 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAVE: Premise-Aware Validation and Editing for Retrieval-Augmented LLMs
Mar 21, 2026Retrieval-augmented language models can retrieve relevant evidence yet still commit to answers before explicitly checking whether the retrieved context supports the conclusion. We present PAVE (Premise-Grounded Answer Validation and Editing), an inference-time validation layer for evidence-grounded question answering. PAVE decomposes retrieved context into question-conditioned atomic facts, drafts an answer, scores how well that draft is supported by the extracted premises, and revises low-support outputs before finalization. The resulting trace makes answer commitment auditable at the level of explicit premises, support scores, and revision decisions. In controlled ablations with a fixed retriever and backbone, PAVE outperforms simpler post-retrieval baselines in two evidence-grounded QA settings, with the largest gain reaching 32.7 accuracy points on a span-grounded benchmark. We view these findings as proof-of-concept evidence that explicit premise extraction plus support-gated revision can strengthen evidence-grounded consistency in retrieval-augmented LLM systems.
Permutation-Consensus Listwise Judging for Robust Factuality Evaluation
Mar 20, 2026Large language models (LLMs) are now widely used as judges, yet their decisions can change under presentation choices that should be irrelevant. We study one such source of instability: candidate-order sensitivity in listwise factuality evaluation, where several answers can look similarly polished while differing sharply in hallucination risk. We introduce PCFJudge, an inference-time method that reruns the same factuality-first listwise prompt over multiple orderings of the same candidate set and aggregates the resulting scores, ranks, and uncertainty signals into a single consensus decision. On RewardBench 2 Factuality, PCFJudge improves over direct judging by up to 7 absolute points. Development ablations show that the dominant gain comes from permutation consensus itself rather than from heavier arbitration layers. These results suggest that a meaningful share of factuality-judging error arises from order instability, and that averaging over this nuisance variation is a simple and effective way to make LLM evaluation more reliable.
CounterRefine: Answer-Conditioned Counterevidence Retrieval for Inference-Time Knowledge Repair in Factual Question Answering
Mar 17, 2026In factual question answering, many errors are not failures of access but failures of commitment: the system retrieves relevant evidence, yet still settles on the wrong answer. We present CounterRefine, a lightweight inference-time repair layer for retrieval-grounded question answering. CounterRefine first produces a short answer from retrieved evidence, then gathers additional support and conflicting evidence with follow-up queries conditioned on that draft answer, and finally applies a restricted refinement step that outputs either KEEP or REVISE, with proposed revisions accepted only if they pass deterministic validation. In effect, CounterRefine turns retrieval into a mechanism for testing a provisional answer rather than merely collecting more context. On the full SimpleQA benchmark, CounterRefine improves a matched GPT-5 Baseline-RAG by 5.8 points and reaches a 73.1 percent correct rate, while exceeding the reported one-shot GPT-5.4 score by roughly 40 points. These findings suggest a simple but important direction for knowledgeable foundation models: beyond accessing evidence, they should also be able to use that evidence to reconsider and, when necessary, repair their own answers.
CL-ISR: A Contrastive Learning and Implicit Stance Reasoning Framework for Misleading Text Detection on Social Media
Jun 05, 2025Misleading text detection on social media platforms is a critical research area, as these texts can lead to public misunderstanding, social panic and even economic losses. This paper proposes a novel framework - CL-ISR (Contrastive Learning and Implicit Stance Reasoning), which combines contrastive learning and implicit stance reasoning, to improve the detection accuracy of misleading texts on social media. First, we use the contrastive learning algorithm to improve the model's learning ability of semantic differences between truthful and misleading texts. Contrastive learning could help the model to better capture the distinguishing features between different categories by constructing positive and negative sample pairs. This approach enables the model to capture distinguishing features more effectively, particularly in linguistically complicated situations. Second, we introduce the implicit stance reasoning module, to explore the potential stance tendencies in the text and their relationships with related topics. This method is effective for identifying content that misleads through stance shifting or emotional manipulation, because it can capture the implicit information behind the text. Finally, we integrate these two algorithms together to form a new framework, CL-ISR, which leverages the discriminative power of contrastive learning and the interpretive depth of stance reasoning to significantly improve detection effect.
