 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Unlearning for Vision Transformers
Feb 23, 2026Research in machine unlearning (MU) has gained strong momentum: MU is now widely regarded as a critical capability for building safe and fair AI. In parallel, research into transformer architectures for computer vision tasks has been highly successful: Increasingly, Vision Transformers (VTs) emerge as strong alternatives to CNNs. Yet, MU research for vision tasks has largely centered on CNNs, not VTs. While benchmarking MU efforts have addressed LLMs, diffusion models, and CNNs, none exist for VTs. This work is the first to attempt this, benchmarking MU algorithm performance in different VT families (ViT and Swin-T) and at different capacities. The work employs (i) different datasets, selected to assess the impacts of dataset scale and complexity; (ii) different MU algorithms, selected to represent fundamentally different approaches for MU; and (iii) both single-shot and continual unlearning protocols. Additionally, it focuses on benchmarking MU algorithms that leverage training data memorization, since leveraging memorization has been recently discovered to significantly improve the performance of previously SOTA algorithms. En route, the work characterizes how VTs memorize training data relative to CNNs, and assesses the impact of different memorization proxies on performance. The benchmark uses unified evaluation metrics that capture two complementary notions of forget quality along with accuracy on unseen (test) data and on retained data. Overall, this work offers a benchmarking basis, enabling reproducible, fair, and comprehensive comparisons of existing (and future) MU algorithms on VTs. And, for the first time, it sheds light on how well existing algorithms work in VT settings, establishing a promising reference performance baseline.
Localising Shortcut Learning in Pixel Space via Ordinal Scoring Correlations for Attribution Representations (OSCAR)
Dec 21, 2025

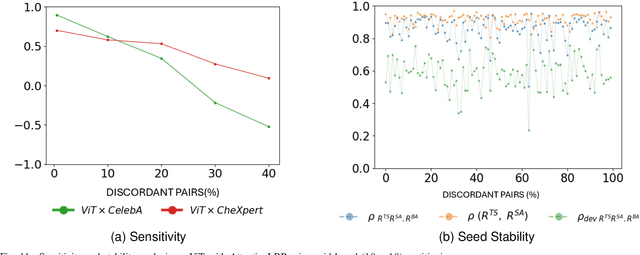

Deep neural networks often exploit shortcuts. These are spurious cues which are associated with output labels in the training data but are unrelated to task semantics. When the shortcut features are associated with sensitive attributes, shortcut learning can lead to biased model performance. Existing methods for localising and understanding shortcut learning are mostly based upon qualitative, image-level inspection and assume cues are human-visible, limiting their use in domains such as medical imaging. We introduce OSCAR (Ordinal Scoring Correlations for Attribution Representations), a model-agnostic framework for quantifying shortcut learning and localising shortcut features. OSCAR converts image-level task attribution maps into dataset-level rank profiles of image regions and compares them across three models: a balanced baseline model (BA), a test model (TS), and a sensitive attribute predictor (SA). By computing pairwise, partial, and deviation-based correlations on these rank profiles, we produce a set of quantitative metrics that characterise the degree of shortcut reliance for TS, together with a ranking of image-level regions that contribute most to it. Experiments on CelebA, CheXpert, and ADNI show that our correlations are (i) stable across seeds and partitions, (ii) sensitive to the level of association between shortcut features and output labels in the training data, and (iii) able to distinguish localised from diffuse shortcut features. As an illustration of the utility of our method, we show how worst-group performance disparities can be reduced using a simple test-time attenuation approach based on the identified shortcut regions. OSCAR provides a lightweight, pixel-space audit that yields statistical decision rules and spatial maps, enabling users to test, localise, and mitigate shortcut reliance. The code is available at https://github.com/acharaakshit/oscar
Scalability of memorization-based machine unlearning
Oct 21, 2024



Machine unlearning (MUL) focuses on removing the influence of specific subsets of data (such as noisy, poisoned, or privacy-sensitive data) from pretrained models. MUL methods typically rely on specialized forms of fine-tuning. Recent research has shown that data memorization is a key characteristic defining the difficulty of MUL. As a result, novel memorization-based unlearning methods have been developed, demonstrating exceptional performance with respect to unlearning quality, while maintaining high performance for model utility. Alas, these methods depend on knowing the memorization scores of data points and computing said scores is a notoriously time-consuming process. This in turn severely limits the scalability of these solutions and their practical impact for real-world applications. In this work, we tackle these scalability challenges of state-of-the-art memorization-based MUL algorithms using a series of memorization-score proxies. We first analyze the profiles of various proxies and then evaluate the performance of state-of-the-art (memorization-based) MUL algorithms in terms of both accuracy and privacy preservation. Our empirical results show that these proxies can introduce accuracy on par with full memorization-based unlearning while dramatically improving scalability. We view this work as an important step toward scalable and efficient machine unlearning.
