 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical analysis of PGA-MAP-Elites for Neuroevolution in Uncertain Domains
Paper and Code
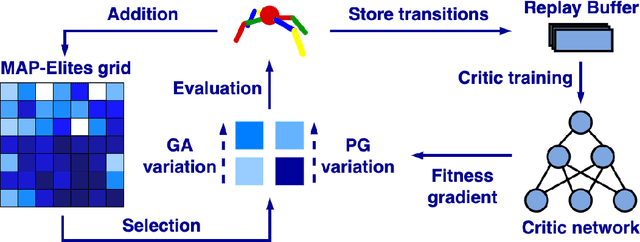
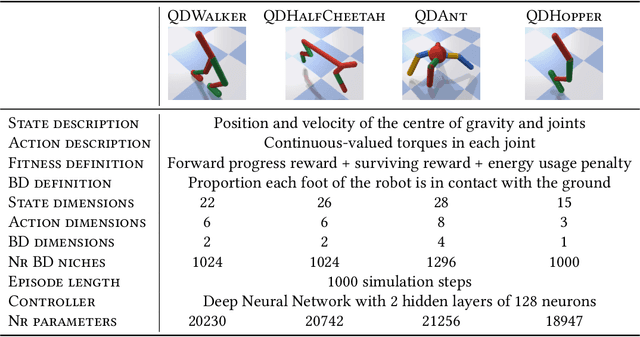

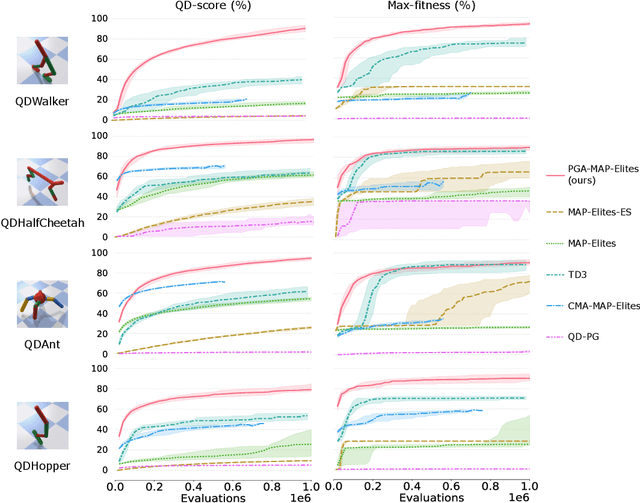
Quality-Diversity algorithms, among which MAP-Elites, have emerged as powerful alternatives to performance-only optimisation approaches as they enable generating collections of diverse and high-performing solutions to an optimisation problem. However, they are often limited to low-dimensional search spaces and deterministic environments. The recently introduced Policy Gradient Assisted MAP-Elites (PGA-MAP-Elites) algorithm overcomes this limitation by pairing the traditional Genetic operator of MAP-Elites with a gradient-based operator inspired by Deep Reinforcement Learning. This new operator guides mutations toward high-performing solutions using policy-gradients. In this work, we propose an in-depth study of PGA-MAP-Elites. We demonstrate the benefits of policy-gradients on the performance of the algorithm and the reproducibility of the generated solutions when considering uncertain domains. We first prove that PGA-MAP-Elites is highly performant in both deterministic and uncertain high-dimensional environments, decorrelating the two challenges it tackles. Secondly, we show that in addition to outperforming all the considered baselines, the collections of solutions generated by PGA-MAP-Elites are highly reproducible in uncertain environments, approaching the reproducibility of solutions found by Quality-Diversity approaches built specifically for uncertain applications. Finally, we propose an ablation and in-depth analysis of the dynamic of the policy-gradients-based variation. We demonstrate that the policy-gradient variation operator is determinant to guarantee the performance of PGA-MAP-Elites but is only essential during the early stage of the process, where it finds high-performing regions of the search space.