 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunBERT: Pretrained Contextualized Text Representation for Tunisian Dialect
Nov 25, 2021

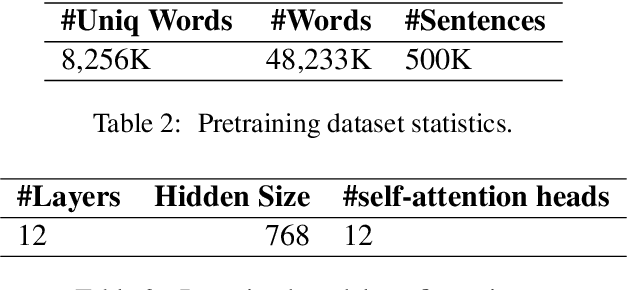
Pretrained contextualized text representation models learn an effective representation of a natural language to make it machine understandable. After the breakthrough of the attention mechanism, a new generation of pretrained models have been proposed achieving good performances since the introduction of the Transformer. Bidirectional Encoder Representations from Transformers (BERT) has become the state-of-the-art model for language understanding. Despite their success, most of the available models have been trained on Indo-European languages however similar research for under-represented languages and dialects remains sparse. In this paper, we investigate the feasibility of training monolingual Transformer-based language models for under represented languages, with a specific focus on the Tunisian dialect. We evaluate our language model on sentiment analysis task, dialect identification task and reading comprehension question-answering task. We show that the use of noisy web crawled data instead of structured data (Wikipedia, articles, etc.) is more convenient for such non-standardized language. Moreover, results indicate that a relatively small web crawled dataset leads to performances that are as good as those obtained using larger datasets. Finally, our best performing TunBERT model reaches or improves the state-of-the-art in all three downstream tasks. We release the TunBERT pretrained model and the datasets used for fine-tuning.
TEET! Tunisian Dataset for Toxic Speech Detection
Oct 11, 2021
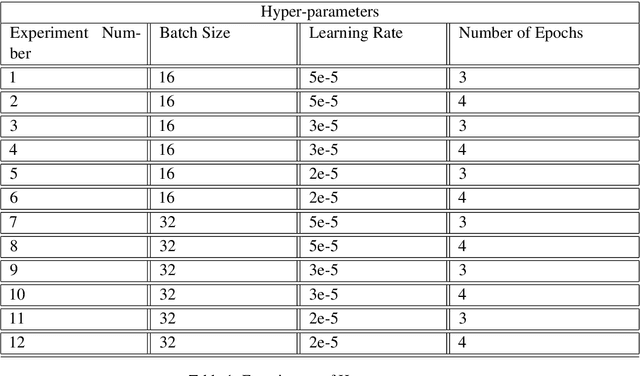
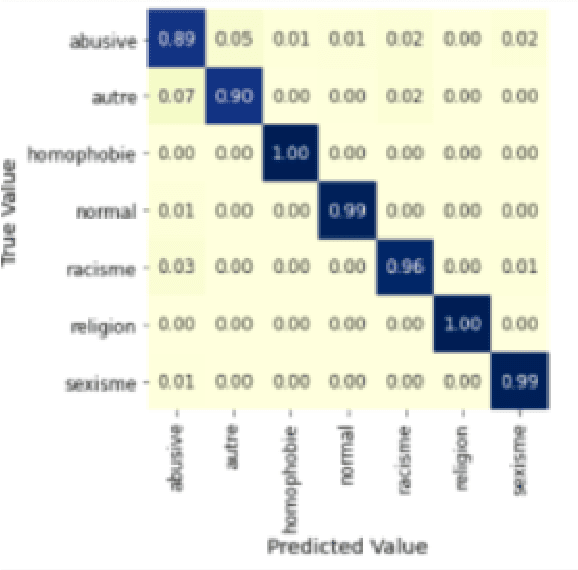
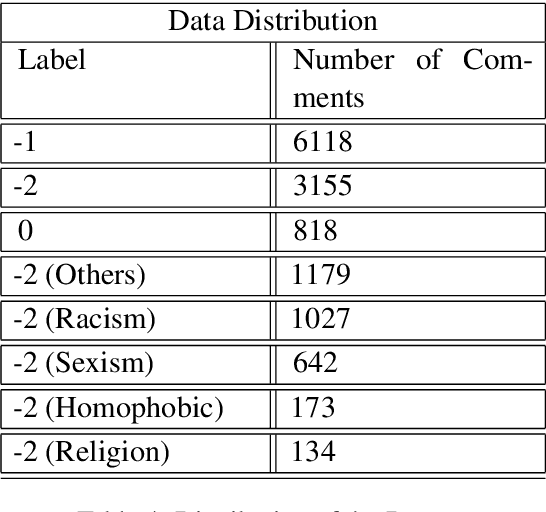
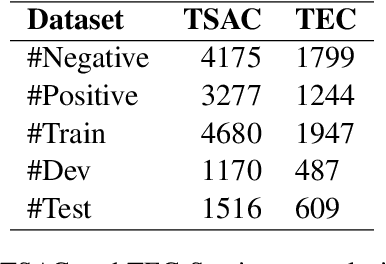
The complete freedom of expression in social media has its costs especially in spreading harmful and abusive content that may induce people to act accordingly. Therefore, the need of detecting automatically such a content becomes an urgent task that will help and enhance the efficiency in limiting this toxic spread. Compared to other Arabic dialects which are mostly based on MSA, the Tunisian dialect is a combination of many other languages like MSA, Tamazight, Italian and French. Because of its rich language, dealing with NLP problems can be challenging due to the lack of large annotated datasets. In this paper we are introducing a new annotated dataset composed of approximately 10k of comments. We provide an in-depth exploration of its vocabulary through feature engineering approaches as well as the results of the classification performance of machine learning classifiers like NB and SVM and deep learning models such as ARBERT, MARBERT and XLM-R.
