 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn explicit operator explains end-to-end computation in the modern neural networks used for sequence and language modeling
Apr 22, 2026We establish a mathematical correspondence between state space models, a state-of-the-art architecture for capturing long-range dependencies in data, and an exactly solvable nonlinear oscillator network. As a specific example of this general correspondence, we analyze the diagonal linear time-invariant implementation of the Structured State Space Sequence model (S4). The correspondence embeds S4D, a specific implementation of S4, into a ring network topology, in which recent inputs are encoded, as waves of activity traveling over the one-dimensional spatial layout of the network. We then derive an exact operator expression for the full forward pass of S4D, yielding an analytical characterization of its complete input-output map. This expression reveals that the nonlinear decoder in the system induces interactions between these information-carrying waves that enable classifying real-world sequences. These results generalize across modern SSM architectures, and show that they admit an exact mathematical description with a clear physical interpretation. These insights enable a new level of interpretability for these systems in terms of nonlinear oscillator networks.
Constrained Sampling to Guide Universal Manipulation RL
Feb 09, 2026We consider how model-based solvers can be leveraged to guide training of a universal policy to control from any feasible start state to any feasible goal in a contact-rich manipulation setting. While Reinforcement Learning (RL) has demonstrated its strength in such settings, it may struggle to sufficiently explore and discover complex manipulation strategies, especially in sparse-reward settings. Our approach is based on the idea of a lower-dimensional manifold of feasible, likely-visited states during such manipulation and to guide RL with a sampler from this manifold. We propose Sample-Guided RL, which uses model-based constraint solvers to efficiently sample feasible configurations (satisfying differentiable collision, contact, and force constraints) and leverage them to guide RL for universal (goal-conditioned) manipulation policies. We study using this data directly to bias state visitation, as well as using black-box optimization of open-loop trajectories between random configurations to impose a state bias and optionally add a behavior cloning loss. In a minimalistic double sphere manipulation setting, Sample-Guided RL discovers complex manipulation strategies and achieves high success rates in reaching any statically stable state. In a more challenging panda arm setting, our approach achieves a significant success rate over a near-zero baseline, and demonstrates a breadth of complex whole-body-contact manipulation strategies.
CrazyMARL: Decentralized Direct Motor Control Policies for Cooperative Aerial Transport of Cable-Suspended Payloads
Sep 17, 2025Collaborative transportation of cable-suspended payloads by teams of Unmanned Aerial Vehicles (UAVs) has the potential to enhance payload capacity, adapt to different payload shapes, and provide built-in compliance, making it attractive for applications ranging from disaster relief to precision logistics. However, multi-UAV coordination under disturbances, nonlinear payload dynamics, and slack--taut cable modes remains a challenging control problem. To our knowledge, no prior work has addressed these cable mode transitions in the multi-UAV context, instead relying on simplifying rigid-link assumptions. We propose CrazyMARL, a decentralized Reinforcement Learning (RL) framework for multi-UAV cable-suspended payload transport. Simulation results demonstrate that the learned policies can outperform classical decentralized controllers in terms of disturbance rejection and tracking precision, achieving an 80% recovery rate from harsh conditions compared to 44% for the baseline method. We also achieve successful zero-shot sim-to-real transfer and demonstrate that our policies are highly robust under harsh conditions, including wind, random external disturbances, and transitions between slack and taut cable dynamics. This work paves the way for autonomous, resilient UAV teams capable of executing complex payload missions in unstructured environments.
Safe Continual Domain Adaptation after Sim2Real Transfer of Reinforcement Learning Policies in Robotics
Mar 13, 2025Domain randomization has emerged as a fundamental technique in reinforcement learning (RL) to facilitate the transfer of policies from simulation to real-world robotic applications. Many existing domain randomization approaches have been proposed to improve robustness and sim2real transfer. These approaches rely on wide randomization ranges to compensate for the unknown actual system parameters, leading to robust but inefficient real-world policies. In addition, the policies pretrained in the domain-randomized simulation are fixed after deployment due to the inherent instability of the optimization processes based on RL and the necessity of sampling exploitative but potentially unsafe actions on the real system. This limits the adaptability of the deployed policy to the inevitably changing system parameters or environment dynamics over time. We leverage safe RL and continual learning under domain-randomized simulation to address these limitations and enable safe deployment-time policy adaptation in real-world robot control. The experiments show that our method enables the policy to adapt and fit to the current domain distribution and environment dynamics of the real system while minimizing safety risks and avoiding issues like catastrophic forgetting of the general policy found in randomized simulation during the pretraining phase. Videos and supplementary material are available at https://safe-cda.github.io/.