Advancing Sentiment Analysis: A Novel LSTM Framework with Multi-head Attention
Mar 11, 2025This work proposes an LSTM-based sentiment classification model with multi-head attention mechanism and TF-IDF optimization. Through the integration of TF-IDF feature extraction and multi-head attention, the model significantly improves text sentiment analysis performance. Experimental results on public data sets demonstrate that the new method achieves substantial improvements in the most critical metrics like accuracy, recall, and F1-score compared to baseline models. Specifically, the model achieves an accuracy of 80.28% on the test set, which is improved by about 12% in comparison with standard LSTM models. Ablation experiments also support the necessity and necessity of all modules, in which the impact of multi-head attention is greatest to performance improvement. This research provides a proper approach to sentiment analysis, which can be utilized in public opinion monitoring, product recommendation, etc.
Synthetic Data Augmentation for Enhancing Harmful Algal Bloom Detection with Machine Learning
Mar 05, 2025Harmful Algal Blooms (HABs) pose severe threats to aquatic ecosystems and public health, resulting in substantial economic losses globally. Early detection is crucial but often hindered by the scarcity of high-quality datasets necessary for training reliable machine learning (ML) models. This study investigates the use of synthetic data augmentation using Gaussian Copulas to enhance ML-based HAB detection systems. Synthetic datasets of varying sizes (100-1,000 samples) were generated using relevant environmental features$\unicode{x2015}$water temperature, salinity, and UVB radiation$\unicode{x2015}$with corrected Chlorophyll-a concentration as the target variable. Experimental results demonstrate that moderate synthetic augmentation significantly improves model performance (RMSE reduced from 0.4706 to 0.1850; $p < 0.001$). However, excessive synthetic data introduces noise and reduces predictive accuracy, emphasizing the need for a balanced approach to data augmentation. These findings highlight the potential of synthetic data to enhance HAB monitoring systems, offering a scalable and cost-effective method for early detection and mitigation of ecological and public health risks.
A Hybrid Transformer Model for Fake News Detection: Leveraging Bayesian Optimization and Bidirectional Recurrent Unit
Feb 13, 2025


In this paper, we propose an optimized Transformer model that integrates Bayesian algorithms with a Bidirectional Gated Recurrent Unit (BiGRU), and apply it to fake news classification for the first time. First, we employ the TF-IDF method to extract features from news texts and transform them into numeric representations to facilitate subsequent machine learning tasks. Two sets of experiments are then conducted for fake news detection and classification: one using a Transformer model optimized only with BiGRU, and the other incorporating Bayesian algorithms into the BiGRU-based Transformer. Experimental results show that the BiGRU-optimized Transformer achieves 100% accuracy on the training set and 99.67% on the test set, while the addition of the Bayesian algorithm maintains 100% accuracy on the training set and slightly improves test-set accuracy to 99.73%. This indicates that the Bayesian algorithm boosts model accuracy by 0.06%, further enhancing the detection capability for fake news. Moreover, the proposed algorithm converges rapidly at around the 10th training epoch with accuracy nearing 100%, demonstrating both its effectiveness and its fast classification ability. Overall, the optimized Transformer model, enhanced by the Bayesian algorithm and BiGRU, exhibits excellent continuous learning and detection performance, offering a robust technical means to combat the spread of fake news in the current era of information overload.
Cost-Effective Robotic Handwriting System with AI Integration
Jan 14, 2025
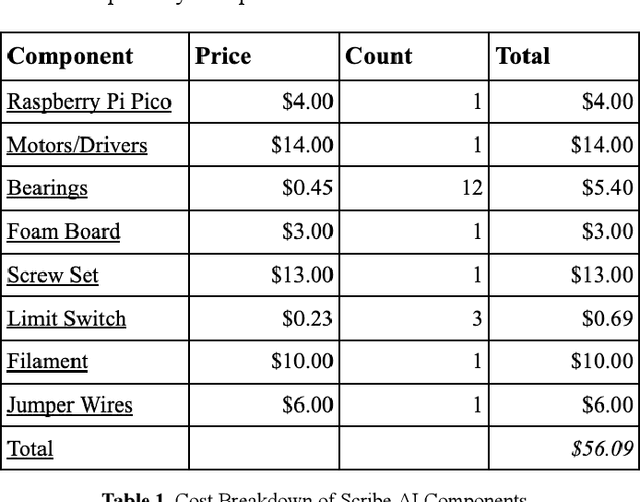
