 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Sentiment Analysis: A Novel LSTM Framework with Multi-head Attention
Mar 11, 2025This work proposes an LSTM-based sentiment classification model with multi-head attention mechanism and TF-IDF optimization. Through the integration of TF-IDF feature extraction and multi-head attention, the model significantly improves text sentiment analysis performance. Experimental results on public data sets demonstrate that the new method achieves substantial improvements in the most critical metrics like accuracy, recall, and F1-score compared to baseline models. Specifically, the model achieves an accuracy of 80.28% on the test set, which is improved by about 12% in comparison with standard LSTM models. Ablation experiments also support the necessity and necessity of all modules, in which the impact of multi-head attention is greatest to performance improvement. This research provides a proper approach to sentiment analysis, which can be utilized in public opinion monitoring, product recommendation, etc.
A Hybrid Transformer Model for Fake News Detection: Leveraging Bayesian Optimization and Bidirectional Recurrent Unit
Feb 13, 2025


In this paper, we propose an optimized Transformer model that integrates Bayesian algorithms with a Bidirectional Gated Recurrent Unit (BiGRU), and apply it to fake news classification for the first time. First, we employ the TF-IDF method to extract features from news texts and transform them into numeric representations to facilitate subsequent machine learning tasks. Two sets of experiments are then conducted for fake news detection and classification: one using a Transformer model optimized only with BiGRU, and the other incorporating Bayesian algorithms into the BiGRU-based Transformer. Experimental results show that the BiGRU-optimized Transformer achieves 100% accuracy on the training set and 99.67% on the test set, while the addition of the Bayesian algorithm maintains 100% accuracy on the training set and slightly improves test-set accuracy to 99.73%. This indicates that the Bayesian algorithm boosts model accuracy by 0.06%, further enhancing the detection capability for fake news. Moreover, the proposed algorithm converges rapidly at around the 10th training epoch with accuracy nearing 100%, demonstrating both its effectiveness and its fast classification ability. Overall, the optimized Transformer model, enhanced by the Bayesian algorithm and BiGRU, exhibits excellent continuous learning and detection performance, offering a robust technical means to combat the spread of fake news in the current era of information overload.
A Hybrid Attention Framework for Fake News Detection with Large Language Models
Jan 21, 2025With the rapid growth of online information, the spread of fake news has become a serious social challenge. In this study, we propose a novel detection framework based on Large Language Models (LLMs) to identify and classify fake news by integrating textual statistical features and deep semantic features. Our approach utilizes the contextual understanding capability of the large language model for text analysis and introduces a hybrid attention mechanism to focus on feature combinations that are particularly important for fake news identification. Extensive experiments on the WELFake news dataset show that our model significantly outperforms existing methods, with a 1.5\% improvement in F1 score. In addition, we assess the interpretability of the model through attention heat maps and SHAP values, providing actionable insights for content review strategies. Our framework provides a scalable and efficient solution to deal with the spread of fake news and helps build a more reliable online information ecosystem.
Enhancing User Intent for Recommendation Systems via Large Language Models
Jan 18, 2025Recommendation systems play a critical role in enhancing user experience and engagement in various online platforms. Traditional methods, such as Collaborative Filtering (CF) and Content-Based Filtering (CBF), rely heavily on past user interactions or item features. However, these models often fail to capture the dynamic and evolving nature of user preferences. To address these limitations, we propose DUIP (Dynamic User Intent Prediction), a novel framework that combines LSTM networks with Large Language Models (LLMs) to dynamically capture user intent and generate personalized item recommendations. The LSTM component models the sequential and temporal dependencies of user behavior, while the LLM utilizes the LSTM-generated prompts to predict the next item of interest. Experimental results on three diverse datasets ML-1M, Games, and Bundle show that DUIP outperforms a wide range of baseline models, demonstrating its ability to handle the cold-start problem and real-time intent adaptation. The integration of dynamic prompts based on recent user interactions allows DUIP to provide more accurate, context-aware, and personalized recommendations. Our findings suggest that DUIP is a promising approach for next-generation recommendation systems, with potential for further improvements in cross-modal recommendations and scalability.
The Application of Large Language Models in Recommendation Systems
Jan 04, 2025The integration of Large Language Models into recommendation frameworks presents key advantages for personalization and adaptability of experiences to the users. Classic methods of recommendations, such as collaborative filtering and content-based filtering, are seriously limited in the solution of cold-start problems, sparsity of data, and lack of diversity in information considered. LLMs, of which GPT-4 is a good example, have emerged as powerful tools that enable recommendation frameworks to tap into unstructured data sources such as user reviews, social interactions, and text-based content. By analyzing these data sources, LLMs improve the accuracy and relevance of recommendations, thereby overcoming some of the limitations of traditional approaches. This work discusses applications of LLMs in recommendation systems, especially in electronic commerce, social media platforms, streaming services, and educational technologies. This showcases how LLMs enrich recommendation diversity, user engagement, and the system's adaptability; yet it also looks into the challenges connected to their technical implementation. This can also be presented as a study that shows the potential of LLMs for changing user experiences and making innovation possible in industries.
Optimization of Transformer heart disease prediction model based on particle swarm optimization algorithm
Dec 03, 2024