Are we making progress in unlearning? Findings from the first NeurIPS unlearning competition
Jun 13, 2024



We present the findings of the first NeurIPS competition on unlearning, which sought to stimulate the development of novel algorithms and initiate discussions on formal and robust evaluation methodologies. The competition was highly successful: nearly 1,200 teams from across the world participated, and a wealth of novel, imaginative solutions with different characteristics were contributed. In this paper, we analyze top solutions and delve into discussions on benchmarking unlearning, which itself is a research problem. The evaluation methodology we developed for the competition measures forgetting quality according to a formal notion of unlearning, while incorporating model utility for a holistic evaluation. We analyze the effectiveness of different instantiations of this evaluation framework vis-a-vis the associated compute cost, and discuss implications for standardizing evaluation. We find that the ranking of leading methods remains stable under several variations of this framework, pointing to avenues for reducing the cost of evaluation. Overall, our findings indicate progress in unlearning, with top-performing competition entries surpassing existing algorithms under our evaluation framework. We analyze trade-offs made by different algorithms and strengths or weaknesses in terms of generalizability to new datasets, paving the way for advancing both benchmarking and algorithm development in this important area.
What makes unlearning hard and what to do about it
Jun 03, 2024Machine unlearning is the problem of removing the effect of a subset of training data (the ''forget set'') from a trained model without damaging the model's utility e.g. to comply with users' requests to delete their data, or remove mislabeled, poisoned or otherwise problematic data. With unlearning research still being at its infancy, many fundamental open questions exist: Are there interpretable characteristics of forget sets that substantially affect the difficulty of the problem? How do these characteristics affect different state-of-the-art algorithms? With this paper, we present the first investigation aiming to answer these questions. We identify two key factors affecting unlearning difficulty and the performance of unlearning algorithms. Evaluation on forget sets that isolate these identified factors reveals previously-unknown behaviours of state-of-the-art algorithms that don't materialize on random forget sets. Based on our insights, we develop a framework coined Refined-Unlearning Meta-algorithm (RUM) that encompasses: (i) refining the forget set into homogenized subsets, according to different characteristics; and (ii) a meta-algorithm that employs existing algorithms to unlearn each subset and finally delivers a model that has unlearned the overall forget set. We find that RUM substantially improves top-performing unlearning algorithms. Overall, we view our work as an important step in (i) deepening our scientific understanding of unlearning and (ii) revealing new pathways to improving the state-of-the-art.
To Each Its Own: Improving Memorized-Data Unlearning in Large Language Models
May 06, 2024



LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
Towards Unbounded Machine Unlearning
Feb 20, 2023Deep machine unlearning is the problem of removing the influence of a cohort of data from the weights of a trained deep model. This challenge is enjoying increasing attention due to the widespread use of neural networks in applications involving user data: allowing users to exercise their `right to be forgotten' necessitates an effective unlearning algorithm. However, deleting data from models is also of interest in practice for other applications where individual user privacy is not necessarily a consideration: removing biases, out-of-date examples, outliers, or noisy labels, and different such applications come with different desiderata. We propose a new unlearning algorithm (coined SCRUB) and conduct a comprehensive experimental evaluation against several previous state-of-the-art models. The results reveal that SCRUB is consistently a top performer across three different metrics for measuring unlearning quality, reflecting different application scenarios, while not degrading the model's performance.
