 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Exploration Through Instruction Enhancement for Object Navigation
Nov 15, 2022



Finding an object of a specific class in an unseen environment remains an unsolved navigation problem. Hence, we propose a hierarchical learning-based method for object navigation. The top-level is capable of high-level planning, and building a memory on a floorplan-level (e.g., which room makes the most sense for the agent to visit next, where has the agent already been?). While the lower-level is tasked with efficiently navigating between rooms and looking for objects in them. Instructions can be provided to the agent using a simple synthetic language. The top-level intelligently enhances the instructions in order to make the overall task more tractable. Language grounding, mapping instructions to visual observations, is performed by utilizing an additional separate supervised trained goal assessment module. We demonstrate the effectiveness of our method on a dynamic configurable domestic environment.
Pre-trained Word Embeddings for Goal-conditional Transfer Learning in Reinforcement Learning
Jul 10, 2020

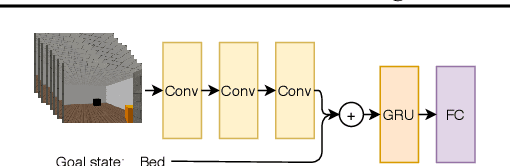
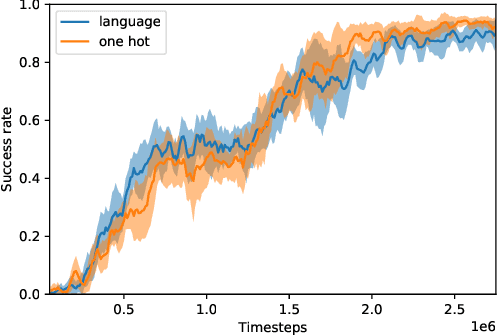
Reinforcement learning (RL) algorithms typically start tabula rasa, without any prior knowledge of the environment, and without any prior skills. This however often leads to low sample efficiency, requiring a large amount of interaction with the environment. This is especially true in a lifelong learning setting, in which the agent needs to continually extend its capabilities. In this paper, we examine how a pre-trained task-independent language model can make a goal-conditional RL agent more sample efficient. We do this by facilitating transfer learning between different related tasks. We experimentally demonstrate our approach on a set of object navigation tasks.
Fast Task-Adaptation for Tasks Labeled Using Natural Language in Reinforcement Learning
Oct 09, 2019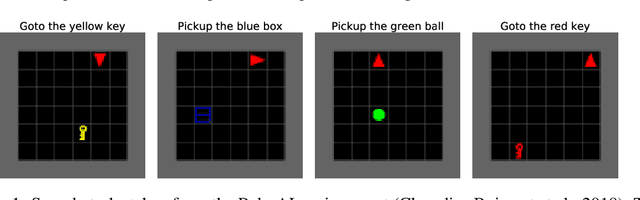


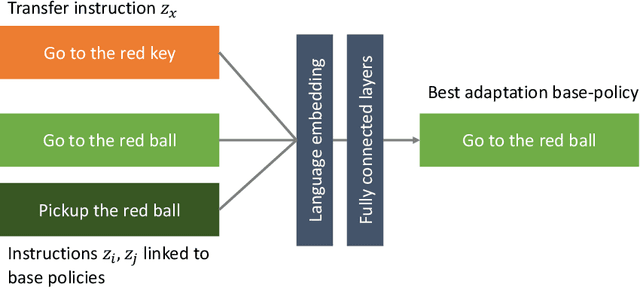
Over its lifetime, a reinforcement learning agent is often tasked with different tasks. How to efficiently adapt a previously learned control policy from one task to another, remains an open research question. In this paper, we investigate how instructions formulated in natural language can enable faster and more effective task adaptation. This can serve as the basis for developing language instructed skills, which can be used in a lifelong learning setting. Our method is capable of assessing, given a set of developed base control policies, which policy will adapt best to a new unseen task.