Bambara Language Dataset for Sentiment Analysis
Aug 05, 2021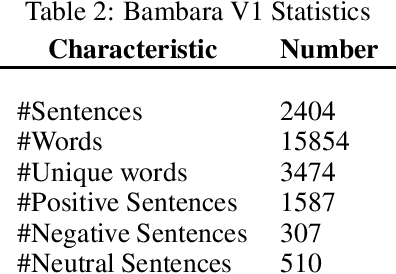
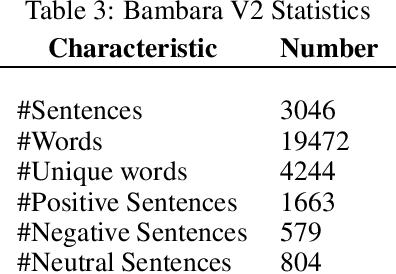
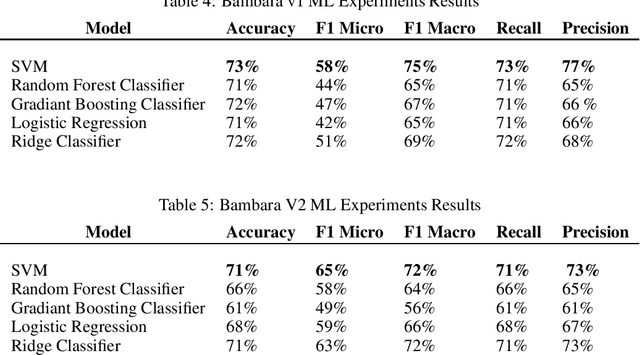

For easier communication, posting, or commenting on each others posts, people use their dialects. In Africa, various languages and dialects exist. However, they are still underrepresented and not fully exploited for analytical studies and research purposes. In order to perform approaches like Machine Learning and Deep Learning, datasets are required. One of the African languages is Bambara, used by citizens in different countries. However, no previous work on datasets for this language was performed for Sentiment Analysis. In this paper, we present the first common-crawl-based Bambara dialectal dataset dedicated for Sentiment Analysis, available freely for Natural Language Processing research purposes.
AI4D -- African Language Program
Apr 06, 2021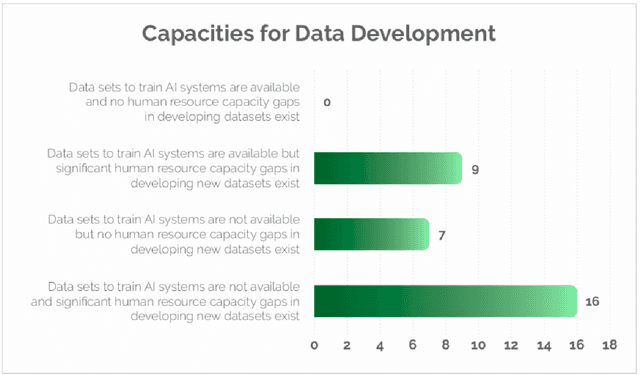
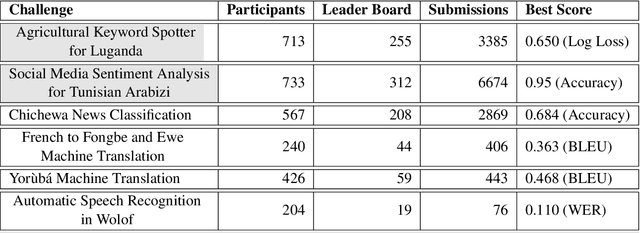
Advances in speech and language technologies enable tools such as voice-search, text-to-speech, speech recognition and machine translation. These are however only available for high resource languages like English, French or Chinese. Without foundational digital resources for African languages, which are considered low-resource in the digital context, these advanced tools remain out of reach. This work details the AI4D - African Language Program, a 3-part project that 1) incentivised the crowd-sourcing, collection and curation of language datasets through an online quantitative and qualitative challenge, 2) supported research fellows for a period of 3-4 months to create datasets annotated for NLP tasks, and 3) hosted competitive Machine Learning challenges on the basis of these datasets. Key outcomes of the work so far include 1) the creation of 9+ open source, African language datasets annotated for a variety of ML tasks, and 2) the creation of baseline models for these datasets through hosting of competitive ML challenges.
