Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIME: An Online Tool for the Visual Comparison of Cross-Modal Retrieval Models
Paper and Code
Oct 19, 2020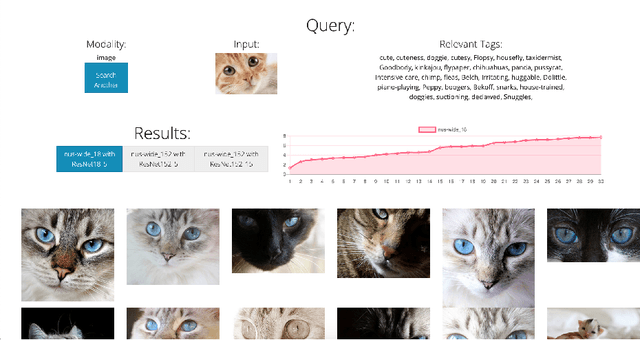
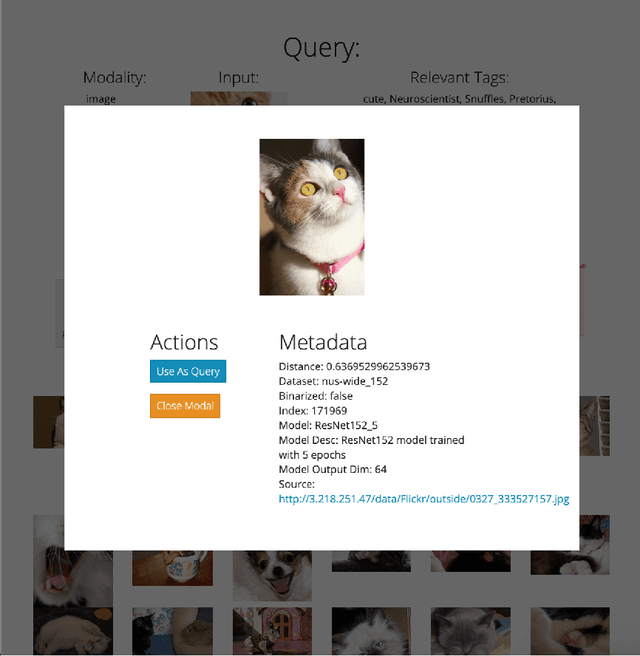
Cross-modal retrieval relies on accurate models to retrieve relevant results for queries across modalities such as image, text, and video. In this paper, we build upon previous work by tackling the difficulty of evaluating models both quantitatively and qualitatively quickly. We present DIME (Dataset, Index, Model, Embedding), a modality-agnostic tool that handles multimodal datasets, trained models, and data preprocessors to support straightforward model comparison with a web browser graphical user interface. DIME inherently supports building modality-agnostic queryable indexes and extraction of relevant feature embeddings, and thus effectively doubles as an efficient cross-modal tool to explore and search through datasets.
View paper on