 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Catalysts, Not Moral Agents: The Illusion of Alignment in LLM Societies
Feb 01, 2026The rapid evolution of Large Language Models (LLMs) has led to the emergence of Multi-Agent Systems where collective cooperation is often threatened by the "Tragedy of the Commons." This study investigates the effectiveness of Anchoring Agents--pre-programmed altruistic entities--in fostering cooperation within a Public Goods Game (PGG). Using a full factorial design across three state-of-the-art LLMs, we analyzed both behavioral outcomes and internal reasoning chains. While Anchoring Agents successfully boosted local cooperation rates, cognitive decomposition and transfer tests revealed that this effect was driven by strategic compliance and cognitive offloading rather than genuine norm internalization. Notably, most agents reverted to self-interest in new environments, and advanced models like GPT-4.1 exhibited a "Chameleon Effect," masking strategic defection under public scrutiny. These findings highlight a critical gap between behavioral modification and authentic value alignment in artificial societies.
Video Game Level Design as a Multi-Agent Reinforcement Learning Problem
Oct 06, 2025Procedural Content Generation via Reinforcement Learning (PCGRL) offers a method for training controllable level designer agents without the need for human datasets, using metrics that serve as proxies for level quality as rewards. Existing PCGRL research focuses on single generator agents, but are bottlenecked by the need to frequently recalculate heuristics of level quality and the agent's need to navigate around potentially large maps. By framing level generation as a multi-agent problem, we mitigate the efficiency bottleneck of single-agent PCGRL by reducing the number of reward calculations relative to the number of agent actions. We also find that multi-agent level generators are better able to generalize to out-of-distribution map shapes, which we argue is due to the generators' learning more local, modular design policies. We conclude that treating content generation as a distributed, multi-agent task is beneficial for generating functional artifacts at scale.
ScriptDoctor: Automatic Generation of PuzzleScript Games via Large Language Models and Tree Search
Jun 06, 2025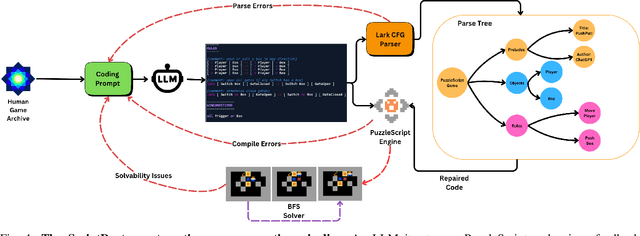


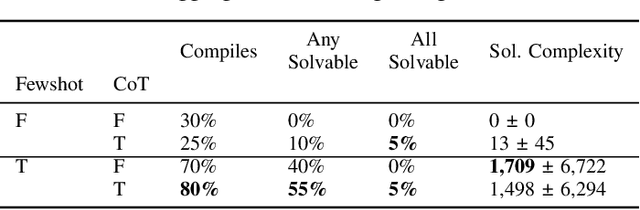
There is much interest in using large pre-trained models in Automatic Game Design (AGD), whether via the generation of code, assets, or more abstract conceptualization of design ideas. But so far this interest largely stems from the ad hoc use of such generative models under persistent human supervision. Much work remains to show how these tools can be integrated into longer-time-horizon AGD pipelines, in which systems interface with game engines to test generated content autonomously. To this end, we introduce ScriptDoctor, a Large Language Model (LLM)-driven system for automatically generating and testing games in PuzzleScript, an expressive but highly constrained description language for turn-based puzzle games over 2D gridworlds. ScriptDoctor generates and tests game design ideas in an iterative loop, where human-authored examples are used to ground the system's output, compilation errors from the PuzzleScript engine are used to elicit functional code, and search-based agents play-test generated games. ScriptDoctor serves as a concrete example of the potential of automated, open-ended LLM-based workflows in generating novel game content.