Detect, Distill and Update: Learned DB Systems Facing Out of Distribution Data
Oct 11, 2022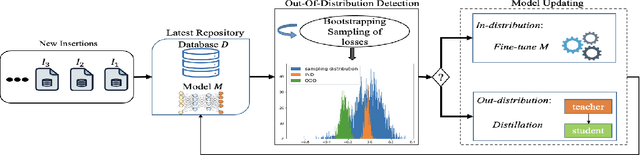
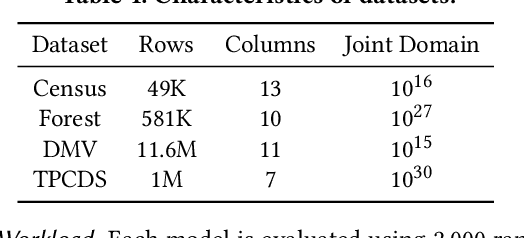
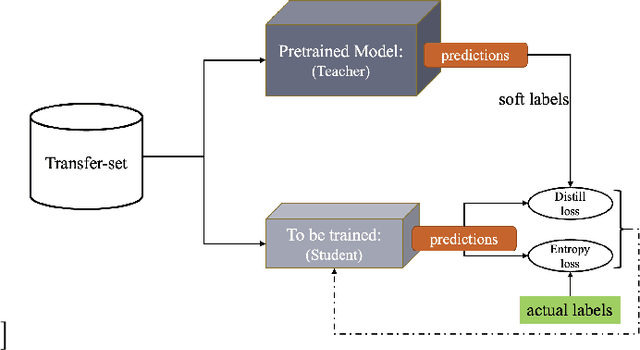
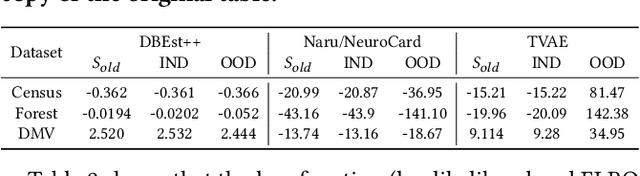
Machine Learning (ML) is changing DBs as many DB components are being replaced by ML models. One open problem in this setting is how to update such ML models in the presence of data updates. We start this investigation focusing on data insertions (dominating updates in analytical DBs). We study how to update neural network (NN) models when new data follows a different distribution (a.k.a. it is "out-of-distribution" -- OOD), rendering previously-trained NNs inaccurate. A requirement in our problem setting is that learned DB components should ensure high accuracy for tasks on old and new data (e.g., for approximate query processing (AQP), cardinality estimation (CE), synthetic data generation (DG), etc.). This paper proposes a novel updatability framework (DDUp). DDUp can provide updatability for different learned DB system components, even based on different NNs, without the high costs to retrain the NNs from scratch. DDUp entails two components: First, a novel, efficient, and principled statistical-testing approach to detect OOD data. Second, a novel model updating approach, grounded on the principles of transfer learning with knowledge distillation, to update learned models efficiently, while still ensuring high accuracy. We develop and showcase DDUp's applicability for three different learned DB components, AQP, CE, and DG, each employing a different type of NN. Detailed experimental evaluation using real and benchmark datasets for AQP, CE, and DG detail DDUp's performance advantages.