Direct Imitation Learning-based Visual Servoing using the Large Projection Formulation
Jun 13, 2024


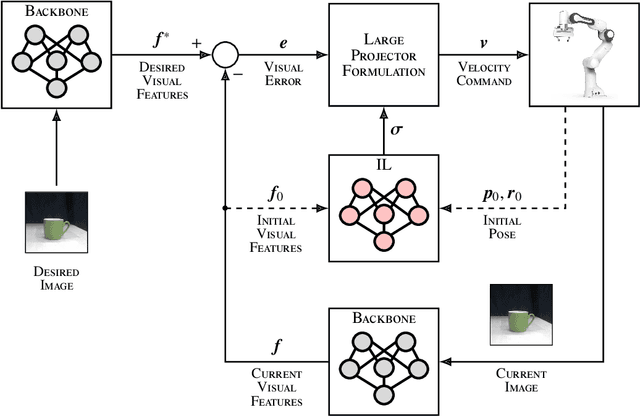
Today robots must be safe, versatile, and user-friendly to operate in unstructured and human-populated environments. Dynamical system-based imitation learning enables robots to perform complex tasks stably and without explicit programming, greatly simplifying their real-world deployment. To exploit the full potential of these systems it is crucial to implement closed loops that use visual feedback. Vision permits to cope with environmental changes, but is complex to handle due to the high dimension of the image space. This study introduces a dynamical system-based imitation learning for direct visual servoing. It leverages off-the-shelf deep learning-based perception backbones to extract robust features from the raw input image, and an imitation learning strategy to execute sophisticated robot motions. The learning blocks are integrated using the large projection task priority formulation. As demonstrated through extensive experimental analysis, the proposed method realizes complex tasks with a robotic manipulator.
Continual Domain Randomization
Mar 18, 2024Domain Randomization (DR) is commonly used for sim2real transfer of reinforcement learning (RL) policies in robotics. Most DR approaches require a simulator with a fixed set of tunable parameters from the start of the training, from which the parameters are randomized simultaneously to train a robust model for use in the real world. However, the combined randomization of many parameters increases the task difficulty and might result in sub-optimal policies. To address this problem and to provide a more flexible training process, we propose Continual Domain Randomization (CDR) for RL that combines domain randomization with continual learning to enable sequential training in simulation on a subset of randomization parameters at a time. Starting from a model trained in a non-randomized simulation where the task is easier to solve, the model is trained on a sequence of randomizations, and continual learning is employed to remember the effects of previous randomizations. Our robotic reaching and grasping tasks experiments show that the model trained in this fashion learns effectively in simulation and performs robustly on the real robot while matching or outperforming baselines that employ combined randomization or sequential randomization without continual learning. Our code and videos are available at https://continual-dr.github.io/.
Effect of Optimizer, Initializer, and Architecture of Hypernetworks on Continual Learning from Demonstration
Dec 31, 2023In continual learning from demonstration (CLfD), a robot learns a sequence of real-world motion skills continually from human demonstrations. Recently, hypernetworks have been successful in solving this problem. In this paper, we perform an exploratory study of the effects of different optimizers, initializers, and network architectures on the continual learning performance of hypernetworks for CLfD. Our results show that adaptive learning rate optimizers work well, but initializers specially designed for hypernetworks offer no advantages for CLfD. We also show that hypernetworks that are capable of stable trajectory predictions are robust to different network architectures. Our open-source code is available at https://github.com/sebastianbergner/ExploringCLFD.
