 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Paper and Code


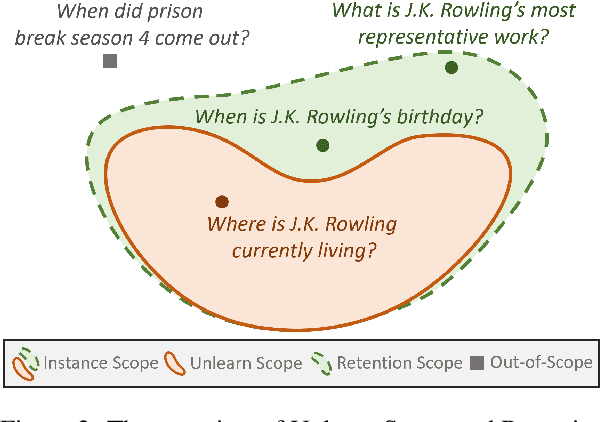

Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.