 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAVAE: A VAE with Adaptable Priors Explains Contextual Modulation in the Visual Cortex
Feb 12, 2026The brain interprets visual information through learned regularities, a computation formalized as probabilistic inference under a prior. The visual cortex establishes priors for this inference, some delivered through established top-down connections that inform low-level cortices about statistics represented at higher levels in the cortical hierarchy. While evidence shows that adaptation leads to priors reflecting the structure of natural images, it remains unclear whether similar priors can be flexibly acquired when learning a specific task. To investigate this, we built a generative model of V1 optimized for a simple discrimination task and analyzed it together with large-scale recordings from mice performing an analogous task. In line with recent approaches, we assumed that neuronal activity in V1 corresponds to latent posteriors in the generative model, enabling investigation of task-related priors in neuronal responses. To obtain a flexible test bed, we extended the VAE formalism so that a task can be acquired efficiently by reusing previously learned representations. Task-specific priors learned by this Task-Amortized VAE were used to investigate biases in mice and model when presenting stimuli that violated trained task statistics. Mismatch between learned task statistics and incoming sensory evidence produced signatures of uncertainty in stimulus category in the TAVAE posterior, reflecting properties of bimodal response profiles in V1 recordings. The task-optimized generative model accounted for key characteristics of V1 population activity, including within-day updates to population responses. Our results confirm that flexible task-specific contextual priors can be learned on demand by the visual system and deployed as early as the entry level of visual cortex.
Top-down inference in an early visual cortex inspired hierarchical Variational Autoencoder
Jun 01, 2022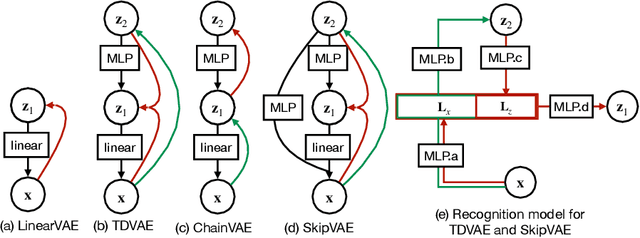



Interpreting computations in the visual cortex as learning and inference in a generative model of the environment has received wide support both in neuroscience and cognitive science. However, hierarchical computations, a hallmark of visual cortical processing, has remained impervious for generative models because of a lack of adequate tools to address it. Here we capitalize on advances in Variational Autoencoders (VAEs) to investigate the early visual cortex with sparse coding hierarchical VAEs trained on natural images. We design alternative architectures that vary both in terms of the generative and the recognition components of the two latent-layer VAE. We show that representations similar to the one found in the primary and secondary visual cortices naturally emerge under mild inductive biases. Importantly, a nonlinear representation for texture-like patterns is a stable property of the high-level latent space resistant to the specific architecture of the VAE, reminiscent of the secondary visual cortex. We show that a neuroscience-inspired choice of the recognition model, which features a top-down processing component is critical for two signatures of computations with generative models: learning higher order moments of the posterior beyond the mean and image inpainting. Patterns in higher order response statistics provide inspirations for neuroscience to interpret response correlations and for machine learning to evaluate the learned representations through more detailed characterization of the posterior.
Episodic memory for continual model learning
Dec 04, 2017
Both the human brain and artificial learning agents operating in real-world or comparably complex environments are faced with the challenge of online model selection. In principle this challenge can be overcome: hierarchical Bayesian inference provides a principled method for model selection and it converges on the same posterior for both off-line (i.e. batch) and online learning. However, maintaining a parameter posterior for each model in parallel has in general an even higher memory cost than storing the entire data set and is consequently clearly unfeasible. Alternatively, maintaining only a limited set of models in memory could limit memory requirements. However, sufficient statistics for one model will usually be insufficient for fitting a different kind of model, meaning that the agent loses information with each model change. We propose that episodic memory can circumvent the challenge of limited memory-capacity online model selection by retaining a selected subset of data points. We design a method to compute the quantities necessary for model selection even when the data is discarded and only statistics of one (or few) learnt models are available. We demonstrate on a simple model that a limited-sized episodic memory buffer, when the content is optimised to retain data with statistics not matching the current representation, can resolve the fundamental challenge of online model selection.