 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunBERT: Pretrained Contextualized Text Representation for Tunisian Dialect
Nov 25, 2021

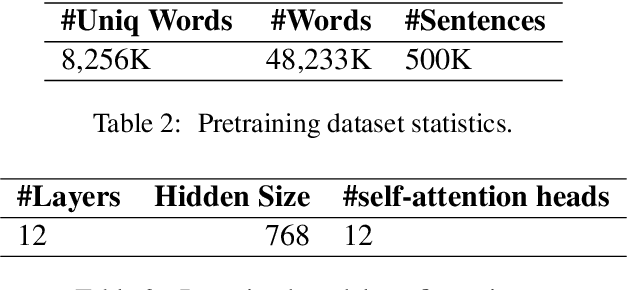
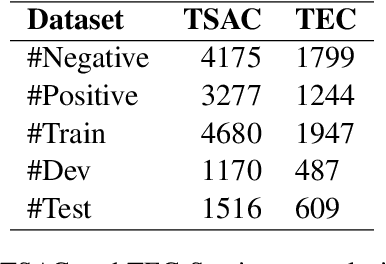
Pretrained contextualized text representation models learn an effective representation of a natural language to make it machine understandable. After the breakthrough of the attention mechanism, a new generation of pretrained models have been proposed achieving good performances since the introduction of the Transformer. Bidirectional Encoder Representations from Transformers (BERT) has become the state-of-the-art model for language understanding. Despite their success, most of the available models have been trained on Indo-European languages however similar research for under-represented languages and dialects remains sparse. In this paper, we investigate the feasibility of training monolingual Transformer-based language models for under represented languages, with a specific focus on the Tunisian dialect. We evaluate our language model on sentiment analysis task, dialect identification task and reading comprehension question-answering task. We show that the use of noisy web crawled data instead of structured data (Wikipedia, articles, etc.) is more convenient for such non-standardized language. Moreover, results indicate that a relatively small web crawled dataset leads to performances that are as good as those obtained using larger datasets. Finally, our best performing TunBERT model reaches or improves the state-of-the-art in all three downstream tasks. We release the TunBERT pretrained model and the datasets used for fine-tuning.
AI4D -- African Language Program
Apr 06, 2021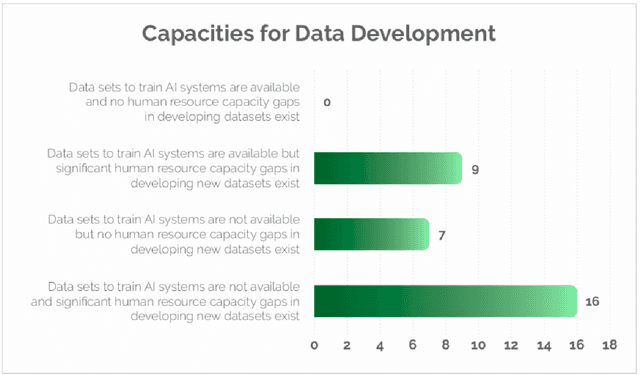
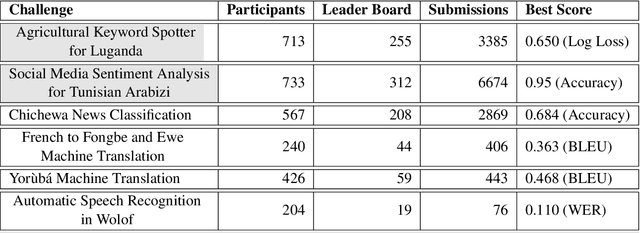
Advances in speech and language technologies enable tools such as voice-search, text-to-speech, speech recognition and machine translation. These are however only available for high resource languages like English, French or Chinese. Without foundational digital resources for African languages, which are considered low-resource in the digital context, these advanced tools remain out of reach. This work details the AI4D - African Language Program, a 3-part project that 1) incentivised the crowd-sourcing, collection and curation of language datasets through an online quantitative and qualitative challenge, 2) supported research fellows for a period of 3-4 months to create datasets annotated for NLP tasks, and 3) hosted competitive Machine Learning challenges on the basis of these datasets. Key outcomes of the work so far include 1) the creation of 9+ open source, African language datasets annotated for a variety of ML tasks, and 2) the creation of baseline models for these datasets through hosting of competitive ML challenges.