Scalable and Efficient Continual Learning from Demonstration via Hypernetwork-generated Stable Dynamics Model
Nov 06, 2023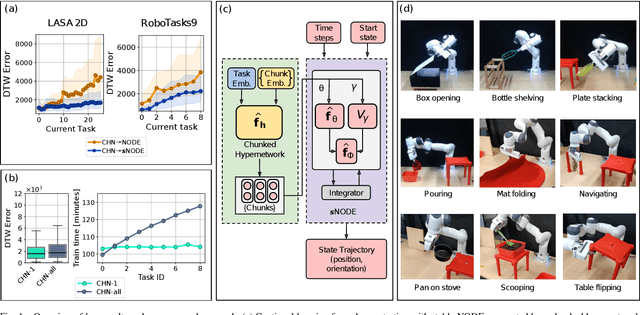
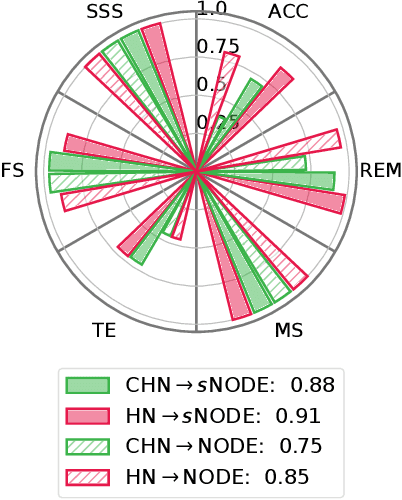
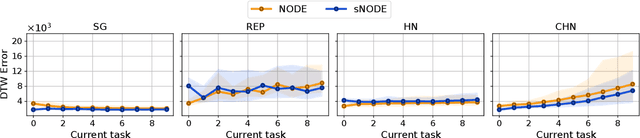
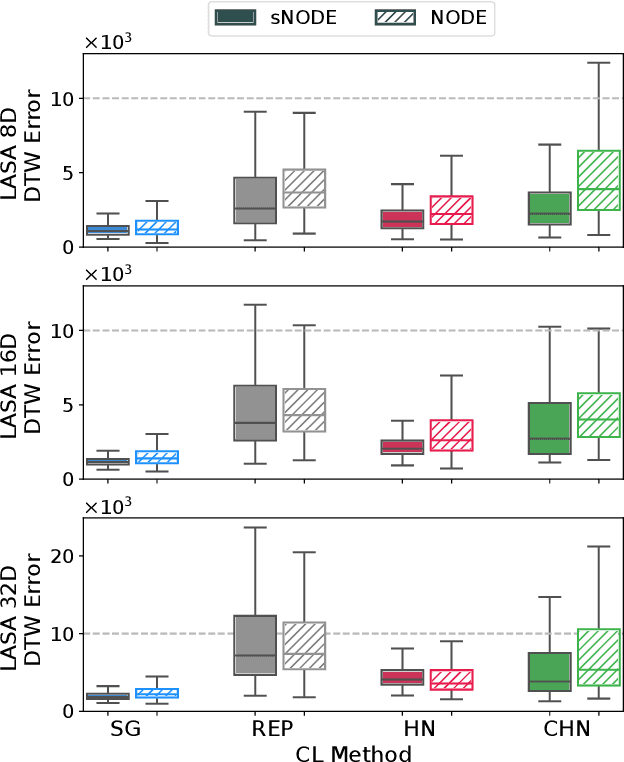
Learning from demonstration (LfD) provides an efficient way to train robots. The learned motions should be convergent and stable, but to be truly effective in the real world, LfD-capable robots should also be able to remember multiple motion skills. Multi-skill retention is a capability missing from existing stable-LfD approaches. On the other hand, recent work on continual-LfD has shown that hypernetwork-generated neural ordinary differential equation solvers, can learn multiple LfD tasks sequentially, but this approach lacks stability guarantees. We propose an approach for stable continual-LfD in which a hypernetwork generates two networks: a trajectory learning dynamics model, and a trajectory stabilizing Lyapunov function. The introduction of stability not only generates stable trajectories but also greatly improves continual learning performance, especially in the size-efficient chunked hypernetworks. With our approach, we can continually train a single model to predict the position and orientation trajectories of the robot's end-effector simultaneously for multiple real world tasks without retraining on past demonstrations. We also propose stochastic regularization with a single randomly sampled regularization term in hypernetworks, which reduces the cumulative training time cost for $N$ tasks from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$ without any loss in performance in real-world tasks. We empirically evaluate our approach on the popular LASA dataset, on high-dimensional extensions of LASA (including up to 32 dimensions) to assess scalability, and on a novel extended robotic task dataset (RoboTasks9) to assess real-world performance. In trajectory error metrics, stability metrics and continual learning metrics our approach performs favorably, compared to other baselines. Code and datasets will be shared after submission.