Graphical Join: A New Physical Join Algorithm for RDBMSs
Jun 22, 2022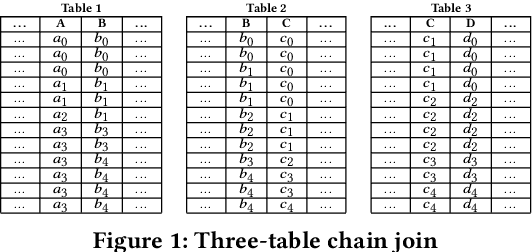

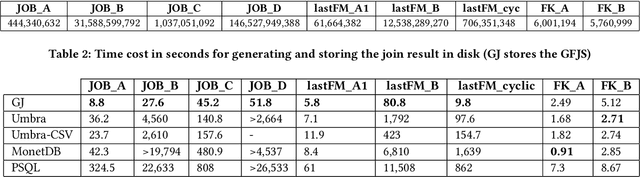
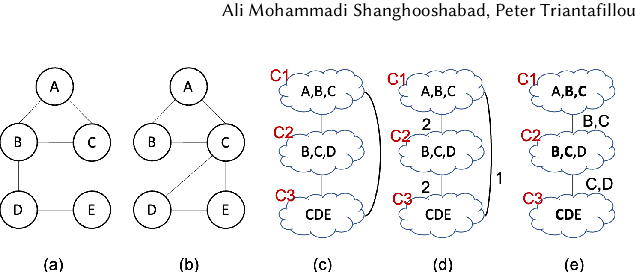
Join operations (especially n-way, many-to-many joins) are known to be time- and resource-consuming. At large scales, with respect to table and join-result sizes, current state of the art approaches (including both binary-join plans which use Nested-loop/Hash/Sort-merge Join algorithms or, alternatively, worst-case optimal join algorithms (WOJAs)), may even fail to produce any answer given reasonable resource and time constraints. In this work, we introduce a new approach for n-way equi-join processing, the Graphical Join (GJ). The key idea is two-fold: First, to map the physical join computation problem to PGMs and introduce tweaked inference algorithms which can compute a Run-Length Encoding (RLE) based join-result summary, entailing all statistics necessary to materialize the join result. Second, and most importantly, to show that a join algorithm, like GJ, which produces the above join-result summary and then desummarizes it, can introduce large performance benefits in time and space. Comprehensive experimentation is undertaken with join queries from the JOB, TPCDS, and lastFM datasets, comparing GJ against PostgresQL and MonetDB and a state of the art WOJA implemented within the Umbra system. The results for in-memory join computation show performance improvements up to 64X, 388X, and 6X faster than PostgreSQL, MonetDB and Umbra, respectively. For on-disk join computation, GJ is faster than PostgreSQL, MonetDB and Umbra by up to 820X, 717X and 165X, respectively. Furthermore, GJ space needs are up to 21,488X, 38,333X, and 78,750X smaller than PostgresQL, MonetDB, and Umbra, respectively.
Model Joins: Enabling Analytics Over Joins of Absent Big Tables
Jun 21, 2022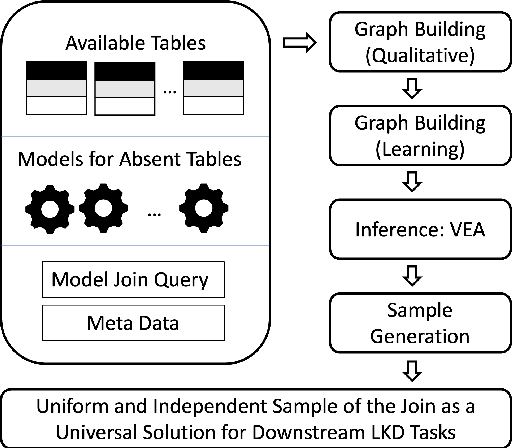
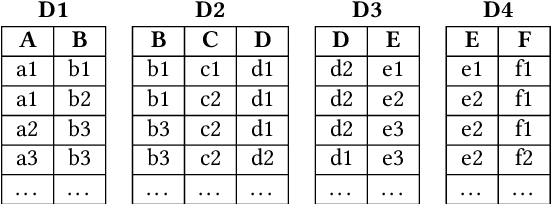
