 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFU: Actor-Free critic Updates in off-policy RL for continuous control
Paper and Code
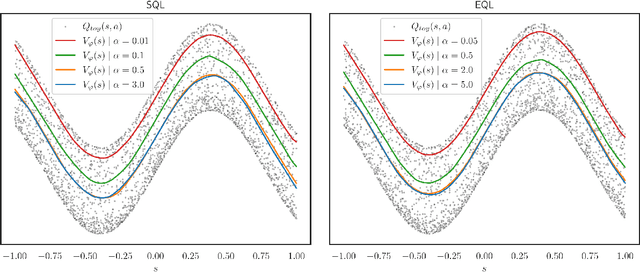
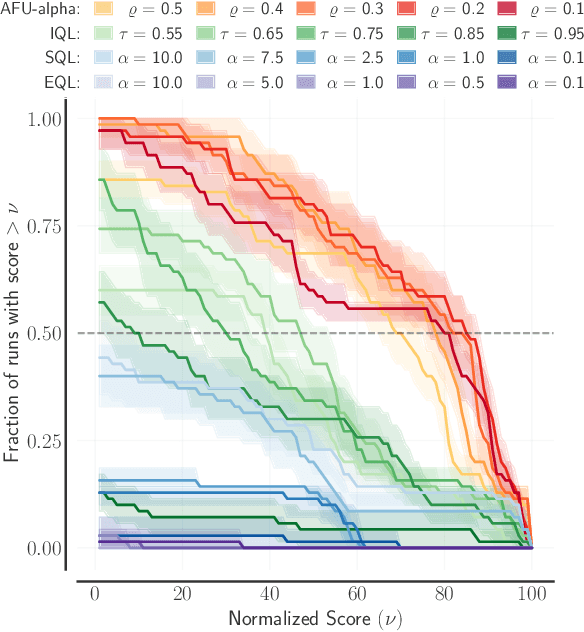
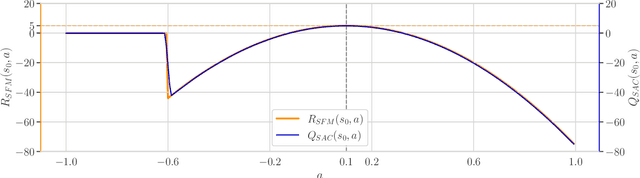

This paper presents AFU, an off-policy deep RL algorithm addressing in a new way the challenging "max-Q problem" in Q-learning for continuous action spaces, with a solution based on regression and conditional gradient scaling. AFU has an actor but its critic updates are entirely independent from it. As a consequence, the actor can be chosen freely. In the initial version, AFU-alpha, we employ the same stochastic actor as in Soft Actor-Critic (SAC), but we then study a simple failure mode of SAC and show how AFU can be modified to make actor updates less likely to become trapped in local optima, resulting in a second version of the algorithm, AFU-beta. Experimental results demonstrate the sample efficiency of both versions of AFU, marking it as the first model-free off-policy algorithm competitive with state-of-the-art actor-critic methods while departing from the actor-critic perspective.