 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndexing Medical Images based on Collaborative Experts Reports
Jul 05, 2013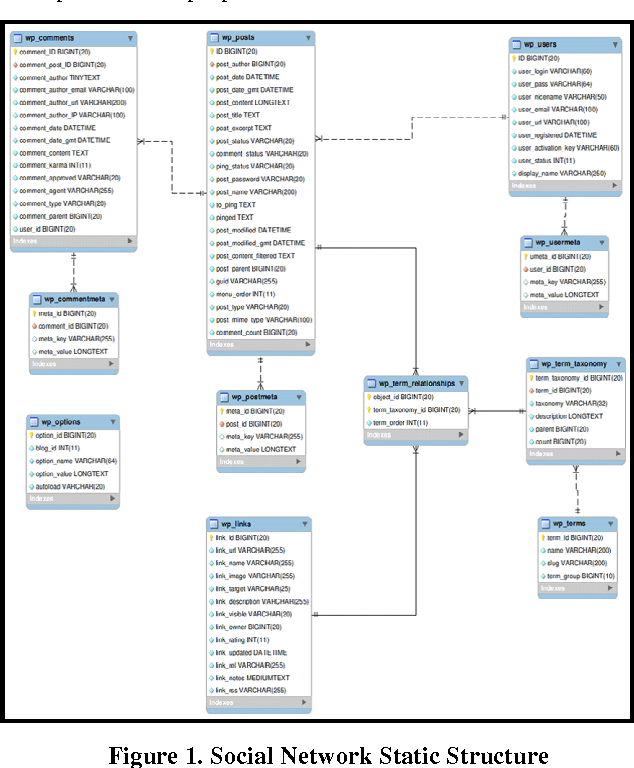
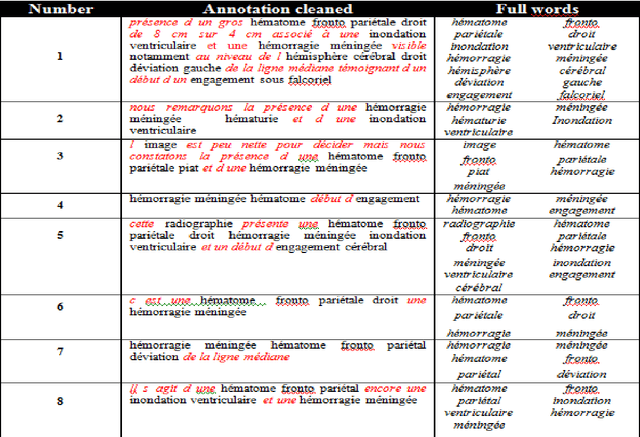

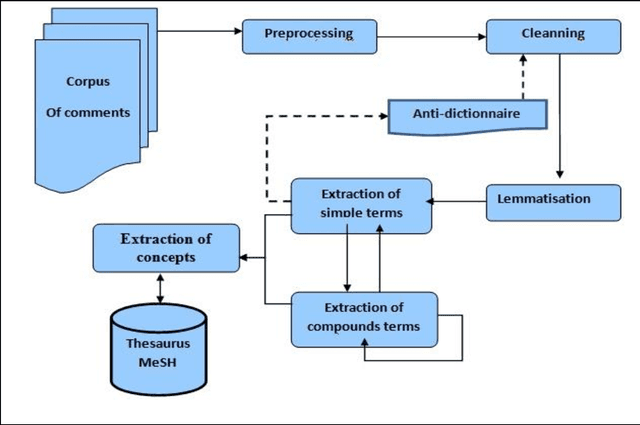
A patient is often willing to quickly get, from his physician, reliable analysis and concise explanation according to provided linked medical images. The fact of making choices individually by the patient's physician may lead to malpractices and consequently generates unforeseeable damages. The Institute of Medicine of the National Sciences Academy(IMNAS) in USA published a study estimating that up to 98,000 hospital deathseach year can be attributed to medical malpractice [1]. Moreover, physician, in charge of medical image analysis, might be unavailable at the right time, which may complicate the patient's state. The goal of this paper is to provide to physicians and patients, a social network that permits to foster cooperation and to overcome the problem of unavailability of doctors on site any time. Therefore, patients can submit their medical images to be diagnosed and commented by several experts instantly. Consequently, the need to process opinions and to extract information automatically from the proposed social network became a necessity due to the huge number of comments expressing specialist's reviews. For this reason, we propose a kind of comments' summary keywords-based method which extracts the major current terms and relevant words existing on physicians' annotations. The extracted keywords will present a new and robust method for image indexation. In fact, significant extracted terms will be used later to index images in order to facilitate their discovery for any appropriate use. To overcome this challenge, we propose our Terminology Extraction of Annotation (TEA) mixed approach which focuses on algorithms mainly based on statistical methods and on external semantic resources.
