 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Encoding Framework for Binarized Images using HyperDimensional Computing
Dec 01, 2023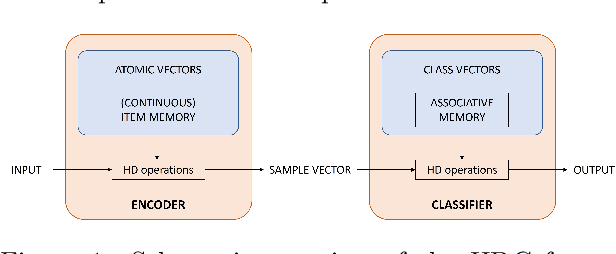



Hyperdimensional Computing (HDC) is a brain-inspired and light-weight machine learning method. It has received significant attention in the literature as a candidate to be applied in the wearable internet of things, near-sensor artificial intelligence applications and on-device processing. HDC is computationally less complex than traditional deep learning algorithms and typically achieves moderate to good classification performance. A key aspect that determines the performance of HDC is the encoding of the input data to the hyperdimensional (HD) space. This article proposes a novel light-weight approach relying only on native HD arithmetic vector operations to encode binarized images that preserves similarity of patterns at nearby locations by using point of interest selection and local linear mapping. The method reaches an accuracy of 97.35% on the test set for the MNIST data set and 84.12% for the Fashion-MNIST data set. These results outperform other studies using baseline HDC with different encoding approaches and are on par with more complex hybrid HDC models. The proposed encoding approach also demonstrates a higher robustness to noise and blur compared to the baseline encoding.
Training a HyperDimensional Computing Classifier using a Threshold on its Confidence
May 30, 2023Hyperdimensional computing (HDC) has become popular for light-weight and energy-efficient machine learning, suitable for wearable Internet-of-Things (IoT) devices and near-sensor or on-device processing. HDC is computationally less complex than traditional deep learning algorithms and achieves moderate to good classification performance. This article proposes to extend the training procedure in HDC by taking into account not only wrongly classified samples, but also samples that are correctly classified by the HDC model but with low confidence. As such, a confidence threshold is introduced that can be tuned for each dataset to achieve the best classification accuracy. The proposed training procedure is tested on UCIHAR, CTG, ISOLET and HAND dataset for which the performance consistently improves compared to the baseline across a range of confidence threshold values. The extended training procedure also results in a shift towards higher confidence values of the correctly classified samples making the classifier not only more accurate but also more confident about its predictions.