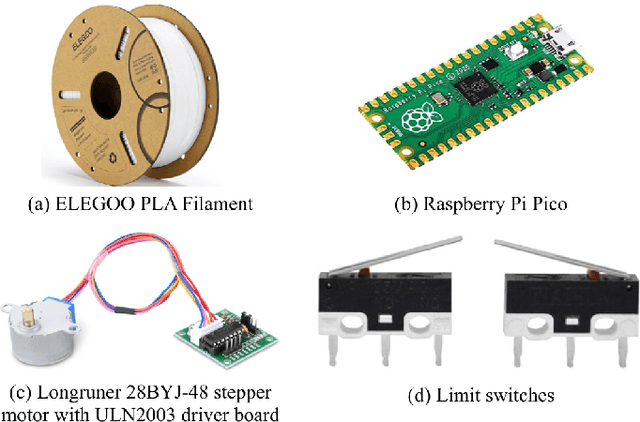
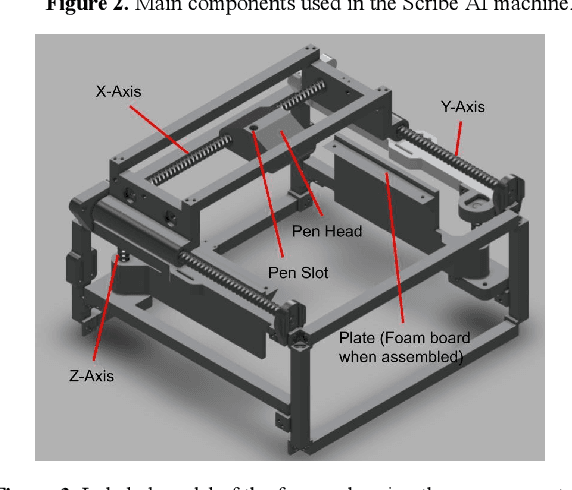
This paper introduces a cost-effective robotic handwriting system designed to replicate human-like handwriting with high precision. Combining a Raspberry Pi Pico microcontroller, 3D-printed components, and a machine learning-based handwriting generation model implemented via TensorFlow, the system converts user-supplied text into realistic stroke trajectories. By leveraging lightweight 3D-printed materials and efficient mechanical designs, the system achieves a total hardware cost of approximately \$56, significantly undercutting commercial alternatives. Experimental evaluations demonstrate handwriting precision within $\pm$0.3 millimeters and a writing speed of approximately 200 mm/min, positioning the system as a viable solution for educational, research, and assistive applications. This study seeks to lower the barriers to personalized handwriting technologies, making them accessible to a broader audience.
* This is an updated version of a paper originally presented at the 2024 IEEE Long Island Systems, Applications and Technology Conference (LISAT)
Optimization of Transformer heart disease prediction model based on particle swarm optimization algorithm
Dec 03, 2024



Aiming at the latest particle swarm optimization algorithm, this paper proposes an improved Transformer model to improve the accuracy of heart disease prediction and provide a new algorithm idea. We first use three mainstream machine learning classification algorithms - decision tree, random forest and XGBoost, and then output the confusion matrix of these three models. The results showed that the random forest model had the best performance in predicting the classification of heart disease, with an accuracy of 92.2%. Then, we apply the Transformer model based on particle swarm optimization (PSO) algorithm to the same dataset for classification experiment. The results show that the classification accuracy of the model is as high as 96.5%, 4.3 percentage points higher than that of random forest, which verifies the effectiveness of PSO in optimizing Transformer model. From the above research, we can see that particle swarm optimization significantly improves Transformer performance in heart disease prediction. Improving the ability to predict heart disease is a global priority with benefits for all humankind. Accurate prediction can enhance public health, optimize medical resources, and reduce healthcare costs, leading to healthier populations and more productive societies worldwide. This advancement paves the way for more efficient health management and supports the foundation of a healthier, more resilient global community.
Mitigating Bias in Queer Representation within Large Language Models: A Collaborative Agent Approach
Nov 12, 2024Large Language Models (LLMs) often perpetuate biases in pronoun usage, leading to misrepresentation or exclusion of queer individuals. This paper addresses the specific problem of biased pronoun usage in LLM outputs, particularly the inappropriate use of traditionally gendered pronouns ("he," "she") when inclusive language is needed to accurately represent all identities. We introduce a collaborative agent pipeline designed to mitigate these biases by analyzing and optimizing pronoun usage for inclusivity. Our multi-agent framework includes specialized agents for both bias detection and correction. Experimental evaluations using the Tango dataset-a benchmark focused on gender pronoun usage-demonstrate that our approach significantly improves inclusive pronoun classification, achieving a 32.6 percentage point increase over GPT-4o in correctly disagreeing with inappropriate traditionally gendered pronouns $(\chi^2 = 38.57, p < 0.0001)$. These results accentuate the potential of agent-driven frameworks in enhancing fairness and inclusivity in AI-generated content, demonstrating their efficacy in reducing biases and promoting socially responsible AI.