 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoQuery: Geometry-Query Diffusion for Sparse-View Reconstruction
May 12, 20263D Gaussian Splatting (3DGS) has emerged as a prominent paradigm for 3D reconstruction and novel view synthesis. However, it remains vulnerable to severe artifacts when trained under sparse-view constraints. While recent methods attempt to rectify artifacts in rendered views using image diffusion models, they typically rely on multi-view self-attention to retrieve information from reference images. We observe that this mechanism often fails when the rendered novel views output by 3DGS are heavily corrupted: damaged query features lead to erroneous cross-view retrieval, resulting in inconsistent rendering refinement. To address this, we propose GeoQuery, a geometry-guided diffusion framework that integrates generative priors with explicit geometric cues via a novel Geometry-guided Cross-view Attention (GCA) mechanism. First, by leveraging predicted depth maps and camera poses, we construct a geometry-induced correspondence field to sample reference features, forming a geometry-aligned proxy query that replaces the corrupted rendering features. Furthermore, we design a new cross-view feature aggregation pipeline, in which we restrict the cross-view attention to a local window around each proxy query to effectively retrieve useful features while suppressing spurious matches. GeoQuery can be seamlessly integrated into existing diffusion-based pipelines, enabling robust reconstruction even under extreme view sparsity. Extensive experiments on sparse-view novel view synthesis and rendering artifact removal demonstrate the effectiveness of our approach.
UAU-Net: Uncertainty-aware Representation Learning and Evidential Classification for Facial Action Unit Detection
Apr 23, 2026Facial action unit (AU) detection remains challenging because it involves heterogeneous, AU-specific uncertainties arising at both the representation and decision stages. Recent methods have improved discriminative feature learning, but they often treat the AU representations as deterministic, overlooking uncertainty caused by visual noise, subject-dependent appearance variations, and ambiguous inter-AU relationships, all of which can substantially degrade robustness. Meanwhile, conventional point-estimation classifiers often provide poorly calibrated confidence, producing overconfident predictions, especially under the severe label imbalance typical of AU datasets. We propose UAU-Net, an Uncertainty-aware AU detection framework that explicitly models uncertainty at both stages. At the representation stage, we introduce CV-AFE, a conditional VAE (CVAE)-based AU feature extraction module that learns probabilistic AU representations by jointly estimating feature means and variances across multiple spatio-temporal scales; conditioning on AU labels further enables CV-AFE to capture uncertainty associated with inter-AU dependencies. At the decision stage, we design AB-ENN, an Asymmetric Beta Evidential Neural Network for multi-label AU detection, which parameterizes predictive uncertainty with Beta distributions and mitigates overconfidence via an asymmetric loss tailored to highly imbalanced binary labels. Extensive experiments on BP4D and DISFA show that UAU-Net achieves strong AU detection performance, and further analyses indicate that modeling uncertainty in both representation learning and evidential prediction improves robustness and reliability.
Let Your Image Move with Your Motion! -- Implicit Multi-Object Multi-Motion Transfer
Mar 01, 2026Motion transfer has emerged as a promising direction for controllable video generation, yet existing methods largely focus on single-object scenarios and struggle when multiple objects require distinct motion patterns. In this work, we present FlexiMMT, the first implicit image-to-video (I2V) motion transfer framework that explicitly enables multi-object, multi-motion transfer. Given a static multi-object image and multiple reference videos, FlexiMMT independently extracts motion representations and accurately assigns them to different objects, supporting flexible recombination and arbitrary motion-to-object mappings. To address the core challenge of cross-object motion entanglement, we introduce a Motion Decoupled Mask Attention Mechanism that uses object-specific masks to constrain attention, ensuring that motion and text tokens only influence their designated regions. We further propose a Differentiated Mask Propagation Mechanism that derives object-specific masks directly from diffusion attention and progressively propagates them across frames efficiently. Extensive experiments demonstrate that FlexiMMT achieves precise, compositional, and state-of-the-art performance in I2V-based multi-object multi-motion transfer.
