 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData selection method for assessment of autonomous vehicles
Paper and Code
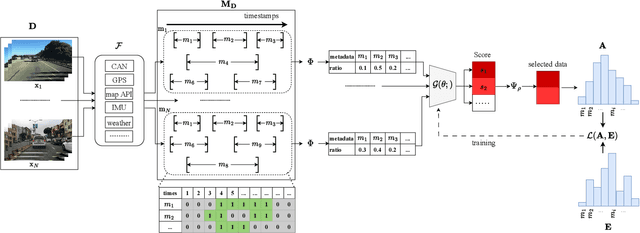
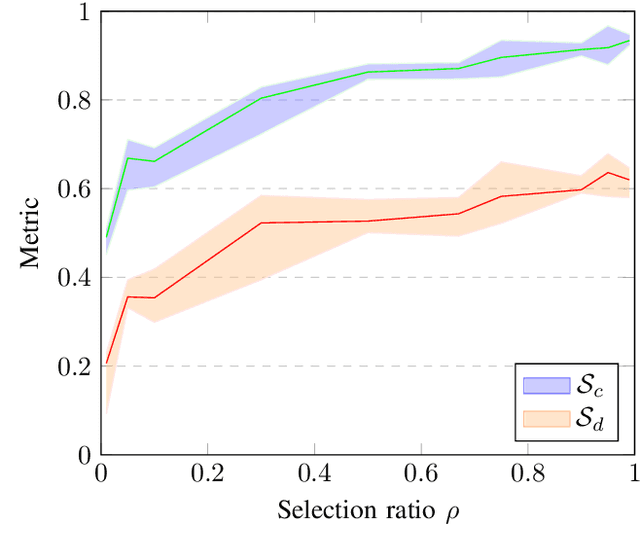

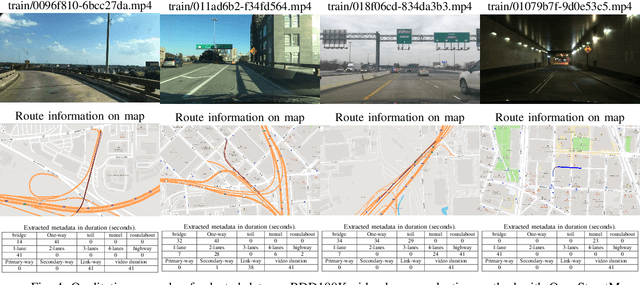
As the popularity of autonomous vehicles has grown, many standards and regulators, such as ISO, NHTSA, and Euro NCAP, require safety validation to ensure a sufficient level of safety before deploying them in the real world. Manufacturers gather a large amount of public road data for this purpose. However, the majority of these validation activities are done manually by humans. Furthermore, the data used to validate each driving feature may differ. As a result, it is essential to have an efficient data selection method that can be used flexibly and dynamically for verification and validation while also accelerating the validation process. In this paper, we present a data selection method that is practical, flexible, and efficient for assessment of autonomous vehicles. Our idea is to optimize the similarity between the metadata distribution of the selected data and a predefined metadata distribution that is expected for validation. Our experiments on the large dataset BDD100K show that our method can perform data selection tasks efficiently. These results demonstrate that our methods are highly reliable and can be used to select appropriate data for the validation of various safety functions.