 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Program Search
Feb 07, 2026Genetic Programming yields interpretable programs, but small syntactic mutations can induce large, unpredictable behavioral shifts, degrading locality and sample efficiency. We frame this as an operator-design problem: learn a continuous program space where latent distance has behavioral meaning, then design mutation operators that exploit this structure without changing the evolutionary optimizer. We make locality measurable by tracking action-level divergence under controlled latent perturbations, identifying an empirical trust region for behavior-local continuous variation. Using a compact trading-strategy DSL with four semantic components (long/short entry and exit), we learn a matching block-factorized embedding and compare isotropic Gaussian mutation over the full latent space to geometry-compiled mutation that restricts updates to semantically paired entry--exit subspaces and proposes directions using a learned flow-based model trained on logged mutation outcomes. Under identical $(μ+λ)$ evolution strategies and fixed evaluation budgets across five assets, the learned mutation operator discovers strong strategies using an order of magnitude fewer evaluations and achieves the highest median out-of-sample Sharpe ratio. Although isotropic mutation occasionally attains higher peak performance, geometry-compiled mutation yields faster, more reliable progress, demonstrating that semantically aligned mutation can substantially improve search efficiency without modifying the underlying evolutionary algorithm.
GVGAI-LLM: Evaluating Large Language Model Agents with Infinite Games
Aug 11, 2025We introduce GVGAI-LLM, a video game benchmark for evaluating the reasoning and problem-solving capabilities of large language models (LLMs). Built on the General Video Game AI framework, it features a diverse collection of arcade-style games designed to test a model's ability to handle tasks that differ from most existing LLM benchmarks. The benchmark leverages a game description language that enables rapid creation of new games and levels, helping to prevent overfitting over time. Each game scene is represented by a compact set of ASCII characters, allowing for efficient processing by language models. GVGAI-LLM defines interpretable metrics, including the meaningful step ratio, step efficiency, and overall score, to assess model behavior. Through zero-shot evaluations across a broad set of games and levels with diverse challenges and skill depth, we reveal persistent limitations of LLMs in spatial reasoning and basic planning. Current models consistently exhibit spatial and logical errors, motivating structured prompting and spatial grounding techniques. While these interventions lead to partial improvements, the benchmark remains very far from solved. GVGAI-LLM provides a reproducible testbed for advancing research on language model capabilities, with a particular emphasis on agentic behavior and contextual reasoning.
ScriptDoctor: Automatic Generation of PuzzleScript Games via Large Language Models and Tree Search
Jun 06, 2025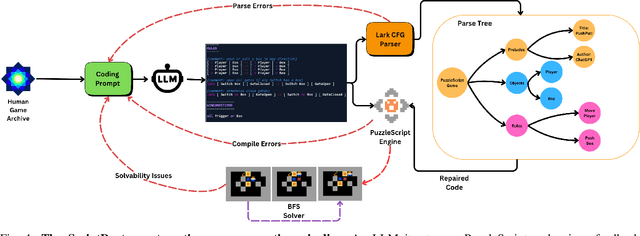


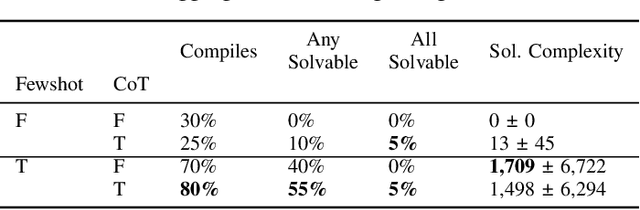
There is much interest in using large pre-trained models in Automatic Game Design (AGD), whether via the generation of code, assets, or more abstract conceptualization of design ideas. But so far this interest largely stems from the ad hoc use of such generative models under persistent human supervision. Much work remains to show how these tools can be integrated into longer-time-horizon AGD pipelines, in which systems interface with game engines to test generated content autonomously. To this end, we introduce ScriptDoctor, a Large Language Model (LLM)-driven system for automatically generating and testing games in PuzzleScript, an expressive but highly constrained description language for turn-based puzzle games over 2D gridworlds. ScriptDoctor generates and tests game design ideas in an iterative loop, where human-authored examples are used to ground the system's output, compilation errors from the PuzzleScript engine are used to elicit functional code, and search-based agents play-test generated games. ScriptDoctor serves as a concrete example of the potential of automated, open-ended LLM-based workflows in generating novel game content.
