard deep neural networks. Here, we propose novel computational constraints for artificial neural networks, inspired by earlier work on gating in the primate prefrontal cortex, that capture the cost of interleaved training and allow the network to learn two tasks in sequence without forgetting. We augment standard stochastic gradient descent with two algorithmic motifs, so-called "sluggish" task units and a Hebbian training step that strengthens connections between task units and hidden units that encode task-relevant information. We found that the "sluggish" units introduce a switch-cost during training, which biases representations under interleaved training towards a joint representation that ignores the contextual cue, while the Hebbian step promotes the formation of a gating scheme from task units to the hidden layer that produces orthogonal representations which are perfectly guarded against interference. Validating the model on previously published human behavioural data revealed that it matches performance of participants who had been trained on blocked or interleaved curricula, and that these performance differences were driven by misestimation of the true category boundary.
Episodic memory for continual model learning
Dec 04, 2017
Both the human brain and artificial learning agents operating in real-world or comparably complex environments are faced with the challenge of online model selection. In principle this challenge can be overcome: hierarchical Bayesian inference provides a principled method for model selection and it converges on the same posterior for both off-line (i.e. batch) and online learning. However, maintaining a parameter posterior for each model in parallel has in general an even higher memory cost than storing the entire data set and is consequently clearly unfeasible. Alternatively, maintaining only a limited set of models in memory could limit memory requirements. However, sufficient statistics for one model will usually be insufficient for fitting a different kind of model, meaning that the agent loses information with each model change. We propose that episodic memory can circumvent the challenge of limited memory-capacity online model selection by retaining a selected subset of data points. We design a method to compute the quantities necessary for model selection even when the data is discarded and only statistics of one (or few) learnt models are available. We demonstrate on a simple model that a limited-sized episodic memory buffer, when the content is optimised to retain data with statistics not matching the current representation, can resolve the fundamental challenge of online model selection.