 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunBERT: Pretrained Contextualized Text Representation for Tunisian Dialect
Nov 25, 2021

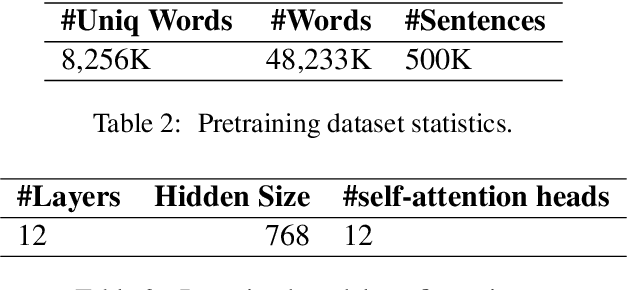
Pretrained contextualized text representation models learn an effective representation of a natural language to make it machine understandable. After the breakthrough of the attention mechanism, a new generation of pretrained models have been proposed achieving good performances since the introduction of the Transformer. Bidirectional Encoder Representations from Transformers (BERT) has become the state-of-the-art model for language understanding. Despite their success, most of the available models have been trained on Indo-European languages however similar research for under-represented languages and dialects remains sparse. In this paper, we investigate the feasibility of training monolingual Transformer-based language models for under represented languages, with a specific focus on the Tunisian dialect. We evaluate our language model on sentiment analysis task, dialect identification task and reading comprehension question-answering task. We show that the use of noisy web crawled data instead of structured data (Wikipedia, articles, etc.) is more convenient for such non-standardized language. Moreover, results indicate that a relatively small web crawled dataset leads to performances that are as good as those obtained using larger datasets. Finally, our best performing TunBERT model reaches or improves the state-of-the-art in all three downstream tasks. We release the TunBERT pretrained model and the datasets used for fine-tuning.
A Multilingual African Embedding for FAQ Chatbots
Mar 16, 2021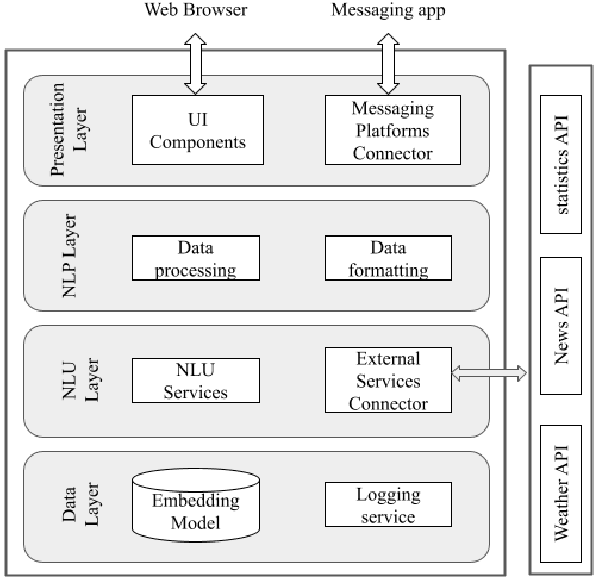
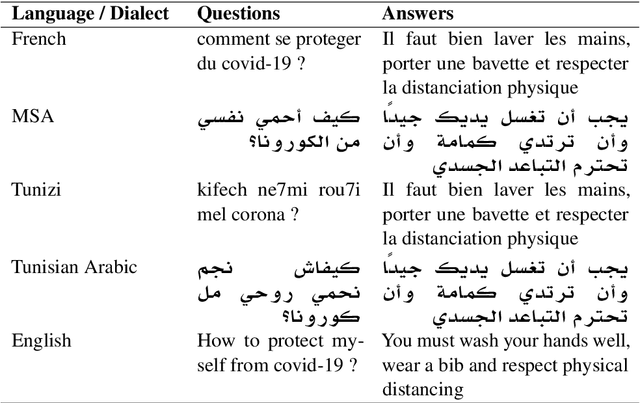

Searching for an available, reliable, official, and understandable information is not a trivial task due to scattered information across the internet, and the availability lack of governmental communication channels communicating with African dialects and languages. In this paper, we introduce an Artificial Intelligence Powered chatbot for crisis communication that would be omnichannel, multilingual and multi dialectal. We present our work on modified StarSpace embedding tailored for African dialects for the question-answering task along with the architecture of the proposed chatbot system and a description of the different layers. English, French, Arabic, Tunisian, Igbo,Yor\`ub\'a, and Hausa are used as languages and dialects. Quantitative and qualitative evaluation results are obtained for our real deployed Covid-19 chatbot. Results show that users are satisfied and the conversation with the chatbot is meeting customer needs.
