 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritized Sweeping Neural DynaQ with Multiple Predecessors, and Hippocampal Replays
Paper and Code
Aug 13, 2018
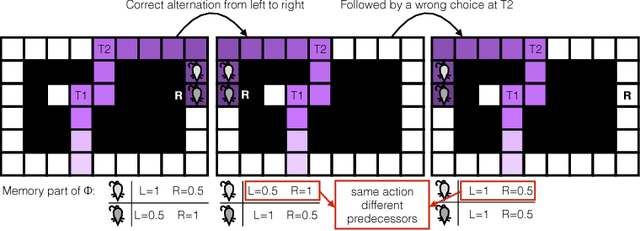

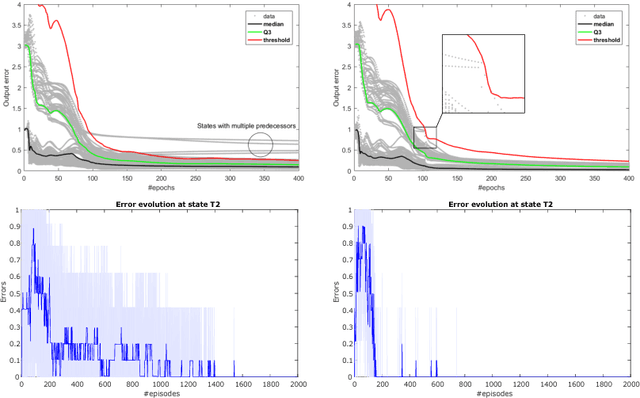
During sleep and awake rest, the hippocampus replays sequences of place cells that have been activated during prior experiences. These have been interpreted as a memory consolidation process, but recent results suggest a possible interpretation in terms of reinforcement learning. The Dyna reinforcement learning algorithms use off-line replays to improve learning. Under limited replay budget, a prioritized sweeping approach, which requires a model of the transitions to the predecessors, can be used to improve performance. We investigate whether such algorithms can explain the experimentally observed replays. We propose a neural network version of prioritized sweeping Q-learning, for which we developed a growing multiple expert algorithm, able to cope with multiple predecessors. The resulting architecture is able to improve the learning of simulated agents confronted to a navigation task. We predict that, in animals, learning the world model should occur during rest periods, and that the corresponding replays should be shuffled.