 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHTMRL: Biologically Plausible Reinforcement Learning with Hierarchical Temporal Memory
Paper and Code
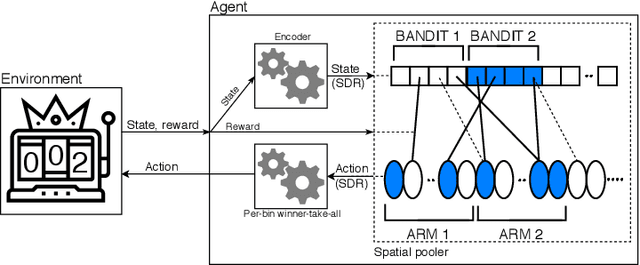
Building Reinforcement Learning (RL) algorithms which are able to adapt to continuously evolving tasks is an open research challenge. One technology that is known to inherently handle such non-stationary input patterns well is Hierarchical Temporal Memory (HTM), a general and biologically plausible computational model for the human neocortex. As the RL paradigm is inspired by human learning, HTM is a natural framework for an RL algorithm supporting non-stationary environments. In this paper, we present HTMRL, the first strictly HTM-based RL algorithm. We empirically and statistically show that HTMRL scales to many states and actions, and demonstrate that HTM's ability for adapting to changing patterns extends to RL. Specifically, HTMRL performs well on a 10-armed bandit after 750 steps, but only needs a third of that to adapt to the bandit suddenly shuffling its arms. HTMRL is the first iteration of a novel RL approach, with the potential of extending to a capable algorithm for Meta-RL.