 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, Distill and Update: Learned DB Systems Facing Out of Distribution Data
Paper and Code
Oct 11, 2022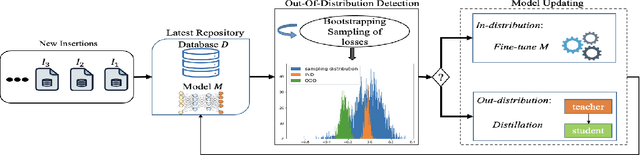
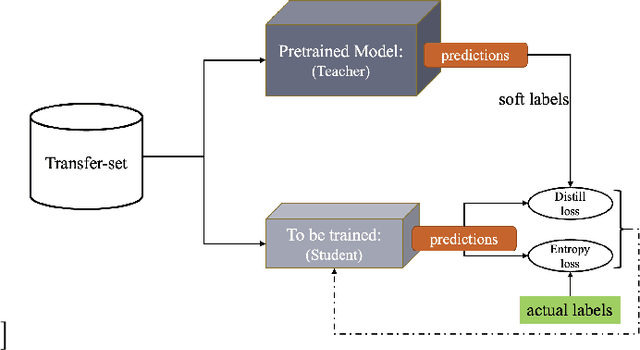
Machine Learning (ML) is changing DBs as many DB components are being replaced by ML models. One open problem in this setting is how to update such ML models in the presence of data updates. We start this investigation focusing on data insertions (dominating updates in analytical DBs). We study how to update neural network (NN) models when new data follows a different distribution (a.k.a. it is "out-of-distribution" -- OOD), rendering previously-trained NNs inaccurate. A requirement in our problem setting is that learned DB components should ensure high accuracy for tasks on old and new data (e.g., for approximate query processing (AQP), cardinality estimation (CE), synthetic data generation (DG), etc.). This paper proposes a novel updatability framework (DDUp). DDUp can provide updatability for different learned DB system components, even based on different NNs, without the high costs to retrain the NNs from scratch. DDUp entails two components: First, a novel, efficient, and principled statistical-testing approach to detect OOD data. Second, a novel model updating approach, grounded on the principles of transfer learning with knowledge distillation, to update learned models efficiently, while still ensuring high accuracy. We develop and showcase DDUp's applicability for three different learned DB components, AQP, CE, and DG, each employing a different type of NN. Detailed experimental evaluation using real and benchmark datasets for AQP, CE, and DG detail DDUp's performance advantages.