 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunBERT: Pretrained Contextualized Text Representation for Tunisian Dialect
Nov 25, 2021

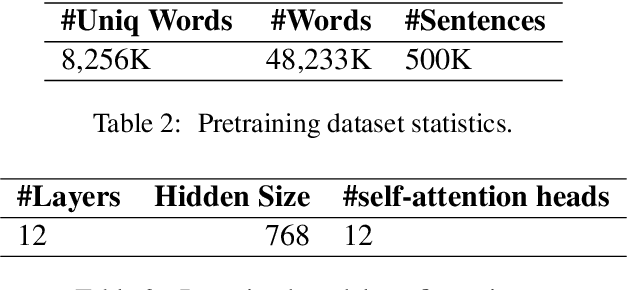
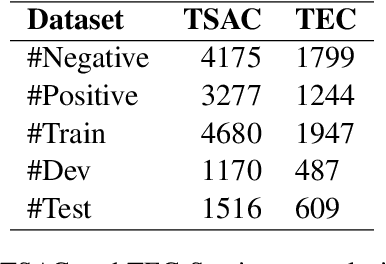
Pretrained contextualized text representation models learn an effective representation of a natural language to make it machine understandable. After the breakthrough of the attention mechanism, a new generation of pretrained models have been proposed achieving good performances since the introduction of the Transformer. Bidirectional Encoder Representations from Transformers (BERT) has become the state-of-the-art model for language understanding. Despite their success, most of the available models have been trained on Indo-European languages however similar research for under-represented languages and dialects remains sparse. In this paper, we investigate the feasibility of training monolingual Transformer-based language models for under represented languages, with a specific focus on the Tunisian dialect. We evaluate our language model on sentiment analysis task, dialect identification task and reading comprehension question-answering task. We show that the use of noisy web crawled data instead of structured data (Wikipedia, articles, etc.) is more convenient for such non-standardized language. Moreover, results indicate that a relatively small web crawled dataset leads to performances that are as good as those obtained using larger datasets. Finally, our best performing TunBERT model reaches or improves the state-of-the-art in all three downstream tasks. We release the TunBERT pretrained model and the datasets used for fine-tuning.
Designing a Prospective COVID-19 Therapeutic with Reinforcement Learning
Dec 03, 2020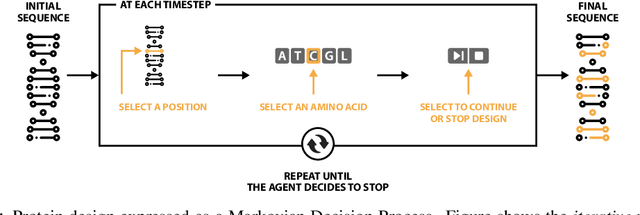
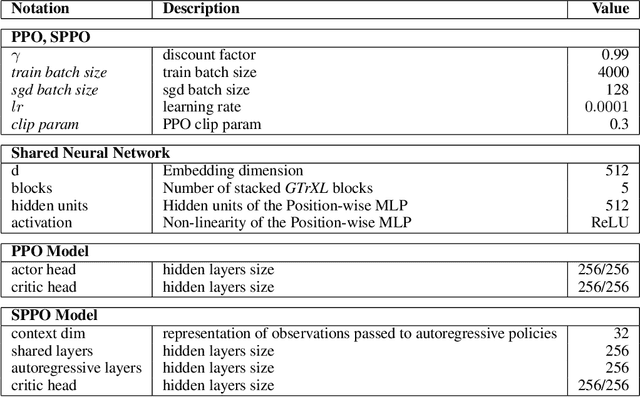
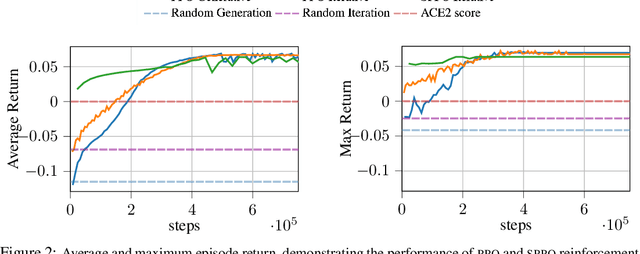
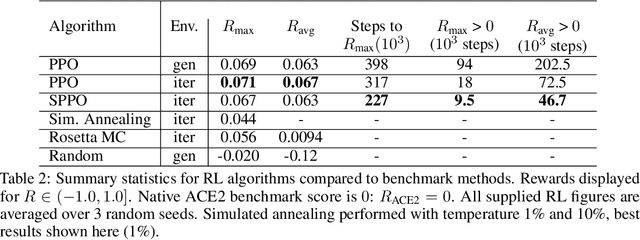
The SARS-CoV-2 pandemic has created a global race for a cure. One approach focuses on designing a novel variant of the human angiotensin-converting enzyme 2 (ACE2) that binds more tightly to the SARS-CoV-2 spike protein and diverts it from human cells. Here we formulate a novel protein design framework as a reinforcement learning problem. We generate new designs efficiently through the combination of a fast, biologically-grounded reward function and sequential action-space formulation. The use of Policy Gradients reduces the compute budget needed to reach consistent, high-quality designs by at least an order of magnitude compared to standard methods. Complexes designed by this method have been validated by molecular dynamics simulations, confirming their increased stability. This suggests that combining leading protein design methods with modern deep reinforcement learning is a viable path for discovering a Covid-19 cure and may accelerate design of peptide-based therapeutics for other diseases.