Enhancing Player Enjoyment with a Two-Tier DRL and LLM-Based Agent System for Fighting Games
Apr 10, 2025Deep reinforcement learning (DRL) has effectively enhanced gameplay experiences and game design across various game genres. However, few studies on fighting game agents have focused explicitly on enhancing player enjoyment, a critical factor for both developers and players. To address this gap and establish a practical baseline for designing enjoyability-focused agents, we propose a two-tier agent (TTA) system and conducted experiments in the classic fighting game Street Fighter II. The first tier of TTA employs a task-oriented network architecture, modularized reward functions, and hybrid training to produce diverse and skilled DRL agents. In the second tier of TTA, a Large Language Model Hyper-Agent, leveraging players' playing data and feedback, dynamically selects suitable DRL opponents. In addition, we investigate and model several key factors that affect the enjoyability of the opponent. The experiments demonstrate improvements from 64. 36% to 156. 36% in the execution of advanced skills over baseline methods. The trained agents also exhibit distinct game-playing styles. Additionally, we conducted a small-scale user study, and the overall enjoyment in the player's feedback validates the effectiveness of our TTA system.
PCGRL+: Scaling, Control and Generalization in Reinforcement Learning Level Generators
Aug 22, 2024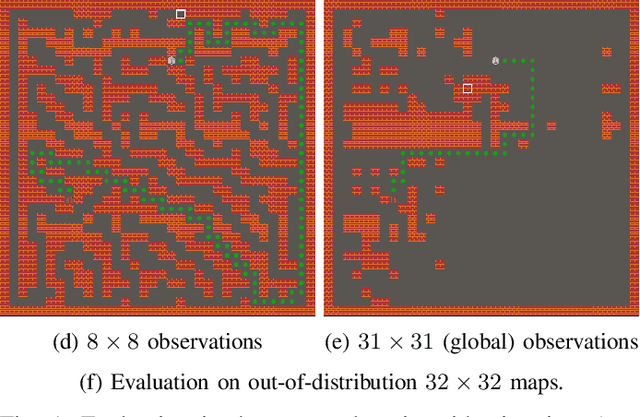



Procedural Content Generation via Reinforcement Learning (PCGRL) has been introduced as a means by which controllable designer agents can be trained based only on a set of computable metrics acting as a proxy for the level's quality and key characteristics. While PCGRL offers a unique set of affordances for game designers, it is constrained by the compute-intensive process of training RL agents, and has so far been limited to generating relatively small levels. To address this issue of scale, we implement several PCGRL environments in Jax so that all