 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting COVID-19 Conspiracy Theories with Transformers and TF-IDF
Paper and Code
May 01, 2022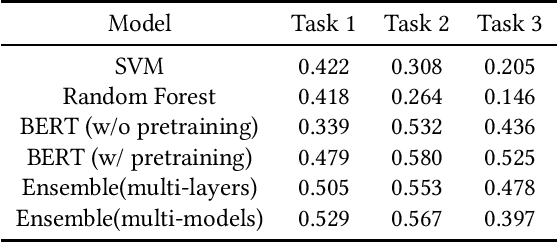
The sharing of fake news and conspiracy theories on social media has wide-spread negative effects. By designing and applying different machine learning models, researchers have made progress in detecting fake news from text. However, existing research places a heavy emphasis on general, common-sense fake news, while in reality fake news often involves rapidly changing topics and domain-specific vocabulary. In this paper, we present our methods and results for three fake news detection tasks at MediaEval benchmark 2021 that specifically involve COVID-19 related topics. We experiment with a group of text-based models including Support Vector Machines, Random Forest, BERT, and RoBERTa. We find that a pre-trained transformer yields the best validation results, but a randomly initialized transformer with smart design can also be trained to reach accuracies close to that of the pre-trained transformer.