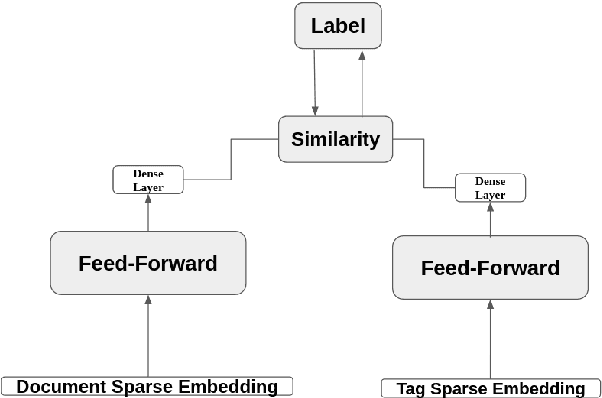
Learning Word Representations for Tunisian Sentiment Analysis
Oct 14, 2020
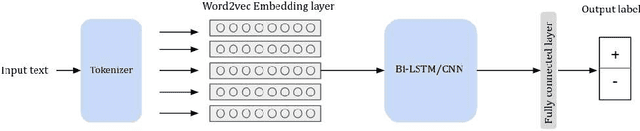
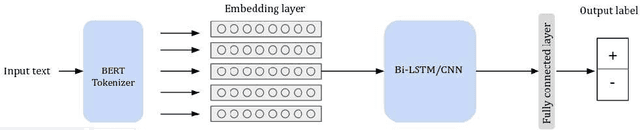
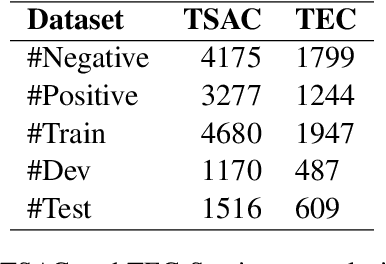
Tunisians on social media tend to express themselves in their local dialect using Latin script (TUNIZI). This raises an additional challenge to the process of exploring and recognizing online opinions. To date, very little work has addressed TUNIZI sentiment analysis due to scarce resources for training an automated system. In this paper, we focus on the Tunisian dialect sentiment analysis used on social media. Most of the previous work used machine learning techniques combined with handcrafted features. More recently, Deep Neural Networks were widely used for this task, especially for the English language. In this paper, we explore the importance of various unsupervised word representations (word2vec, BERT) and we investigate the use of Convolutional Neural Networks and Bidirectional Long Short-Term Memory. Without using any kind of handcrafted features, our experimental results on two publicly available datasets showed comparable performances to other languages.
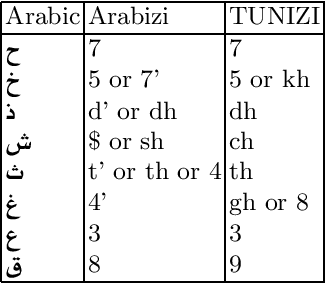
TUNIZI: a Tunisian Arabizi sentiment analysis Dataset
Apr 29, 2020
On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called "Tunisian Arabizi". Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers.
Detecting Local Community Structures in Social Networks Using Concept Interestingness
Feb 05, 2019

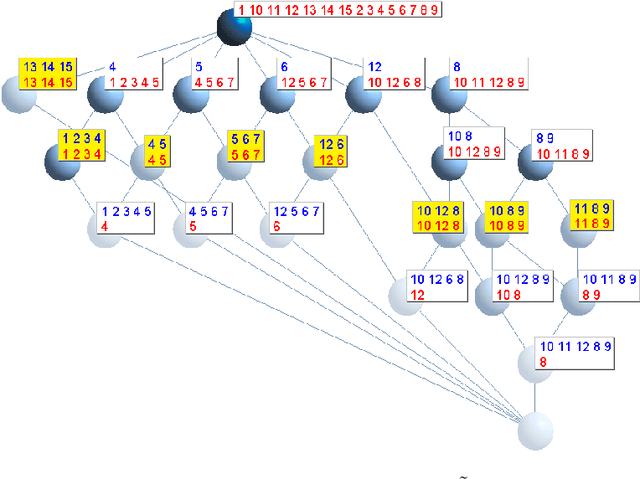
One key challenge in Social Network Analysis is to design an efficient and accurate community detection procedure as a means to discover intrinsic structures and extract relevant information. In this paper, we introduce a novel strategy called (COIN), which exploits COncept INterestingness measures to detect communities based on the concept lattice construction of the network. Thus, unlike off-the-shelf community detection algorithms, COIN leverages relevant conceptual characteristics inherited from Formal Concept Analysis to discover substantial local structures. On the first stage of COIN, we extract the formal concepts that capture all the cliques and bridges in the social network. On the second stage, we use the stability index to remove noisy bridges between communities and then percolate relevant adjacent cliques. Our experiments on several real-world social networks show that COIN can quickly detect communities more accurately than existing prominent algorithms such as Edge betweenness, Fast greedy modularity, and Infomap.
