 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMatic: Neural Architecture Search via Large Language Models and Quality-Diversity Optimization
Jun 01, 2023



Large Language Models (LLMs) have emerged as powerful tools capable of accomplishing a broad spectrum of tasks. Their abilities span numerous areas, and one area where they have made a significant impact is in the domain of code generation. In this context, we view LLMs as mutation and crossover tools. Meanwhile, Quality-Diversity (QD) algorithms are known to discover diverse and robust solutions. By merging the code-generating abilities of LLMs with the diversity and robustness of QD solutions, we introduce LLMatic, a Neural Architecture Search (NAS) algorithm. While LLMs struggle to conduct NAS directly through prompts, LLMatic uses a procedural approach, leveraging QD for prompts and network architecture to create diverse and highly performant networks. We test LLMatic on the CIFAR-10 image classification benchmark, demonstrating that it can produce competitive networks with just $2,000$ searches, even without prior knowledge of the benchmark domain or exposure to any previous top-performing models for the benchmark.
Training Feedforward Neural Networks with Bayesian Hyper-Heuristics
Mar 29, 2023The process of training feedforward neural networks (FFNNs) can benefit from an automated process where the best heuristic to train the network is sought out automatically by means of a high-level probabilistic-based heuristic. This research introduces a novel population-based Bayesian hyper-heuristic (BHH) that is used to train feedforward neural networks (FFNNs). The performance of the BHH is compared to that of ten popular low-level heuristics, each with different search behaviours. The chosen heuristic pool consists of classic gradient-based heuristics as well as meta-heuristics (MHs). The empirical process is executed on fourteen datasets consisting of classification and regression problems with varying characteristics. The BHH is shown to be able to train FFNNs well and provide an automated method for finding the best heuristic to train the FFNNs at various stages of the training process.
Towards Objective Metrics for Procedurally Generated Video Game Levels
Jan 25, 2022
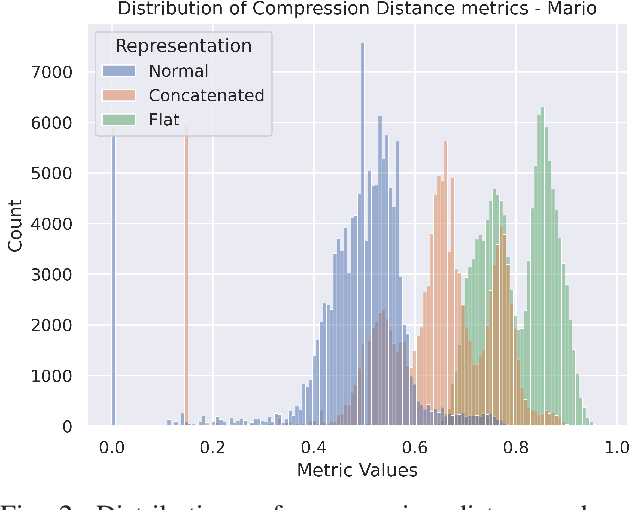
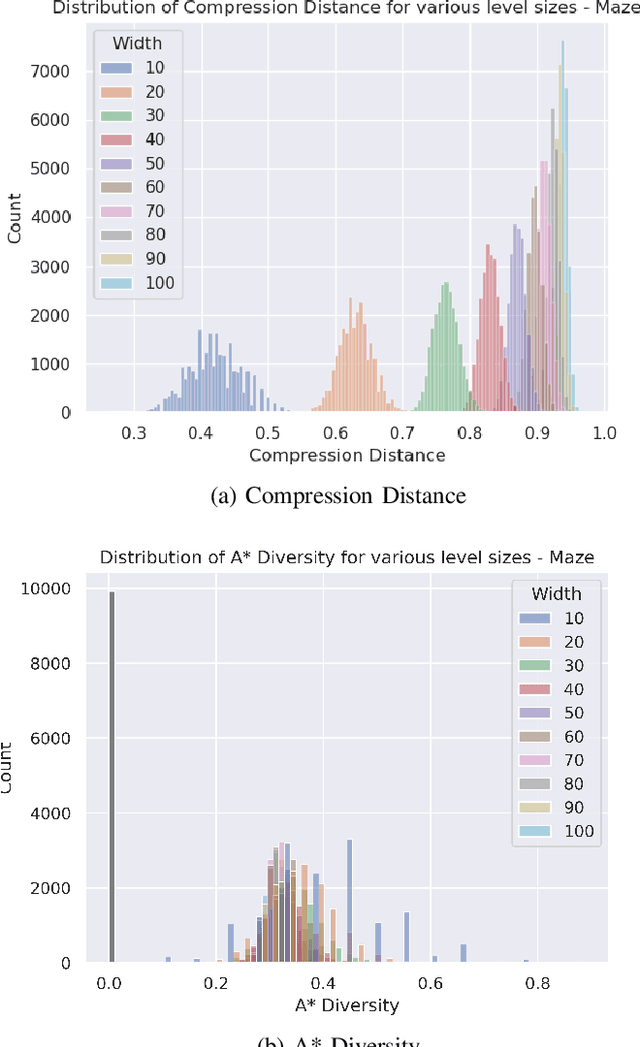
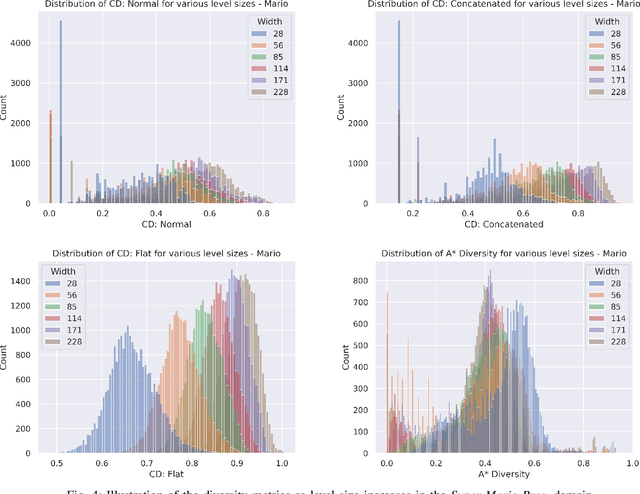
With increasing interest in procedural content generation by academia and game developers alike, it is vital that different approaches can be compared fairly. However, evaluating procedurally generated video game levels is often difficult, due to the lack of standardised, game-independent metrics. In this paper, we introduce two simulation-based evaluation metrics that involve analysing the behaviour of an A* agent to measure the diversity and difficulty of generated levels in a general, game-independent manner. Diversity is calculated by comparing action trajectories from different levels using the edit distance, and difficulty is measured as how much exploration and expansion of the A* search tree is necessary before the agent can solve the level. We demonstrate that our diversity metric is more robust to changes in level size and representation than current methods and additionally measures factors that directly affect playability, instead of focusing on visual information. The difficulty metric shows promise, as it correlates with existing estimates of difficulty in one of the tested domains, but it does face some challenges in the other domain. Finally, to promote reproducibility, we publicly release our evaluation framework.