Word2Minecraft: Generating 3D Game Levels through Large Language Models
Mar 18, 2025We present Word2Minecraft, a system that leverages large language models to generate playable game levels in Minecraft based on structured stories. The system transforms narrative elements-such as protagonist goals, antagonist challenges, and environmental settings-into game levels with both spatial and gameplay constraints. We introduce a flexible framework that allows for the customization of story complexity, enabling dynamic level generation. The system employs a scaling algorithm to maintain spatial consistency while adapting key game elements. We evaluate Word2Minecraft using both metric-based and human-based methods. Our results show that GPT-4-Turbo outperforms GPT-4o-Mini in most areas, including story coherence and objective enjoyment, while the latter excels in aesthetic appeal. We also demonstrate the system' s ability to generate levels with high map enjoyment, offering a promising step forward in the intersection of story generation and game design. We open-source the code at https://github.com/JMZ-kk/Word2Minecraft/tree/word2mc_v0
GameTraversalBenchmark: Evaluating Planning Abilities Of Large Language Models Through Traversing 2D Game Maps
Oct 10, 2024



Large language models (LLMs) have recently demonstrated great success in generating and understanding natural language. While they have also shown potential beyond the domain of natural language, it remains an open question as to what extent and in which way these LLMs can plan. We investigate their planning capabilities by proposing GameTraversalBenchmark (GTB), a benchmark consisting of diverse 2D grid-based game maps. An LLM succeeds if it can traverse through given objectives, with a minimum number of steps and a minimum number of generation errors. We evaluate a number of LLMs on GTB and found that GPT-4-Turbo achieved the highest score of 44.97% on GTB\_Score (GTBS), a composite score that combines the three above criteria. Furthermore, we preliminarily test large reasoning models, namely o1, which scores $67.84\%$ on GTBS, indicating that the benchmark remains challenging for current models. Code, data, and documentation are available at https://github.com/umair-nasir14/Game-Traversal-Benchmark.