Indexing Medical Images based on Collaborative Experts Reports
Jul 05, 2013
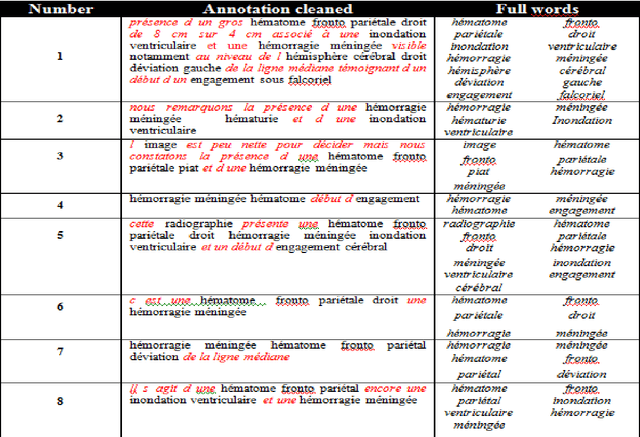

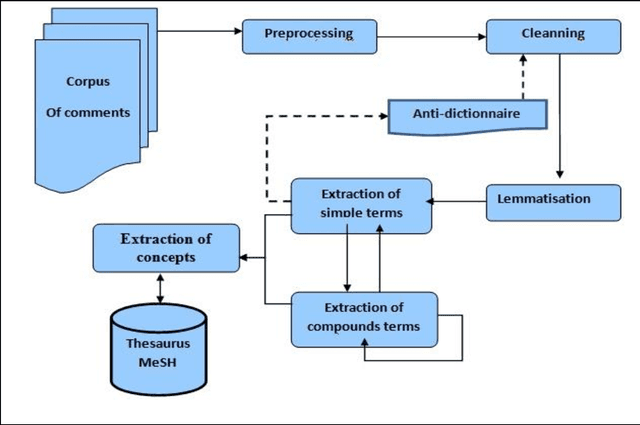
A patient is often willing to quickly get, from his physician, reliable analysis and concise explanation according to provided linked medical images. The fact of making choices individually by the patient's physician may lead to malpractices and consequently generates unforeseeable damages. The Institute of Medicine of the National Sciences Academy(IMNAS) in USA published a study estimating that up to 98,000 hospital deathseach year can be attributed to medical malpractice [1]. Moreover, physician, in charge of medical image analysis, might be unavailable at the right time, which may complicate the patient's state. The goal of this paper is to provide to physicians and patients, a social network that permits to foster cooperation and to overcome the problem of unavailability of doctors on site any time. Therefore, patients can submit their medical images to be diagnosed and commented by several experts instantly. Consequently, the need to process opinions and to extract information automatically from the proposed social network became a necessity due to the huge number of comments expressing specialist's reviews. For this reason, we propose a kind of comments' summary keywords-based method which extracts the major current terms and relevant words existing on physicians' annotations. The extracted keywords will present a new and robust method for image indexation. In fact, significant extracted terms will be used later to index images in order to facilitate their discovery for any appropriate use. To overcome this challenge, we propose our Terminology Extraction of Annotation (TEA) mixed approach which focuses on algorithms mainly based on statistical methods and on external semantic resources.
Using a bag of Words for Automatic Medical Image Annotation with a Latent Semantic
Jun 04, 2013
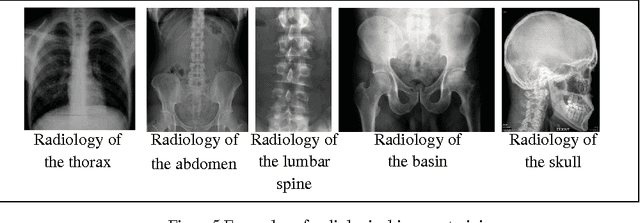
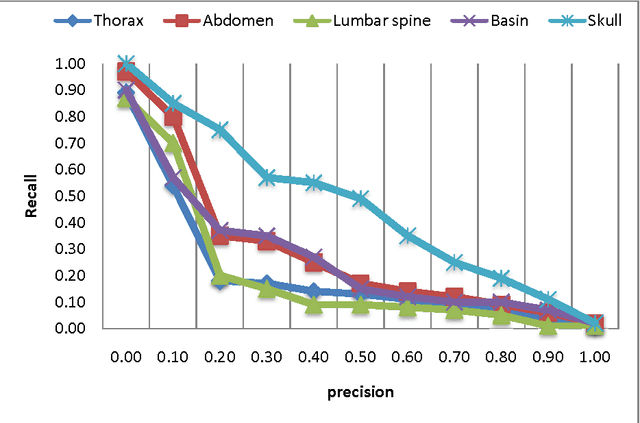
We present in this paper a new approach for the automatic annotation of medical images, using the approach of "bag-of-words" to represent the visual content of the medical image combined with text descriptors based approach tf.idf and reduced by latent semantic to extract the co-occurrence between terms and visual terms. A medical report is composed of a text describing a medical image. First, we are interested to index the text and extract all relevant terms using a thesaurus containing MeSH medical concepts. In a second phase, the medical image is indexed while recovering areas of interest which are invariant to change in scale, light and tilt. To annotate a new medical image, we use the approach of "bagof-words" to recover the feature vector. Indeed, we use the vector space model to retrieve similar medical image from the database training. The calculation of the relevance value of an image to the query image is based on the cosine function. We conclude with an experiment carried out on five types of radiological imaging to evaluate the performance of our system of medical annotation. The results showed that our approach works better with more images from the radiology of the skull.
* 10 pages, 6 figures