 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Forward Kinematics for TensorFlow 2
Jan 24, 2023



Robotic systems are often complex and depend on the integration of a large number of software components. One important component in robotic systems provides the calculation of forward kinematics, which is required by both motion-planning and perception related components. End-to-end learning systems based on deep learning require passing gradients across component boundaries.Typical software implementations of forward kinematics are not differentiable, and thus prevent the construction of gradient-based, end-to-end learning systems. In this paper we present a library compatible with ROS-URDF that computes forward kinematics while simultaneously giving access to the gradients w.r.t. joint configurations and model parameters, allowing gradient-based learning and model identification. Our Python library is based on Tensorflow~2 and is auto-differentiable. It supports calculating a large number of kinematic configurations on the GPU in parallel, yielding a considerable performance improvement compared to sequential CPU-based calculation. https://github.com/lumoe/dlkinematics.git
How do Offline Measures for Exploration in Reinforcement Learning behave?
Oct 29, 2020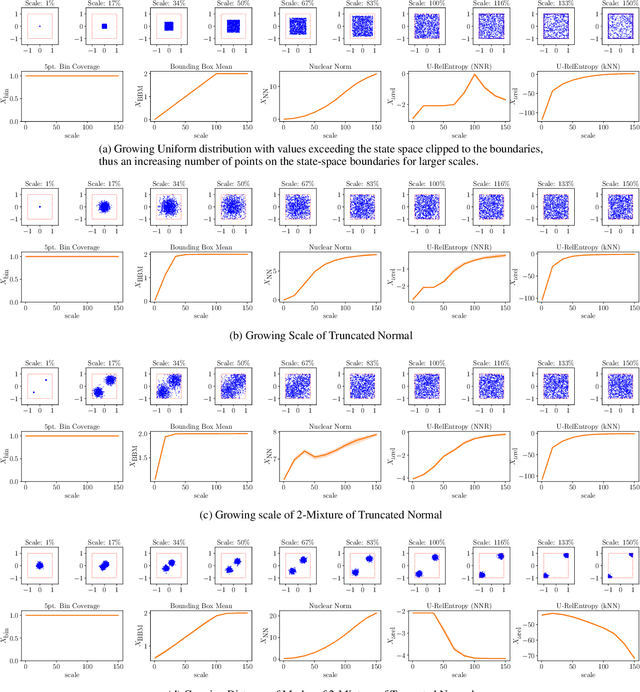
Sufficient exploration is paramount for the success of a reinforcement learning agent. Yet, exploration is rarely assessed in an algorithm-independent way. We compare the behavior of three data-based, offline exploration metrics described in the literature on intuitive simple distributions and highlight problems to be aware of when using them. We propose a fourth metric,uniform relative entropy, and implement it using either a k-nearest-neighbor or a nearest-neighbor-ratio estimator, highlighting that the implementation choices have a profound impact on these measures.
Improving the Exploration of Deep Reinforcement Learning in Continuous Domains using Planning for Policy Search
Oct 24, 2020
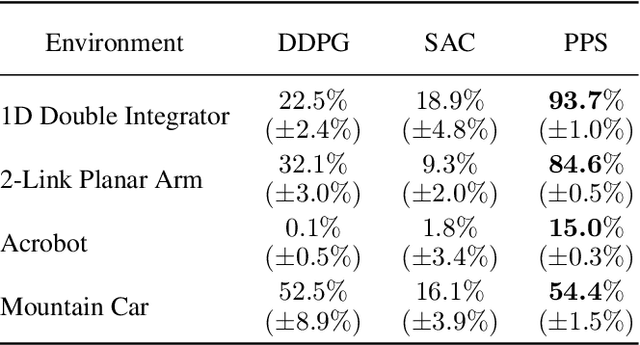
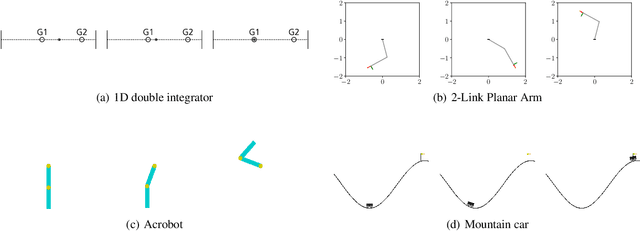

Local policy search is performed by most Deep Reinforcement Learning (D-RL) methods, which increases the risk of getting trapped in a local minimum. Furthermore, the availability of a simulation model is not fully exploited in D-RL even in simulation-based training, which potentially decreases efficiency. To better exploit simulation models in policy search, we propose to integrate a kinodynamic planner in the exploration strategy and to learn a control policy in an offline fashion from the generated environment interactions. We call the resulting model-based reinforcement learning method PPS (Planning for Policy Search). We compare PPS with state-of-the-art D-RL methods in typical RL settings including underactuated systems. The comparison shows that PPS, guided by the kinodynamic planner, collects data from a wider region of the state space. This generates training data that helps PPS discover better policies.