 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Comparison of No-U-Turn Sampler Variants: Necessary and Su?cient Convergence Conditions and Mixing Time Analysis under Gaussian Targets
Mar 19, 2026The No-U-Turn Sampler (NUTS) is the computational workhorse of modern Bayesian software libraries, yet its qualitative and quantitative convergence guarantees were established only recently. A significant gap remains in the theoretical comparison of its two main variants: NUTS-mul and NUTS-BPS, which use multinomial sampling and biased progressive sampling, respectively, for index selection. In this paper, we address this gap in three contributions. First, we derive the first necessary conditions for geometric ergodicity for both variants. Second, we establish the first sufficient conditions for geometric ergodicity and ergodicity for NUTS-mul. Third, we obtain the first mixing time result for NUTS-BPS on a standard Gaussian distribution. Our results show that NUTS-mul and NUTS-BPS exhibit nearly identical qualitative behavior, with geometric ergodicity depending on the tail properties of the target distribution. However, they differ quantitatively in their convergence rates. More precisely, when initialized in the typical set of the canonical Gaussian measure, the mixing times of both NUTS-mul and NUTS-BPS scale as $O(d^{1/4})$ up to logarithmic factors, where $d$ denotes the dimension. Nevertheless, the associated constants are strictly smaller for NUTS-BPS.
Optimal Fair Aggregation of Crowdsourced Noisy Labels using Demographic Parity Constraints
Jan 30, 2026As acquiring reliable ground-truth labels is usually costly, or infeasible, crowdsourcing and aggregation of noisy human annotations is the typical resort. Aggregating subjective labels, though, may amplify individual biases, particularly regarding sensitive features, raising fairness concerns. Nonetheless, fairness in crowdsourced aggregation remains largely unexplored, with no existing convergence guarantees and only limited post-processing approaches for enforcing $\varepsilon$-fairness under demographic parity. We address this gap by analyzing the fairness s of crowdsourced aggregation methods within the $\varepsilon$-fairness framework, for Majority Vote and Optimal Bayesian aggregation. In the small-crowd regime, we derive an upper bound on the fairness gap of Majority Vote in terms of the fairness gaps of the individual annotators. We further show that the fairness gap of the aggregated consensus converges exponentially fast to that of the ground-truth under interpretable conditions. Since ground-truth itself may still be unfair, we generalize a state-of-the-art multiclass fairness post-processing algorithm from the continuous to the discrete setting, which enforces strict demographic parity constraints to any aggregation rule. Experiments on synthetic and real datasets demonstrate the effectiveness of our approach and corroborate the theoretical insights.
Personalized Convolutional Dictionary Learning of Physiological Time Series
Mar 10, 2025Human physiological signals tend to exhibit both global and local structures: the former are shared across a population, while the latter reflect inter-individual variability. For instance, kinetic measurements of the gait cycle during locomotion present common characteristics, although idiosyncrasies may be observed due to biomechanical disposition or pathology. To better represent datasets with local-global structure, this work extends Convolutional Dictionary Learning (CDL), a popular method for learning interpretable representations, or dictionaries, of time-series data. In particular, we propose Personalized CDL (PerCDL), in which a local dictionary models local information as a personalized spatiotemporal transformation of a global dictionary. The transformation is learnable and can combine operations such as time warping and rotation. Formal computational and statistical guarantees for PerCDL are provided and its effectiveness on synthetic and real human locomotion data is demonstrated.
Riemannian Metric Learning: Closer to You than You Imagine
Mar 07, 2025



Riemannian metric learning is an emerging field in machine learning, unlocking new ways to encode complex data structures beyond traditional distance metric learning. While classical approaches rely on global distances in Euclidean space, they often fall short in capturing intrinsic data geometry. Enter Riemannian metric learning: a powerful generalization that leverages differential geometry to model the data according to their underlying Riemannian manifold. This approach has demonstrated remarkable success across diverse domains, from causal inference and optimal transport to generative modeling and representation learning. In this review, we bridge the gap between classical metric learning and Riemannian geometry, providing a structured and accessible overview of key methods, applications, and recent advances. We argue that Riemannian metric learning is not merely a technical refinement but a fundamental shift in how we think about data representations. Thus, this review should serve as a valuable resource for researchers and practitioners interested in exploring Riemannian metric learning and convince them that it is closer to them than they might imagine-both in theory and in practice.