GRINN: A Physics-Informed Neural Network for solving hydrodynamic systems in the presence of self-gravity
Aug 15, 2023Modeling self-gravitating gas flows is essential to answering many fundamental questions in astrophysics. This spans many topics including planet-forming disks, star-forming clouds, galaxy formation, and the development of large-scale structures in the Universe. However, the nonlinear interaction between gravity and fluid dynamics offers a formidable challenge to solving the resulting time-dependent partial differential equations (PDEs) in three dimensions (3D). By leveraging the universal approximation capabilities of a neural network within a mesh-free framework, physics informed neural networks (PINNs) offer a new way of addressing this challenge. We introduce the gravity-informed neural network (GRINN), a PINN-based code, to simulate 3D self-gravitating hydrodynamic systems. Here, we specifically study gravitational instability and wave propagation in an isothermal gas. Our results match a linear analytic solution to within 1\% in the linear regime and a conventional grid code solution to within 5\% as the disturbance grows into the nonlinear regime. We find that the computation time of the GRINN does not scale with the number of dimensions. This is in contrast to the scaling of the grid-based code for the hydrodynamic and self-gravity calculations as the number of dimensions is increased. Our results show that the GRINN computation time is longer than the grid code in one- and two- dimensional calculations but is an order of magnitude lesser than the grid code in 3D with similar accuracy. Physics-informed neural networks like GRINN thus show promise for advancing our ability to model 3D astrophysical flows.
Action Noise in Off-Policy Deep Reinforcement Learning: Impact on Exploration and Performance
Jun 08, 2022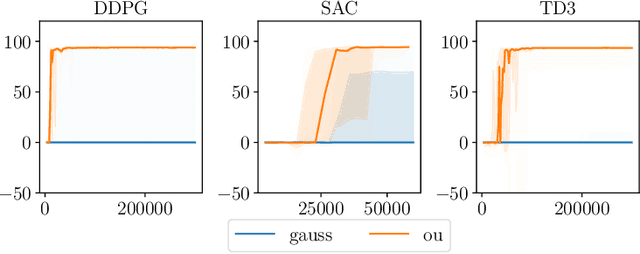
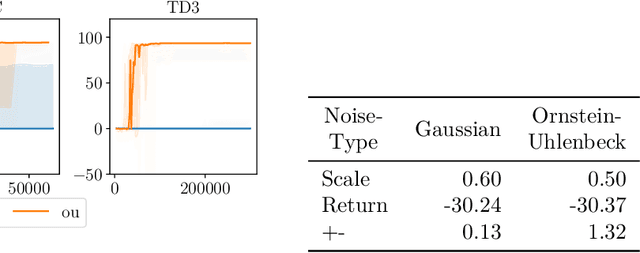
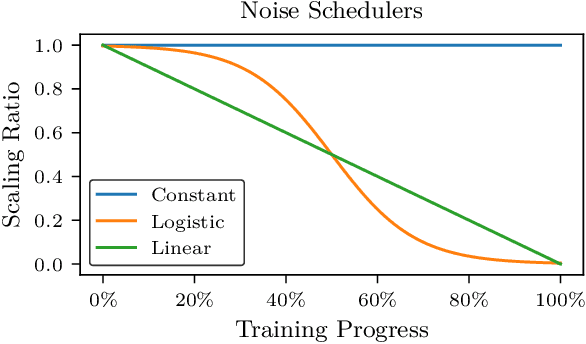
Many deep reinforcement learning algorithms rely on simple forms of exploration, such as the additive action-noise often used in continuous control domains. Typically, the scaling factor of this action noise is chosen as a hyper-parameter and kept constant during training. In this paper, we analyze how the learned policy is impacted by the noise type, scale, and reducing of the scaling factor over time. We consider the two most prominent types of action-noise: Gaussian and Ornstein-Uhlenbeck noise, and perform a vast experimental campaign by systematically varying the noise type and scale parameter, and by measuring variables of interest like the expected return of the policy and the state space coverage during exploration. For the latter, we propose a novel state-space coverage measure $\operatorname{X}_{\mathcal{U}\text{rel}}$ that is more robust to boundary artifacts than previously proposed measures. Larger noise scales generally increase state space coverage. However, we found that increasing the space coverage using a larger noise scale is often not beneficial. On the contrary, reducing the noise-scale over the training process reduces the variance and generally improves the learning performance. We conclude that the best noise-type and scale are environment dependent, and based on our observations, derive heuristic rules for guiding the choice of the action noise as a starting point for further optimization.