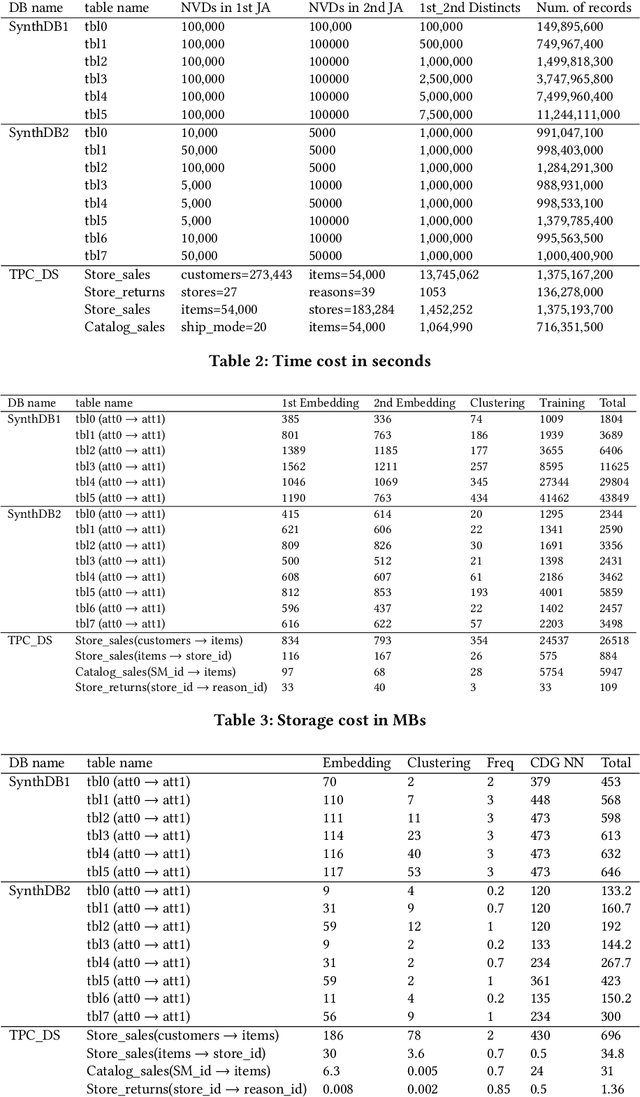
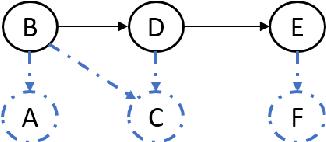
This work is motivated by two key facts. First, it is highly desirable to be able to learn and perform knowledge discovery and analytics (LKD) tasks without the need to access raw-data tables. This may be due to organizations finding it increasingly frustrating and costly to manage and maintain ever-growing tables, or for privacy reasons. Hence, compact models can be developed from the raw data and used instead of the tables. Second, oftentimes, LKD tasks are to be performed on a (potentially very large) table which is itself the result of joining separate (potentially very large) relational tables. But how can one do this, when the individual to-be-joined tables are absent? Here, we pose the following fundamental questions: Q1: How can one "join models" of (absent/deleted) tables or "join models with other tables" in a way that enables LKD as if it were performed on the join of the actual raw tables? Q2: What are appropriate models to use per table? Q3: As the model join would be an approximation of the actual data join, how can one evaluate the quality of the model join result? This work puts forth a framework, Model Join, addressing these challenges. The framework integrates and joins the per-table models of the absent tables and generates a uniform and independent sample that is a high-quality approximation of a uniform and independent sample of the actual raw-data join. The approximation stems from the models, but not from the Model Join framework. The sample obtained by the Model Join can be used to perform LKD downstream tasks, such as approximate query processing, classification, clustering, regression, association rule mining, visualization, and so on. To our knowledge, this is the first work with this agenda and solutions. Detailed experiments with TPC-DS data and synthetic data showcase Model Join's usefulness.