Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrigamiSet1.0: Two New Datasets for Origami Classification and Difficulty Estimation
Paper and Code

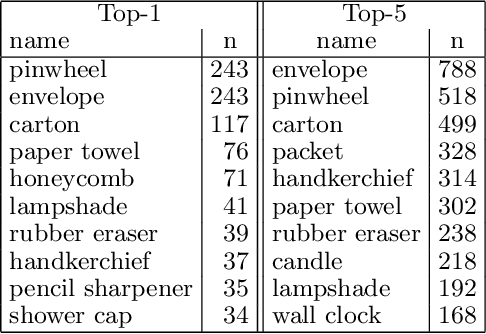


Origami is becoming more and more relevant to research. However, there is no public dataset yet available and there hasn't been any research on this topic in machine learning. We constructed an origami dataset using images from the multimedia commons and other databases. It consists of two subsets: one for classification of origami images and the other for difficulty estimation. We obtained 16000 images for classification (half origami, half other objects) and 1509 for difficulty estimation with $3$ different categories (easy: 764, intermediate: 427, complex: 318). The data can be downloaded at: https://github.com/multimedia-berkeley/OriSet. Finally, we provide machine learning baselines.
* In Proceedings of Origami Science Maths Education, 7OSME, Oxford UK
(2018)
View paper on