Extending UML for Conceptual Modeling of Annotation of Medical Images
Jul 03, 2013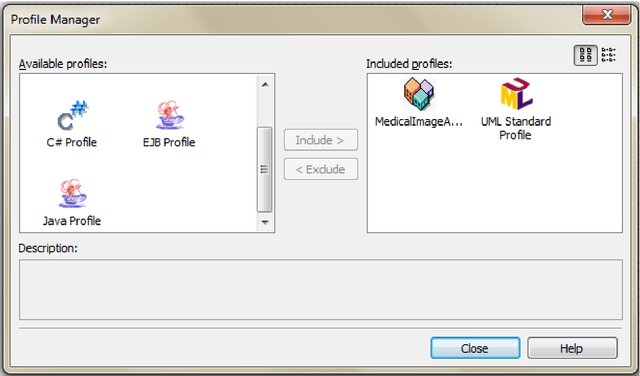
Imaging has occupied a huge role in the management of patients, whether hospitalized or not. Depending on the patients clinical problem, a variety of imaging modalities were available for use. This gave birth of the annotation of medical image process. The annotation is intended to image analysis and solve the problem of semantic gap. The reason for image annotation is due to increase in acquisition of images. Physicians and radiologists feel better while using annotation techniques for faster remedy in surgery and medicine due to the following reasons: giving details to the patients, searching the present and past records from the larger databases, and giving solutions to them in a faster and more accurate way. However, classical conceptual modeling does not incorporate the specificity of medical domain specially the annotation of medical image. The design phase is the most important activity in the successful building of annotation process. For this reason, we focus in this paper on presenting the conceptual modeling of the annotation of medical image by defining a new profile using the StarUML extensibility mechanism.
Fault detection system for Arabic language
Jun 04, 2013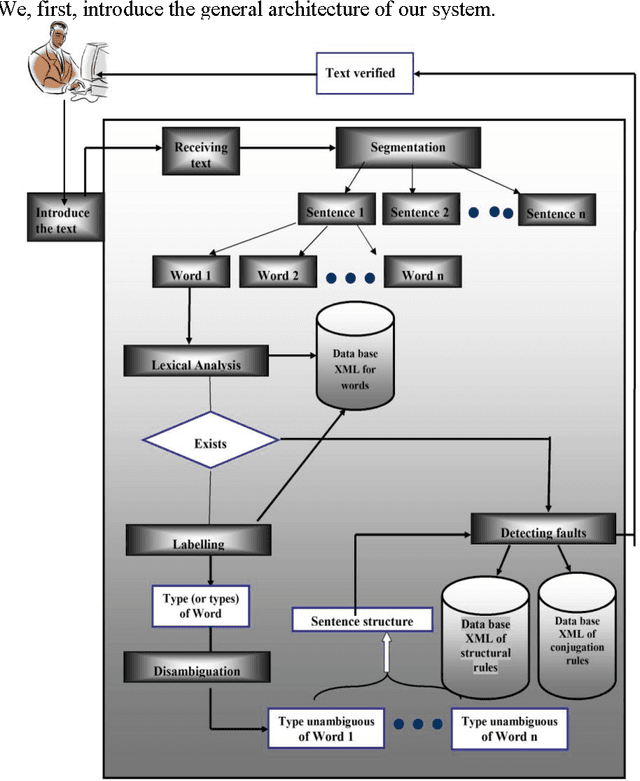
The study of natural language, especially Arabic, and mechanisms for the implementation of automatic processing is a fascinating field of study, with various potential applications. The importance of tools for natural language processing is materialized by the need to have applications that can effectively treat the vast mass of information available nowadays on electronic forms. Among these tools, mainly driven by the necessity of a fast writing in alignment to the actual daily life speed, our interest is on the writing auditors. The morphological and syntactic properties of Arabic make it a difficult language to master, and explain the lack in the processing tools for that language. Among these properties, we can mention: the complex structure of the Arabic word, the agglutinative nature, lack of vocalization, the segmentation of the text, the linguistic richness, etc.
