 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Prospective COVID-19 Therapeutic with Reinforcement Learning
Dec 03, 2020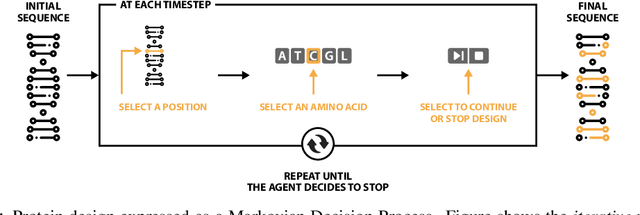
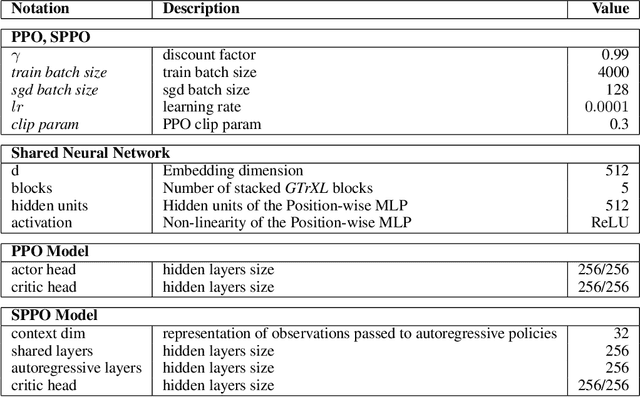
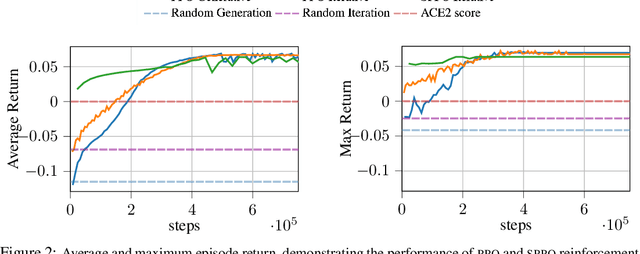
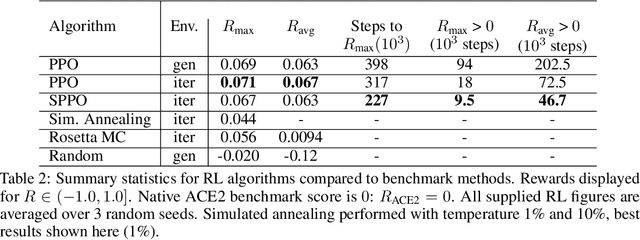
The SARS-CoV-2 pandemic has created a global race for a cure. One approach focuses on designing a novel variant of the human angiotensin-converting enzyme 2 (ACE2) that binds more tightly to the SARS-CoV-2 spike protein and diverts it from human cells. Here we formulate a novel protein design framework as a reinforcement learning problem. We generate new designs efficiently through the combination of a fast, biologically-grounded reward function and sequential action-space formulation. The use of Policy Gradients reduces the compute budget needed to reach consistent, high-quality designs by at least an order of magnitude compared to standard methods. Complexes designed by this method have been validated by molecular dynamics simulations, confirming their increased stability. This suggests that combining leading protein design methods with modern deep reinforcement learning is a viable path for discovering a Covid-19 cure and may accelerate design of peptide-based therapeutics for other diseases.
3D Deep Learning for Biological Function Prediction from Physical Fields
Apr 13, 2017
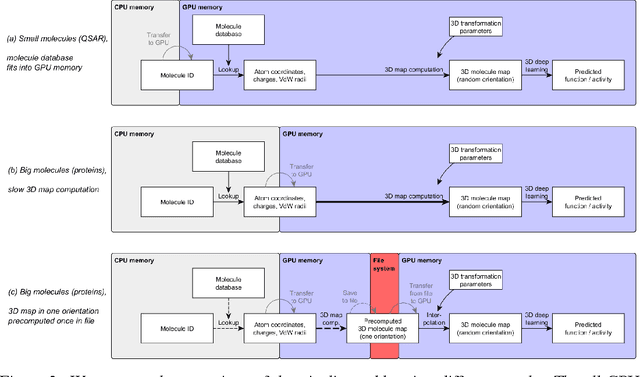
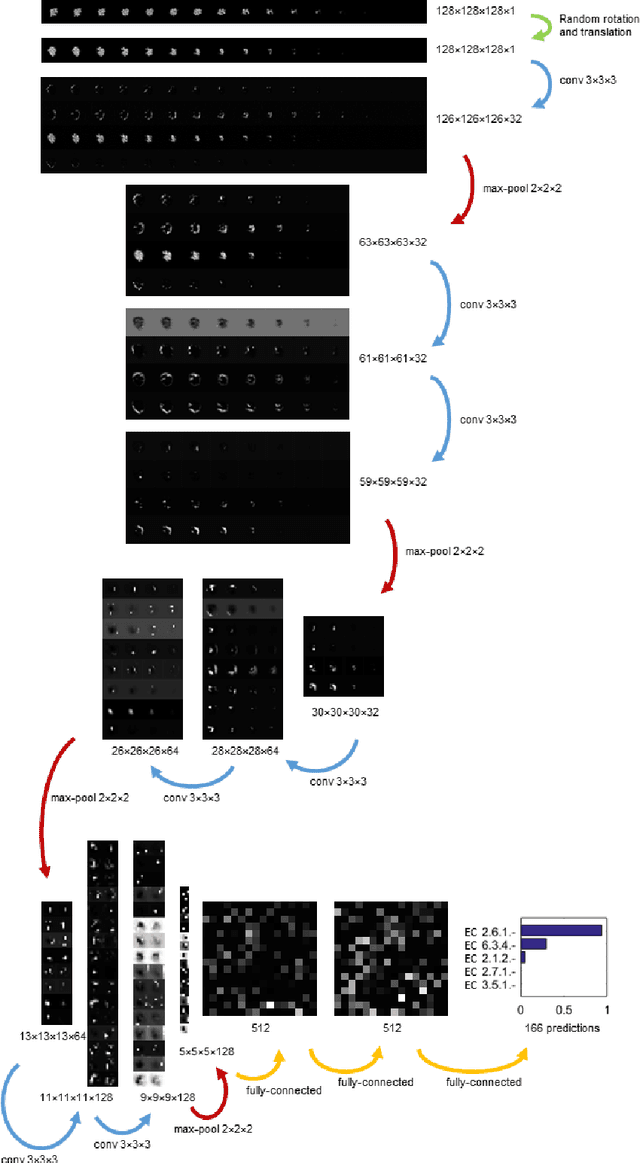
Predicting the biological function of molecules, be it proteins or drug-like compounds, from their atomic structure is an important and long-standing problem. Function is dictated by structure, since it is by spatial interactions that molecules interact with each other, both in terms of steric complementarity, as well as intermolecular forces. Thus, the electron density field and electrostatic potential field of a molecule contain the "raw fingerprint" of how this molecule can fit to binding partners. In this paper, we show that deep learning can predict biological function of molecules directly from their raw 3D approximated electron density and electrostatic potential fields. Protein function based on EC numbers is predicted from the approximated electron density field. In another experiment, the activity of small molecules is predicted with quality comparable to state-of-the-art descriptor-based methods. We propose several alternative computational models for the GPU with different memory and runtime requirements for different sizes of molecules and of databases. We also propose application-specific multi-channel data representations. With future improvements of training datasets and neural network settings in combination with complementary information sources (sequence, genomic context, expression level), deep learning can be expected to show its generalization power and revolutionize the field of molecular function prediction.