aspects of learning and simulation happen in parallel on the GPU, resulting in faster environment simulation; removing the CPU-GPU transfer of information bottleneck during RL training; and ultimately resulting in significantly improved training speed. We replicate several key results from prior works in this new framework, letting models train for much longer than previously studied, and evaluating their behavior after 1 billion timesteps. Aiming for greater control for human designers, we introduce randomized level sizes and frozen "pinpoints" of pivotal game tiles as further ways of countering overfitting. To test the generalization ability of learned generators, we evaluate models on large, out-of-distribution map sizes, and find that partial observation sizes learn more robust design strategies.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024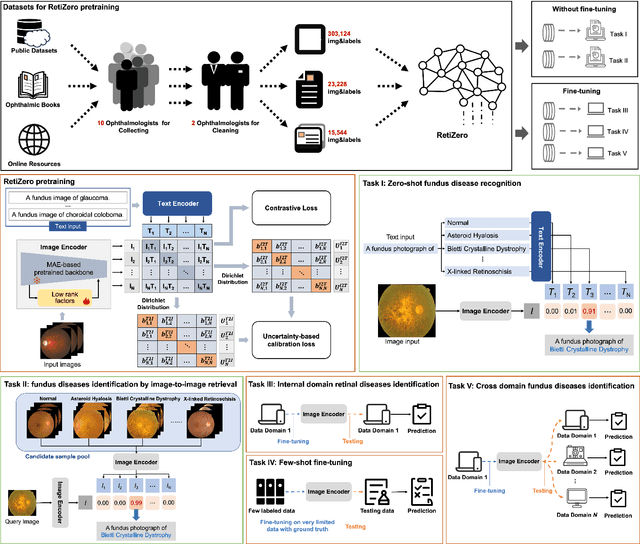
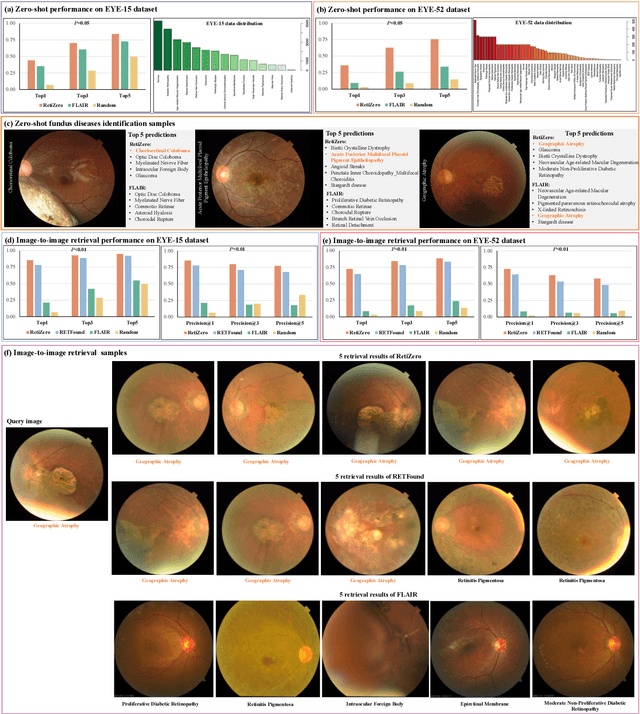
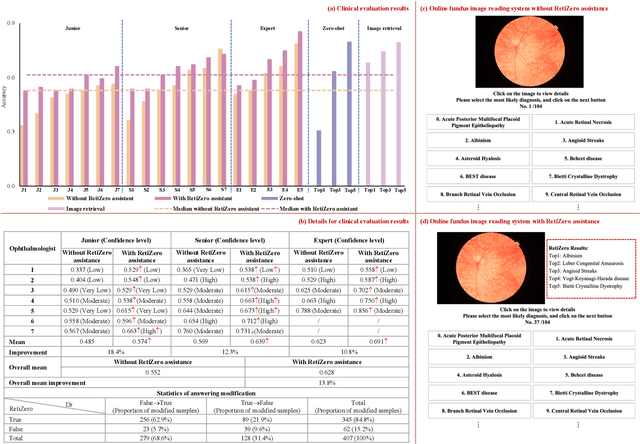
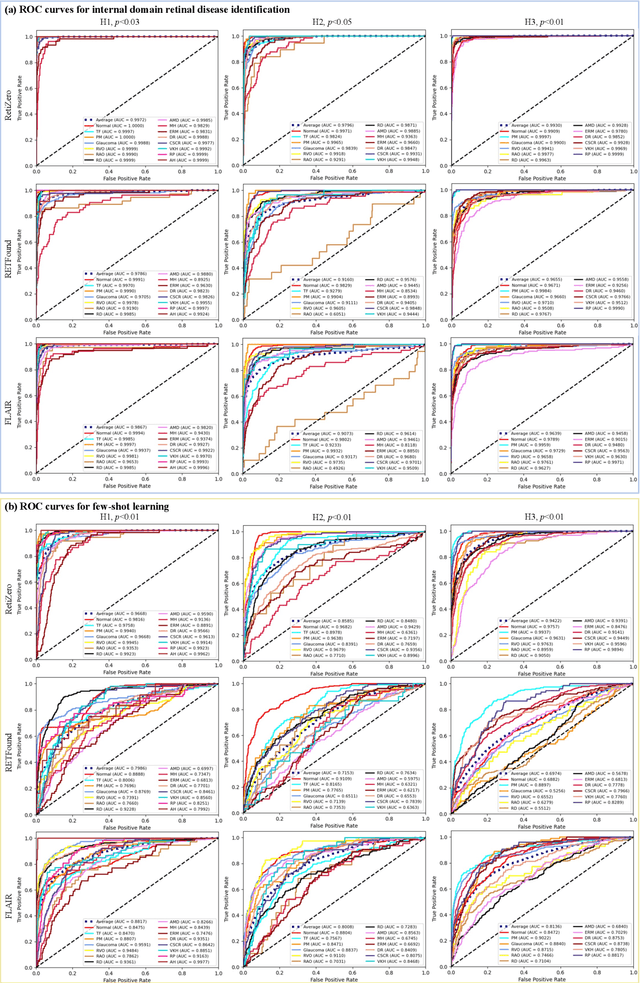
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Controllable Path of Destruction
May 31, 2023Path of Destruction (PoD) is a self-supervised method for learning iterative generators. The core idea is to produce a training set by destroying a set of artifacts, and for each destructive step create a training instance based on the corresponding repair action. A generator trained on this dataset can then generate new artifacts by repairing from arbitrary states. The PoD method is very data-efficient in terms of original training examples and well-suited to functional artifacts composed of categorical data, such as game levels and discrete 3D structures. In this paper, we extend the Path of Destruction method to allow designer control over aspects of the generated artifacts. Controllability is introduced by adding conditional inputs to the state-action pairs that make up the repair trajectories. We test the controllable PoD method in a 2D dungeon setting, as well as in the domain of small 3D Lego cars.