A Multilingual African Embedding for FAQ Chatbots
Mar 16, 2021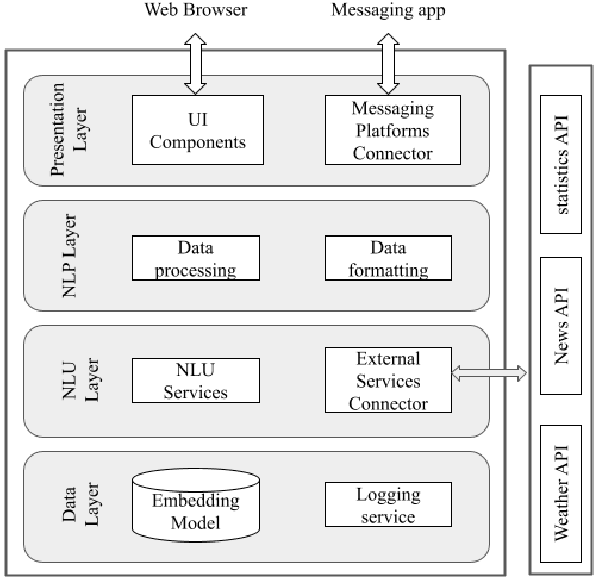
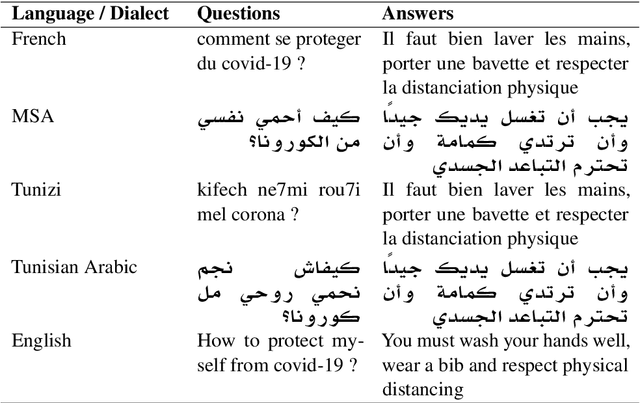

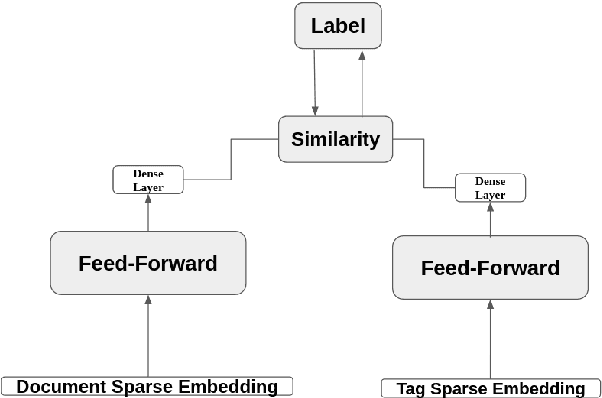
Searching for an available, reliable, official, and understandable information is not a trivial task due to scattered information across the internet, and the availability lack of governmental communication channels communicating with African dialects and languages. In this paper, we introduce an Artificial Intelligence Powered chatbot for crisis communication that would be omnichannel, multilingual and multi dialectal. We present our work on modified StarSpace embedding tailored for African dialects for the question-answering task along with the architecture of the proposed chatbot system and a description of the different layers. English, French, Arabic, Tunisian, Igbo,Yor\`ub\'a, and Hausa are used as languages and dialects. Quantitative and qualitative evaluation results are obtained for our real deployed Covid-19 chatbot. Results show that users are satisfied and the conversation with the chatbot is meeting customer needs.