Stochastic Approximation with Biased MCMC for Expectation Maximization
Feb 27, 2024


The expectation maximization (EM) algorithm is a widespread method for empirical Bayesian inference, but its expectation step (E-step) is often intractable. Employing a stochastic approximation scheme with Markov chain Monte Carlo (MCMC) can circumvent this issue, resulting in an algorithm known as MCMC-SAEM. While theoretical guarantees for MCMC-SAEM have previously been established, these results are restricted to the case where asymptotically unbiased MCMC algorithms are used. In practice, MCMC-SAEM is often run with asymptotically biased MCMC, for which the consequences are theoretically less understood. In this work, we fill this gap by analyzing the asymptotics and non-asymptotics of SAEM with biased MCMC steps, particularly the effect of bias. We also provide numerical experiments comparing the Metropolis-adjusted Langevin algorithm (MALA), which is asymptotically unbiased, and the unadjusted Langevin algorithm (ULA), which is asymptotically biased, on synthetic and real datasets. Experimental results show that ULA is more stable with respect to the choice of Langevin stepsize and can sometimes result in faster convergence.
On the convergence of dynamic implementations of Hamiltonian Monte Carlo and No U-Turn Samplers
Jul 07, 2023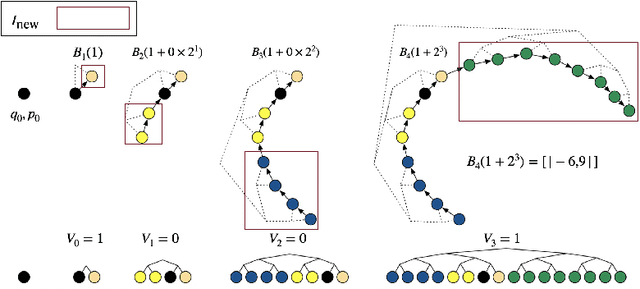
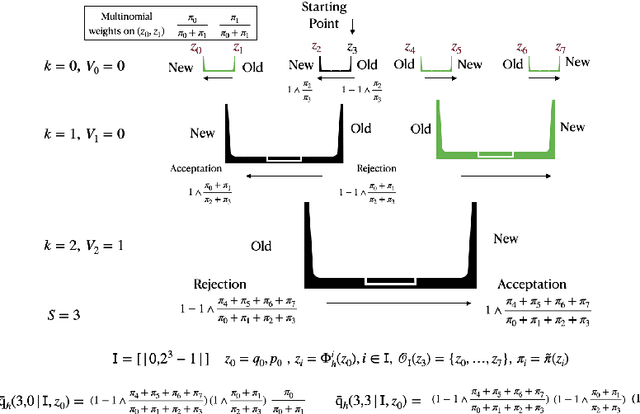
There is substantial empirical evidence about the success of dynamic implementations of Hamiltonian Monte Carlo (HMC), such as the No U-Turn Sampler (NUTS), in many challenging inference problems but theoretical results about their behavior are scarce. The aim of this paper is to fill this gap. More precisely, we consider a general class of MCMC algorithms we call dynamic HMC. We show that this general framework encompasses NUTS as a particular case, implying the invariance of the target distribution as a by-product. Second, we establish conditions under which NUTS is irreducible and aperiodic and as a corrolary ergodic. Under conditions similar to the ones existing for HMC, we also show that NUTS is geometrically ergodic. Finally, we improve existing convergence results for HMC showing that this method is ergodic without any boundedness condition on the stepsize and the number of leapfrog steps, in the case where the target is a perturbation of a Gaussian distribution.