Diversity and Novelty MasterPrints: Generating Multiple DeepMasterPrints for Increased User Coverage
Sep 11, 2022



This work expands on previous advancements in genetic fingerprint spoofing via the DeepMasterPrints and introduces Diversity and Novelty MasterPrints. This system uses quality diversity evolutionary algorithms to generate dictionaries of artificial prints with a focus on increasing coverage of users from the dataset. The Diversity MasterPrints focus on generating solution prints that match with users not covered by previously found prints, and the Novelty MasterPrints explicitly search for prints with more that are farther in user space than previous prints. Our multi-print search methodologies outperform the singular DeepMasterPrints in both coverage and generalization while maintaining quality of the fingerprint image output.
Learning Controllable 3D Level Generators
Jul 06, 2022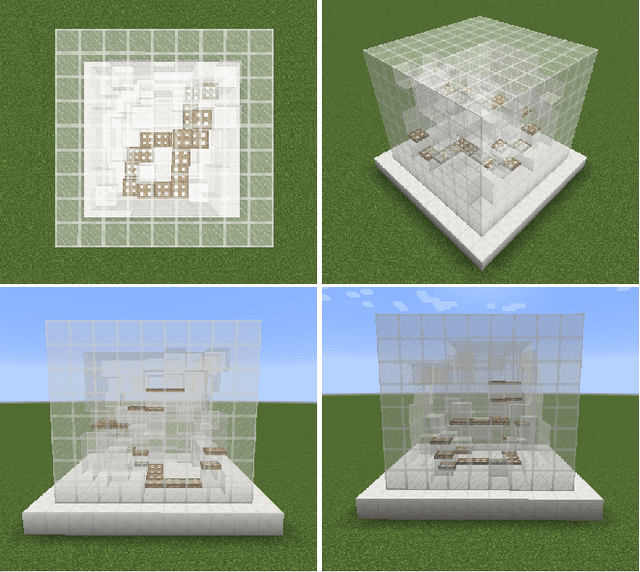

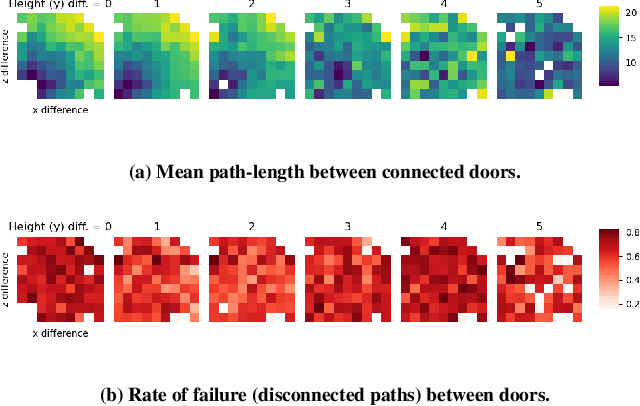

Procedural Content Generation via Reinforcement Learning (PCGRL) foregoes the need for large human-authored data-sets and allows agents to train explicitly on functional constraints, using computable, user-defined measures of quality instead of target output. We explore the application of PCGRL to 3D domains, in which content-generation tasks naturally have greater complexity and potential pertinence to real-world applications. Here, we introduce several PCGRL tasks for the 3D domain, Minecraft (Mojang Studios, 2009). These tasks will challenge RL-based generators using affordances often found in 3D environments, such as jumping, multiple dimensional movement, and gravity. We train an agent to optimize each of these tasks to explore the capabilities of previous research in PCGRL. This agent is able to generate relatively complex and diverse levels, and generalize to random initial states and control targets. Controllability tests in the presented tasks demonstrate their utility to analyze success and failure for 3D generators.