Learning Word Representations for Tunisian Sentiment Analysis
Oct 14, 2020
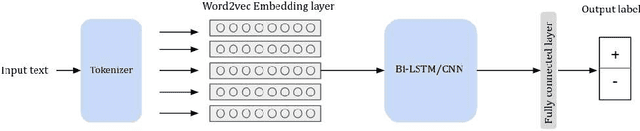
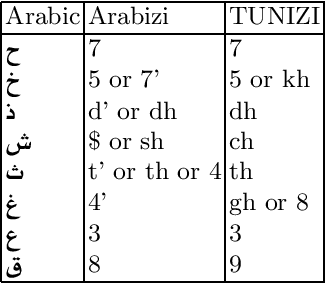
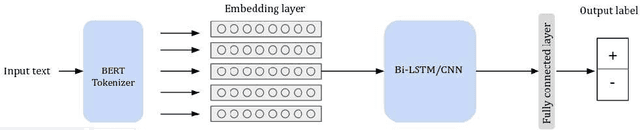
Tunisians on social media tend to express themselves in their local dialect using Latin script (TUNIZI). This raises an additional challenge to the process of exploring and recognizing online opinions. To date, very little work has addressed TUNIZI sentiment analysis due to scarce resources for training an automated system. In this paper, we focus on the Tunisian dialect sentiment analysis used on social media. Most of the previous work used machine learning techniques combined with handcrafted features. More recently, Deep Neural Networks were widely used for this task, especially for the English language. In this paper, we explore the importance of various unsupervised word representations (word2vec, BERT) and we investigate the use of Convolutional Neural Networks and Bidirectional Long Short-Term Memory. Without using any kind of handcrafted features, our experimental results on two publicly available datasets showed comparable performances to other languages.
TUNIZI: a Tunisian Arabizi sentiment analysis Dataset
Apr 29, 2020
On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called "Tunisian Arabizi". Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers.
Empirical Evaluation of Leveraging Named Entities for Arabic Sentiment Analysis
Apr 23, 2019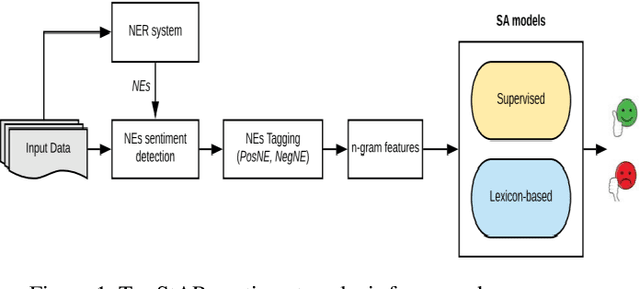
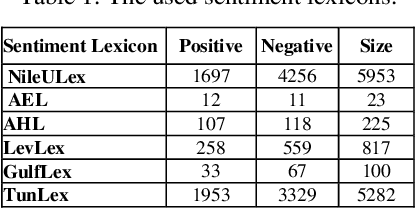
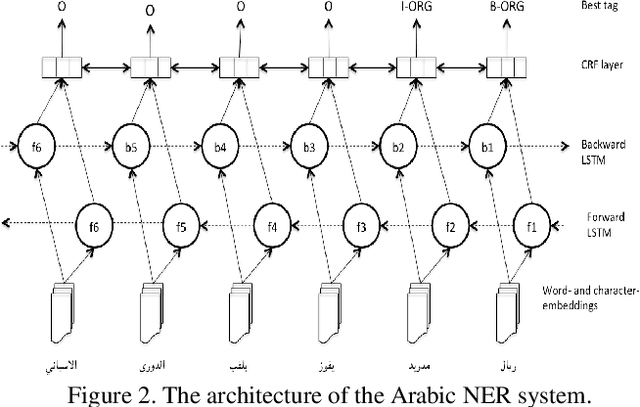
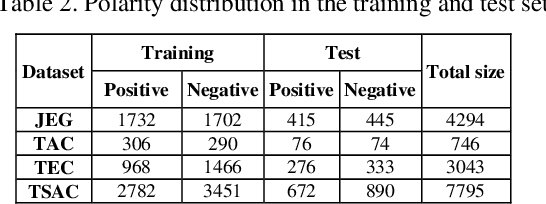
Social media reflects the public attitudes towards specific events. Events are often related to persons, locations or organizations, the so-called Named Entities. This can define Named Entities as sentiment-bearing components. In this paper, we dive beyond Named Entities recognition to the exploitation of sentiment-annotated Named Entities in Arabic sentiment analysis. Therefore, we develop an algorithm to detect the sentiment of Named Entities based on the majority of attitudes towards them. This enabled tagging Named Entities with proper tags and, thus, including them in a sentiment analysis framework of two models: supervised and lexicon-based. Both models were applied on datasets of multi-dialectal content. The results revealed that Named Entities have no considerable impact on the supervised model, while employing them in the lexicon-based model improved the classification performance and outperformed most of the baseline systems.