Aiming at the latest particle swarm optimization algorithm, this paper proposes an improved Transformer model to improve the accuracy of heart disease prediction and provide a new algorithm idea. We first use three mainstream machine learning classification algorithms - decision tree, random forest and XGBoost, and then output the confusion matrix of these three models. The results showed that the random forest model had the best performance in predicting the classification of heart disease, with an accuracy of 92.2%. Then, we apply the Transformer model based on particle swarm optimization (PSO) algorithm to the same dataset for classification experiment. The results show that the classification accuracy of the model is as high as 96.5%, 4.3 percentage points higher than that of random forest, which verifies the effectiveness of PSO in optimizing Transformer model. From the above research, we can see that particle swarm optimization significantly improves Transformer performance in heart disease prediction. Improving the ability to predict heart disease is a global priority with benefits for all humankind. Accurate prediction can enhance public health, optimize medical resources, and reduce healthcare costs, leading to healthier populations and more productive societies worldwide. This advancement paves the way for more efficient health management and supports the foundation of a healthier, more resilient global community.
A Survey on Semi-parametric Machine Learning Technique for Time Series Forecasting
Apr 02, 2021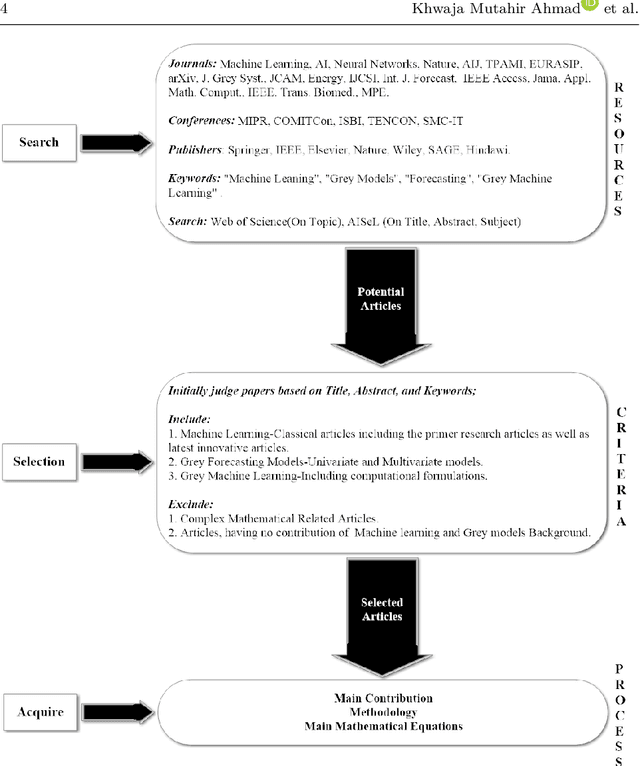

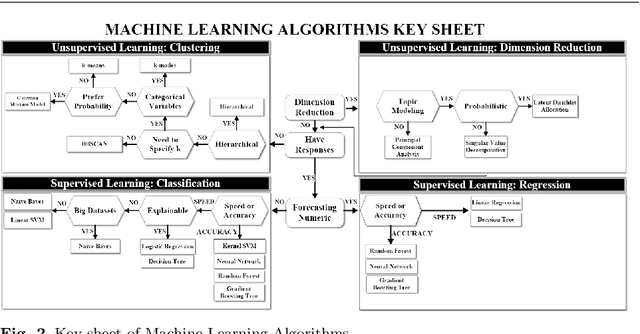

Artificial Intelligence (AI) has recently shown its capabilities for almost every field of life. Machine Learning, which is a subset of AI, is a `HOT' topic for researchers. Machine Learning outperforms other classical forecasting techniques in almost all-natural applications. It is a crucial part of modern research. As per this statement, Modern Machine Learning algorithms are hungry for big data. Due to the small datasets, the researchers may not prefer to use Machine Learning algorithms. To tackle this issue, the main purpose of this survey is to illustrate, demonstrate related studies for significance of a semi-parametric Machine Learning framework called Grey Machine Learning (GML). This kind of framework is capable of handling large datasets as well as small datasets for time series forecasting likely outcomes. This survey presents a comprehensive overview of the existing semi-parametric machine learning techniques for time series forecasting. In this paper, a primer survey on the GML framework is provided for researchers. To allow an in-depth understanding for the readers, a brief description of Machine Learning, as well as various forms of conventional grey forecasting models are discussed. Moreover, a brief description on the importance of GML framework is presented.