Level Generation Through Large Language Models
Feb 11, 2023Large Language Models (LLMs) are powerful tools, capable of leveraging their training on natural language to write stories, generate code, and answer questions. But can they generate functional video game levels? Game levels, with their complex functional constraints and spatial relationships in more than one dimension, are very different from the kinds of data an LLM typically sees during training. Datasets of game levels are also hard to come by, potentially taxing the abilities of these data-hungry models. We investigate the use of LLMs to generate levels for the game Sokoban, finding that LLMs are indeed capable of doing so, and that their performance scales dramatically with dataset size. We also perform preliminary experiments on controlling LLM level generators and discuss promising areas for future work.
Augmentative Topology Agents For Open-Ended Learning
Oct 20, 2022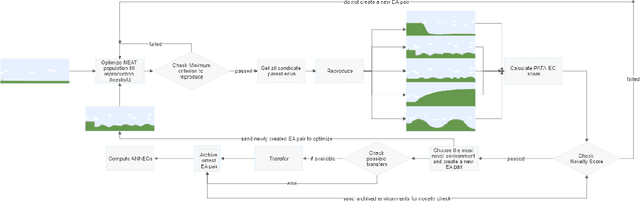
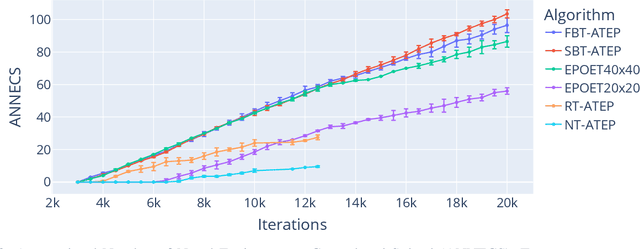
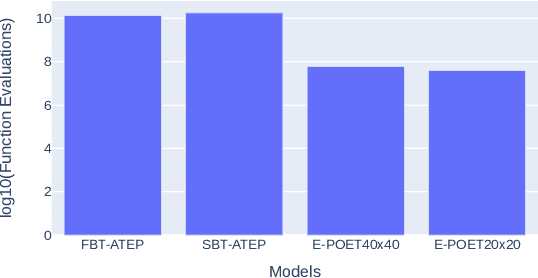
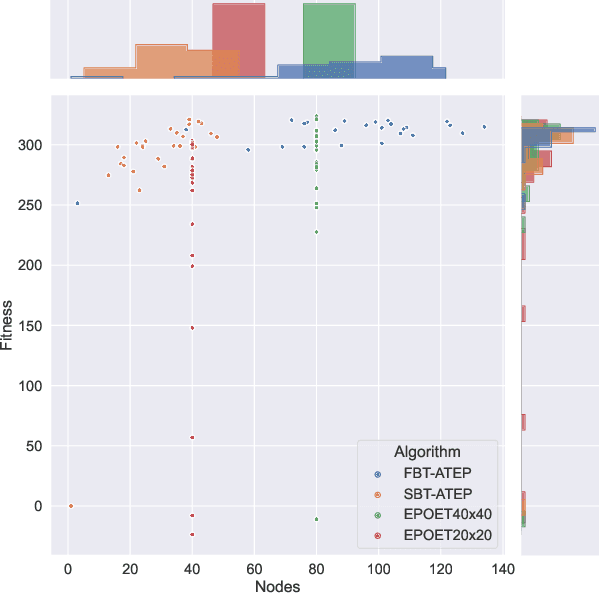
In this work, we tackle the problem of open-ended learning by introducing a method that simultaneously evolves agents and increasingly challenging environments. Unlike previous open-ended approaches that optimize agents using a fixed neural network topology, we hypothesize that generalization can be improved by allowing agents' controllers to become more complex as they encounter more difficult environments. Our method, Augmentative Topology EPOET (ATEP), extends the Enhanced Paired Open-Ended Trailblazer (EPOET) algorithm by allowing agents to evolve their own neural network structures over time, adding complexity and capacity as necessary. Empirical results demonstrate that ATEP results in general agents capable of solving more environments than a fixed-topology baseline. We also investigate mechanisms for transferring agents between environments and find that a species-based approach further improves the performance and generalization of agents.