Just ClozE! A Fast and Simple Method for Evaluating the Factual Consistency in Abstractive Summarization
Oct 06, 2022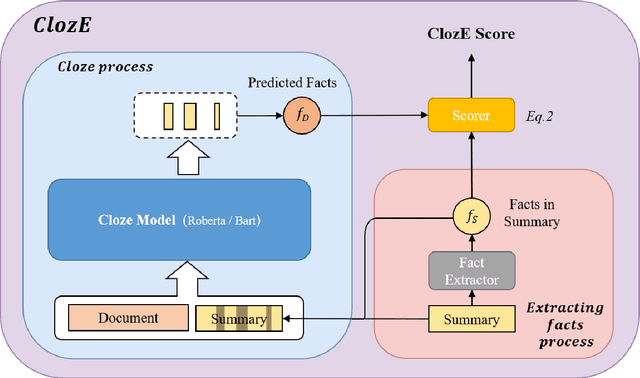
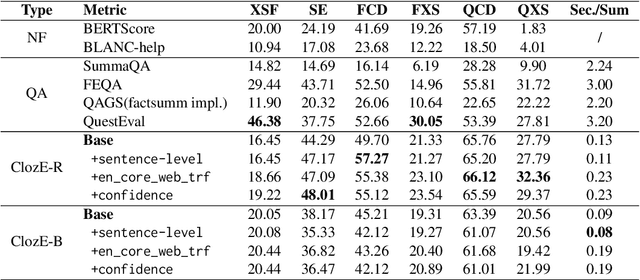
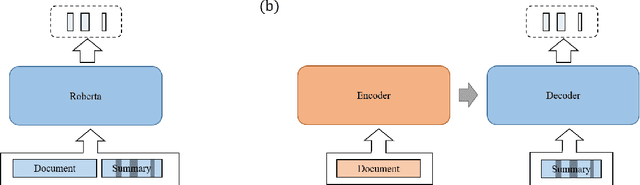

The issue of factual consistency in abstractive summarization has attracted much attention in recent years, and the evaluation of factual consistency between summary and document has become an important and urgent task. Most of the current evaluation metrics are adopted from the question answering (QA). However, the application of QA-based metrics is extremely time-consuming in practice, causing the iteration cycle of abstractive summarization research to be severely prolonged. In this paper, we propose a new method called ClozE to evaluate factual consistency by cloze model, instantiated based on masked language model(MLM), with strong interpretability and substantially higher speed. We demonstrate that ClozE can reduce the evaluation time by nearly 96$\%$ relative to QA-based metrics while retaining their interpretability and performance through experiments on six human-annotated datasets and a meta-evaluation benchmark GO FIGURE \citep{gabriel2020go}. We also implement experiments to further demonstrate more characteristics of ClozE in terms of performance and speed. In addition, we conduct an experimental analysis of the limitations of ClozE, which suggests future research directions. The code and models for ClozE will be released upon the paper acceptance.