Using a bag of Words for Automatic Medical Image Annotation with a Latent Semantic
Jun 04, 2013
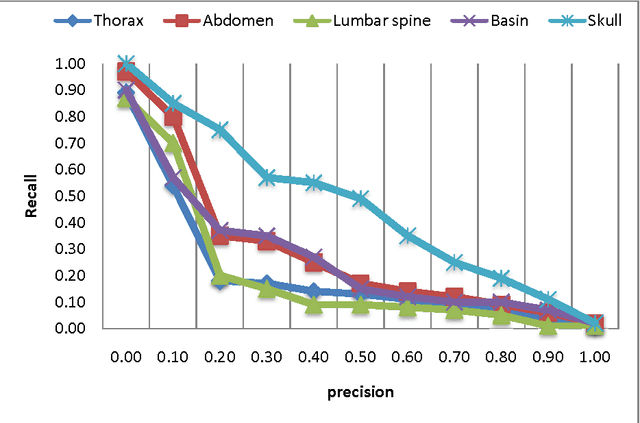
We present in this paper a new approach for the automatic annotation of medical images, using the approach of "bag-of-words" to represent the visual content of the medical image combined with text descriptors based approach tf.idf and reduced by latent semantic to extract the co-occurrence between terms and visual terms. A medical report is composed of a text describing a medical image. First, we are interested to index the text and extract all relevant terms using a thesaurus containing MeSH medical concepts. In a second phase, the medical image is indexed while recovering areas of interest which are invariant to change in scale, light and tilt. To annotate a new medical image, we use the approach of "bagof-words" to recover the feature vector. Indeed, we use the vector space model to retrieve similar medical image from the database training. The calculation of the relevance value of an image to the query image is based on the cosine function. We conclude with an experiment carried out on five types of radiological imaging to evaluate the performance of our system of medical annotation. The results showed that our approach works better with more images from the radiology of the skull.
* 10 pages, 6 figures
Using Hausdorff Distance for New Medical Image Annotation
Mar 08, 2012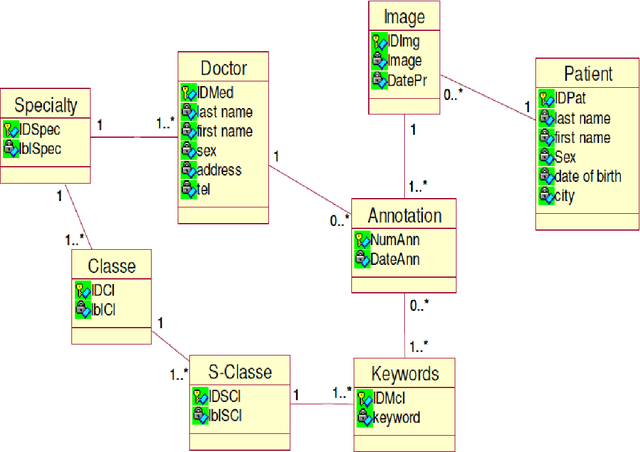

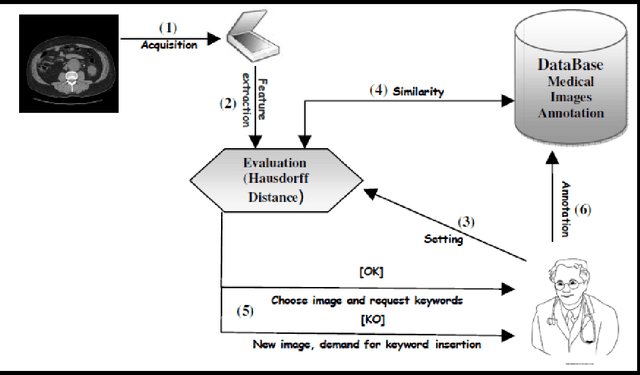
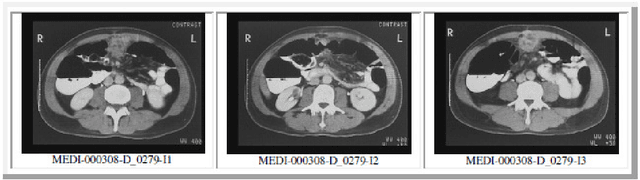
Medical images annotation is most of the time a repetitive hard task. Collecting old similar annotations and assigning them to new medical images may not only enhance the annotation process, but also reduce ambiguity caused by repetitive annotations. The goal of this work is to propose an approach based on Hausdorff distance able to compute similarity between a new medical image and old stored images. User has to choose then one of the similar images and annotations related to the selected one are assigned to the new one.