Ranked Reward: Enabling Self-Play Reinforcement Learning for Combinatorial Optimization
Jul 06, 2018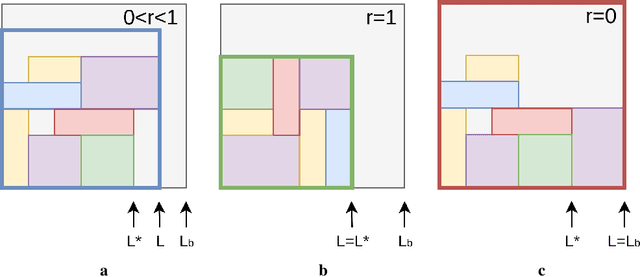
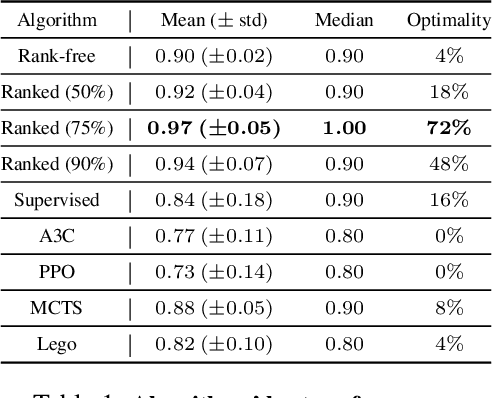
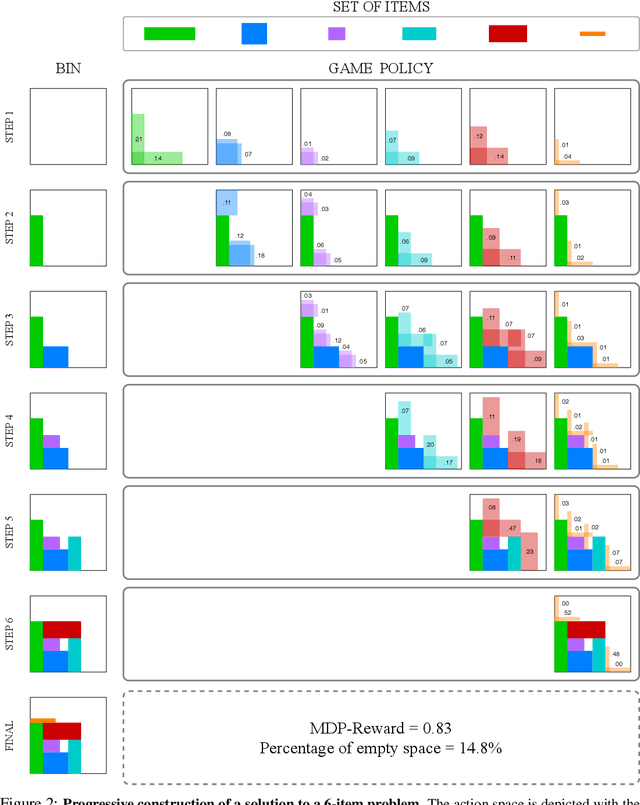
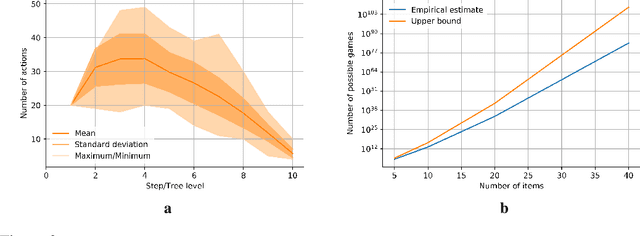
Adversarial self-play in two-player games has delivered impressive results when used with reinforcement learning algorithms that combine deep neural networks and tree search. Algorithms like AlphaZero and Expert Iteration learn tabula-rasa, producing highly informative training data on the fly. However, the self-play training strategy is not directly applicable to single-player games. Recently, several practically important combinatorial optimization problems, such as the traveling salesman problem and the bin packing problem, have been reformulated as reinforcement learning problems, increasing the importance of enabling the benefits of self-play beyond two-player games. We present the Ranked Reward (R2) algorithm which accomplishes this by ranking the rewards obtained by a single agent over multiple games to create a relative performance metric. Results from applying the R2 algorithm to instances of a two-dimensional bin packing problem show that it outperforms generic Monte Carlo tree search, heuristic algorithms and reinforcement learning algorithms not using ranked rewards.