Geographical Distance Is The New Hyperparameter: A Case Study Of Finding The Optimal Pre-trained Language For English-isiZulu Machine Translation
May 17, 2022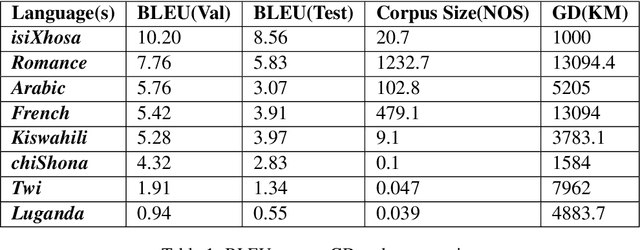

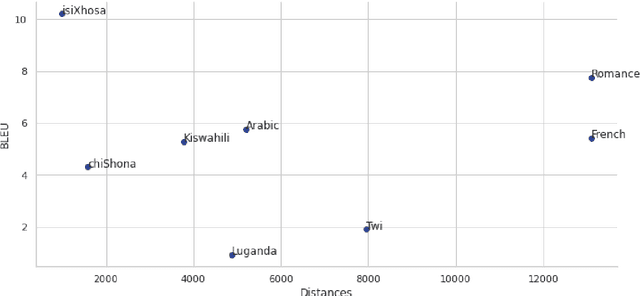
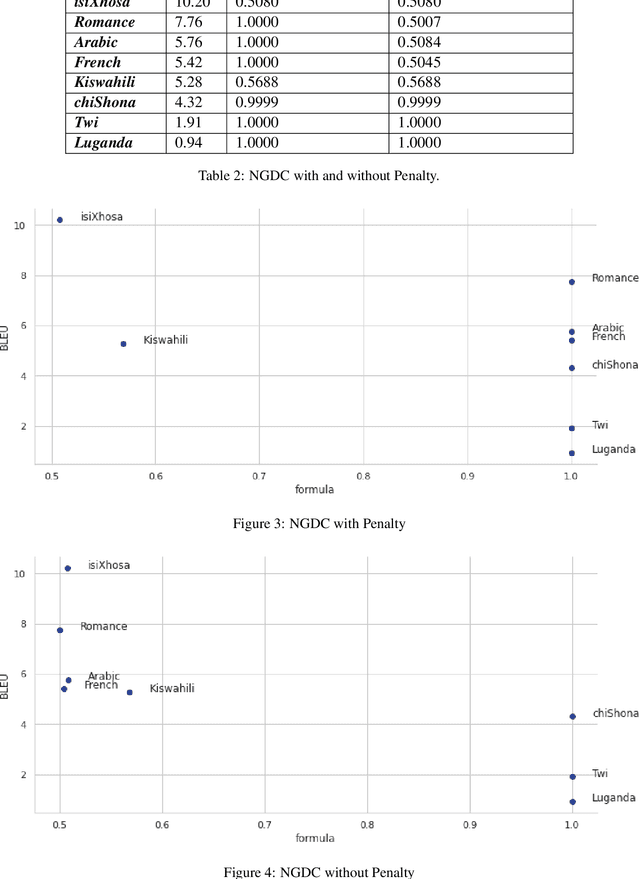
Stemming from the limited availability of datasets and textual resources for low-resource languages such as isiZulu, there is a significant need to be able to harness knowledge from pre-trained models to improve low resource machine translation. Moreover, a lack of techniques to handle the complexities of morphologically rich languages has compounded the unequal development of translation models, with many widely spoken African languages being left behind. This study explores the potential benefits of transfer learning in an English-isiZulu translation framework. The results indicate the value of transfer learning from closely related languages to enhance the performance of low-resource translation models, thus providing a key strategy for low-resource translation going forward. We gathered results from 8 different language corpora, including one multi-lingual corpus, and saw that isiXhosa-isiZulu outperformed all languages, with a BLEU score of 8.56 on the test set which was better from the multi-lingual corpora pre-trained model by 2.73. We also derived a new coefficient, Nasir's Geographical Distance Coefficient (NGDC) which provides an easy selection of languages for the pre-trained models. NGDC also indicated that isiXhosa should be selected as the language for the pre-trained model.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022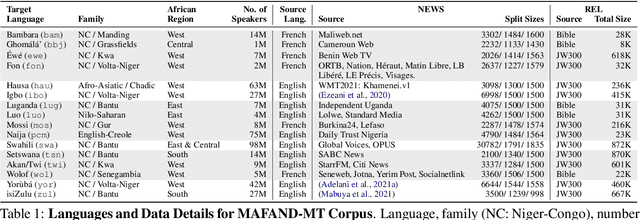
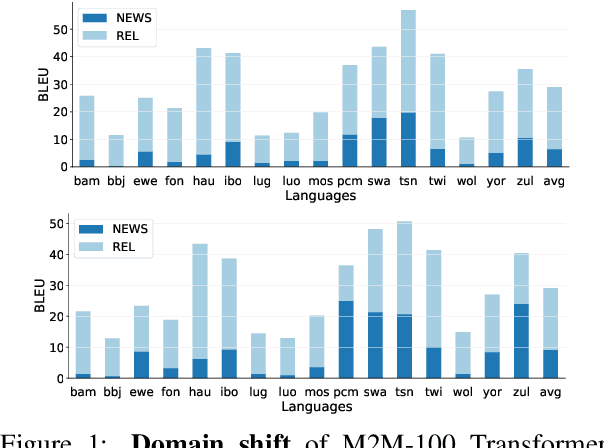

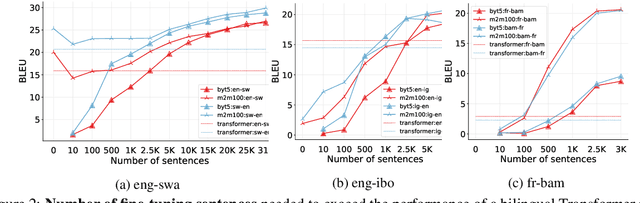
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.