A Distributed and Elastic Aggregation Service for Scalable Federated Learning Systems
Apr 16, 2022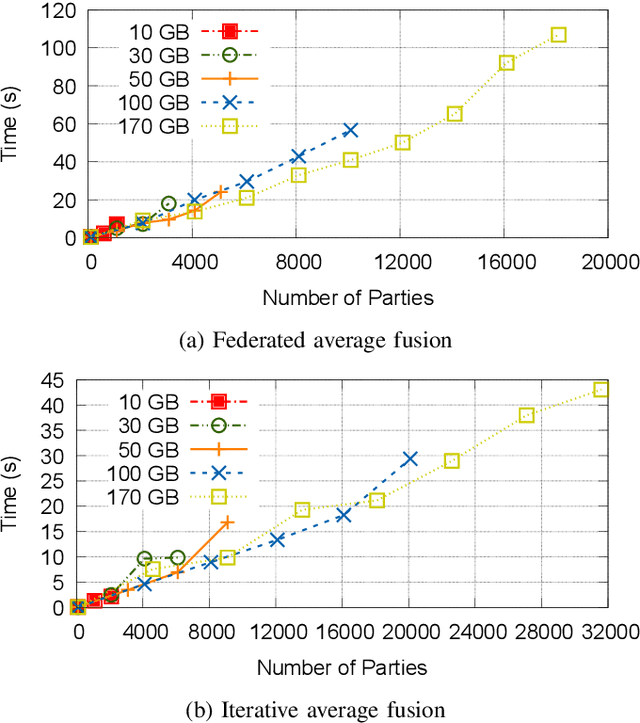
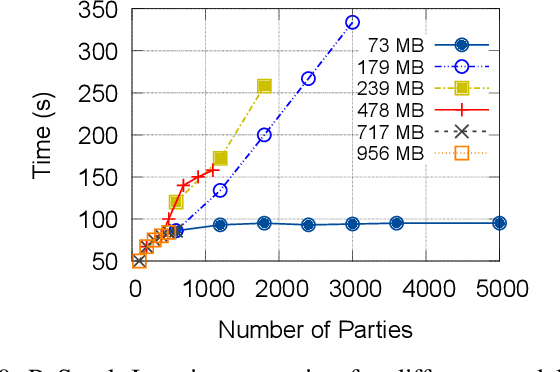
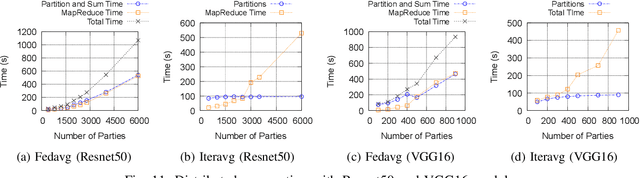
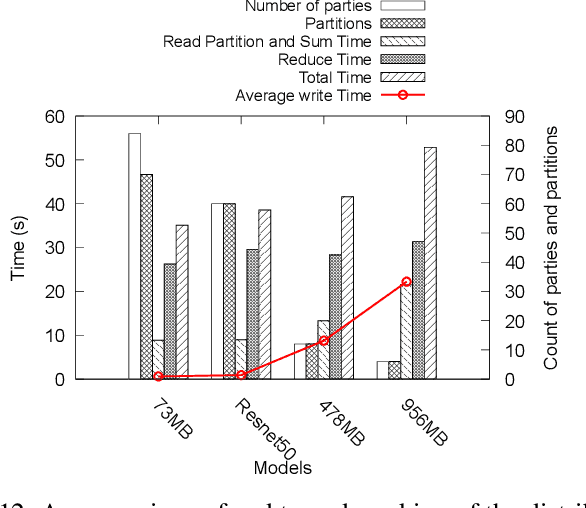
Federated Learning has promised a new approach to resolve the challenges in machine learning by bringing computation to the data. The popularity of the approach has led to rapid progress in the algorithmic aspects and the emergence of systems capable of simulating Federated Learning. State of art systems in Federated Learning support a single node aggregator that is insufficient to train a large corpus of devices or train larger-sized models. As the model size or the number of devices increase the single node aggregator incurs memory and computation burden while performing fusion tasks. It also faces communication bottlenecks when a large number of model updates are sent to a single node. We classify the workload for the aggregator into categories and propose a new aggregation service for handling each load. Our aggregation service is based on a holistic approach that chooses the best solution depending on the model update size and the number of clients. Our system provides a fault-tolerant, robust and efficient aggregation solution utilizing existing parallel and distributed frameworks. Through evaluation, we show the shortcomings of the state of art approaches and how a single solution is not suitable for all aggregation requirements. We also provide a comparison of current frameworks with our system through extensive experiments.